



 随着大数据时代的到来,企业对大数据人才的需求激增,但人才培养滞后导致严重的人才缺口。大数据工程师作为稀缺资源,其职业路径清晰且薪资极具竞争力,从实习工程师到首席工程师,薪资可达50K以上。然而,成为大数据工程师需要掌握复杂的技术技能,如Spark、Hadoop等,这些技能在国内外知名互联网公司中广泛应用。
随着大数据时代的到来,企业对大数据人才的需求激增,但人才培养滞后导致严重的人才缺口。大数据工程师作为稀缺资源,其职业路径清晰且薪资极具竞争力,从实习工程师到首席工程师,薪资可达50K以上。然而,成为大数据工程师需要掌握复杂的技术技能,如Spark、Hadoop等,这些技能在国内外知名互联网公司中广泛应用。
“不参与大数据建设,10年后一定后悔”。早在几年前,马云就在某次峰会中提到,未来30年,是从IT时代到DT时代的变革。
大数据发展态势
从上世纪60年代到现在,我们对数据的处理能力越来越强,概括起来,主要经历了四个阶段:从数据处理时代到微机时代,再到互联网络时代,现如今是大数据时代,量变引发形态变化。

有这样一句话叫数据重构商业,流量改变未来。数据作为企业的核心资产,对企业的业务创新发展越来越重要,企业也非常重视大数据人才的培养。
