




 本文详细介绍了如何使用SQL的window函数(如rank())、查找连续记录、行偏移和CTE递归等技术,解决好友数量统计、连续失败记录筛选、工序优化及数据结构查询等问题。
本文详细介绍了如何使用SQL的window函数(如rank())、查找连续记录、行偏移和CTE递归等技术,解决好友数量统计、连续失败记录筛选、工序优化及数据结构查询等问题。
一、 rank()窗口函数
create table F0225
(
requester_id int,
accepter_id int,
accept_date date
);
insert into F0225 values
(1,2,'2016-06-03'),
(1,3,'2016-06-08'),
(2,3,'2016-06-08'),
(3,4,'2016-06-09');
--求出好友数最多的ID及其好友数量
select t.ids id, count(*) count
from (
select requester_id ids from F0225
union all
select accepter_id ids from F0225
) t
group by t.ids
order by count(*) desc
limit 1
存在并列第一的情况
create table F0225
(
requester_id int,
accepter_id int,
accept_date date
);
insert into F0225 values
(1,5,'2016-06-03'),
(1,3,'2016-06-08'),
(2,1,'2016-06-08'),
(3,4,'2016-06-09'),
(3,5,'2016-06-09');
select *
from (
select ids, `count`, rank() over(order by `count` desc) `rank`
from (
select t.ids , count(*) count
from (
select requester_id ids from F0225
union all
select accepter_id ids from F0225
) t
group by t.ids
) t1
) t2
where `rank` = 1
二、 查找连续记录行
create table F0228
(
id int,
times int,
result varchar(10)
);
insert into F0228 values
(1,34,'败'),
(3,35,'胜'),
(5,36,'胜'),
(8,37,'败'),
(9,38,'败'),
(11,39,'败'),
(12,40,'败'),
(15,41,'胜'),
(17,42,'胜'),
(20,43,'败'),
(21,44,'败'),
(23,45,'败'),
(24,46,'败');
--查询出连续失败场次大于3的记录行
-- 创建表表达式CTEA,给表添加虚列进行排序
with CTEA as (
select *,ROW_NUMBER() OVER(ORDER BY times) num1
from F0228
),
-- 继续创建表表达式CTEB,通过对上一步CTEA中的数据结果进行分组
-- 对场次进行排序后,用上一步中的虚列减去排序后的结果
CTEB as (
select *,
ROW_NUMBER() OVER(PARTITION BY result ORDER by times) x1,
num1 - ROW_NUMBER() OVER(PARTITION BY result ORDER by times) num2
from CTEA
)
select id, times, result
from CTEB
where num2 in (
select num2
from CTEB
group by num2
having count(1) >= 4
)
三、行偏移函数
create table F0303
(
id int comment '工序',
dept_id int comment '部门编号',
cnt int comment '完成数量'
);
insert into F0303 values
(10,222,1500),
(20,223,1497),
(30,223,1499),
(40,223,1498),
(50,213,1497),
(60,224,1497),
(70,224,1497),
(80,220,1496),
(90,220,1496),
(100,224,0);
-- 按工序排序,相邻的行,如果有部门相同的情况,取工序好最大的那一行记录
-- 行偏移窗口函数:LEAD(被偏移的列,向后偏移行数,超出分区返回的默认值) OVER()
-- 行偏移窗口函数:LAG(被偏移的列,向前偏移行数,超出分区返回的默认值) OVER()
select id, dept_id, cnt
from (
select *,
LEAD(dept_id, 1, NULL) OVER(ORDER BY id) nextDept
from F0303
) t
where dept_id != nextDept or nextDept is NULL
四、CTE递归
create table F0307
(
id int,
productName varchar(64),
parentId int
);
insert into F0307 values
(1, '汽车', NULL),
(2, '车身', 1),
(3, '发动机', 1),
(4, '车门', 2),
(5, '驾驶舱', 2),
(6, '行李舱', 2),
(7, '气缸', 3),
(8, '活塞', 3);c
-- 根据父id来逐级显示产品名和层级序号
/*
递归:
1. 初始查询,形成CTE结构的基本结果集。初始查询部分称为锚成员。
2. 递归查询部分是引用CTE名称的查询,因此,它被称为递归成员。递归成员由UNION ALL或UNION DISTINCT运算符与锚成员连接。
3. 终止条件,确保递归成员不返回任何行时停止递归。
*/
with recursive CTE AS
(
select id, parentId, productName,0 AS 'CTELEVEL', cast(id as char(10)) AS 'ORDERID'
from F0307
where id = 1
union all
SELECT A.id, a.parentId, a.productName, B.CTELEVEL + 1, cast(concat(concat(B.ORDERID, '->'),LTRIM(A.id)) as char(10)) as 'ORDERID'
from F0307 A
join CTE B on B.id = A.parentId
)
select id, parentId, concat(RIGHT(' ', 4 * CTELEVEL),productName) productName, ORDERID
from CTE
ORDER BY ORDERID
五、相邻两行时间差
create table F0308
(
user_id int,
times datetime
);
insert into F0308 values
(1, '2021-12-07 21:13:07'),
(1, '2021-12-07 21:15:26'),
(1, '2021-12-07 21:17:44'),
(2, '2021-12-13 21:14:06'),
(2, '2021-12-13 21:18:19'),
(2, '2021-12-13 21:20:36'),
(3, '2021-12-21 21:16:51'),
(4, '2021-12-16 22:22:08'),
(4, '2021-12-02 21:17:22'),
(4, '2021-12-30 15:15:44'),
(4, '2021-12-30 15:17:57');
-- 求每个用户相邻两次浏览时间之差小于三分钟的次数
方案一:
select t.user_id, count(*)
from (
select *, lead(times, 1, NULL) over(partition by user_id order by times) nextTime
from F0308
) t
where ABS(TIMESTAMPDIFF(MINUTE, t.times, t.nextTime)) < 3
group by t.user_id
方案二:
-- 1. 先给用户分组按时间进行排序,得到一个表表达式来当临时表
WITH t AS (
select user_id, times, ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY times) rn
from F0308
group by user_id, times
)
-- 3. 对结果进行判断,时间差小于3分钟的用户进行分组计数即可
select a.user_id, sum(case WHEN a.cn < 3 THEN 1 ELSE 0 END) cnt
from (
-- 2. 对表表达式使用自连接,进行错位相减,求出上下两行的时间差
select a.user_id, ABS(TIMESTAMPDIFF(MINUTE, IFNULL(a.times, '1970-01-01 00:00:00'),IFNULL(b.times, '1970-01-01 00:00:00'))) cn
from t a
left join t b on a.rn = b.rn + 1
and a.user_id = b.user_id
) a
group by a.user_id
六、 求解中位数
create table F0309
(
id int,
company varchar(10),
salary int
);
insert into F0309 values
(1, 'A', 10000),
(2, 'A', 9000),
(3, 'A', 11000),
(4, 'A', 8000),
(5, 'B', 12000),
(6, 'B', 13000),
(7, 'B', 14000),
(8, 'C', 12000),
(9, 'C', 9000),
(10, 'C', 9000),
(11, 'C', 11000);
-- 每个员工薪资的中位数
select company, sum(salary) / count(1) median
from (
select *,
row_number() over(partition by company order by salary) rnk,
count(*) over(partition by company) num
from F0309
) t
where (
-- 奇数情况:取中间
(num % 2 = 1 and rnk = floor(num / 2) + 1)
or
-- 偶数情况:取中间两个数
(num % 2 = 0 and (rnk = floor(num / 2) or rnk = floor(num / 2) + 1))
)
group by company
七、求解循环累加
create table F0316
(
id int,
num int
);
insert into F0316 values
(1, 5),
(2, 3),
(3, 12),
(4, 2),
(5, 7),
(6, 9);
-- 将num每行的值累加到下一行形成新的结果行
方案一:窗口函数
select *, sum(num) over( order by id) result
from F0316
方案二:自连接
select a.id, a.num, sum(b.num) result
from F0316 a
join F0316 b
on a.id >= b.id
group by a.id, a.num
八、 case when
create table F0321
(
id varchar(10),
name varchar(10),
sex varchar(1),
type varchar(10),
date date
);
insert into F0321 values
('1001', '张三', '男', '普通', '2021-08-03'),
('1002', '李四', '女', '管理', '2021-08-18'),
('1003', '王五', '男', '普通', '2021-08-19'),
('1004', '赵六', '女', '管理', '2021-08-04');
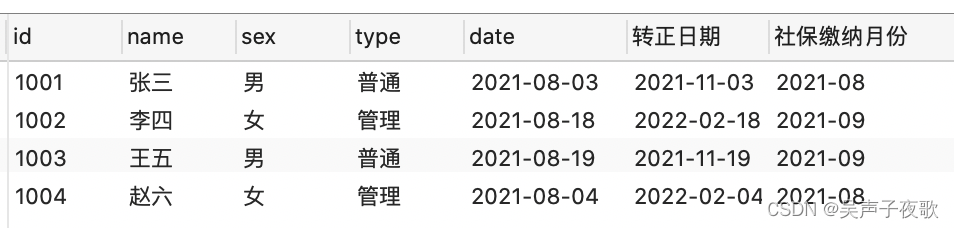
/*
1.
如果员工的类别是【普通】,则该员工的转正日期为【入职日期】后三个月
如果员工的类别是【管理】,则该员工的转正日期为【入职日期】后六个月
2.
如果员工的【入职日期】是当月15号前(含15号),则该员工的【社保缴纳月份】为【入职日期】的当月
如果员工的【入职日期】是当月15号后,则该员工的【社保缴纳月份】为【入职日期】的次月
要求:添加【转正日期】、【社保缴纳月份】列
*/
select
*,
(case type when '普通' then date_add(date, INTERVAL 3 MONTH)
when '管理' then date_add(date, INTERVAL 6 MONTH) END ) as '转正日期',
(case when substr(date,9,2) <= '15' then substr(date, 1, 7)
else substr(date_add(date, INTERVAL 1 MONTH), 1, 7) END ) as '社保缴纳月份'
from F0321
九、 拉链表问题
create table F0324
(
userid int,
operation varchar(10),
date date
);
insert into F0324 values
(1001, '创建订单', '2021/1/1'),
(1001, '支付订单', '2021/1/2'),
(1001, '确认订单', '2021/1/5'),
(1002, '创建订单', '2021/1/1'),
(1002, '支付订单', '2021/1/3'),
(1003, '创建订单', '2021/1/2');
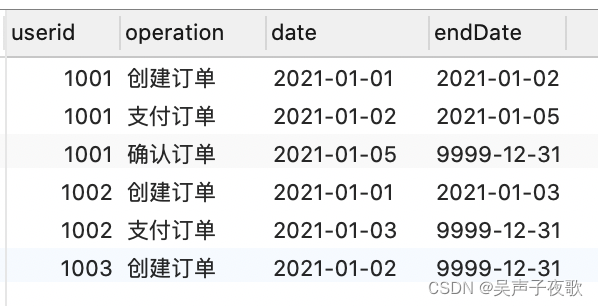
/*
要求:生成一张拉链表
拉链表:同一个userid,date从小到大排序后,每个操作日期作为开始时间,操作日期的下一个日期作为结束日期。
例如:userid为1001组,第一个日期是2021-01-01,第二个日期是2021-01-02,那么第一个日期2021-01-01的结束日期就是2021-01-02,以此类推,如果是最后一个日期,那么结束日期默认为9999-12-31
*/
select *, lead(date, 1, '9999-12-31') over(partition by userid order by date) 'endDate'
from F0324

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









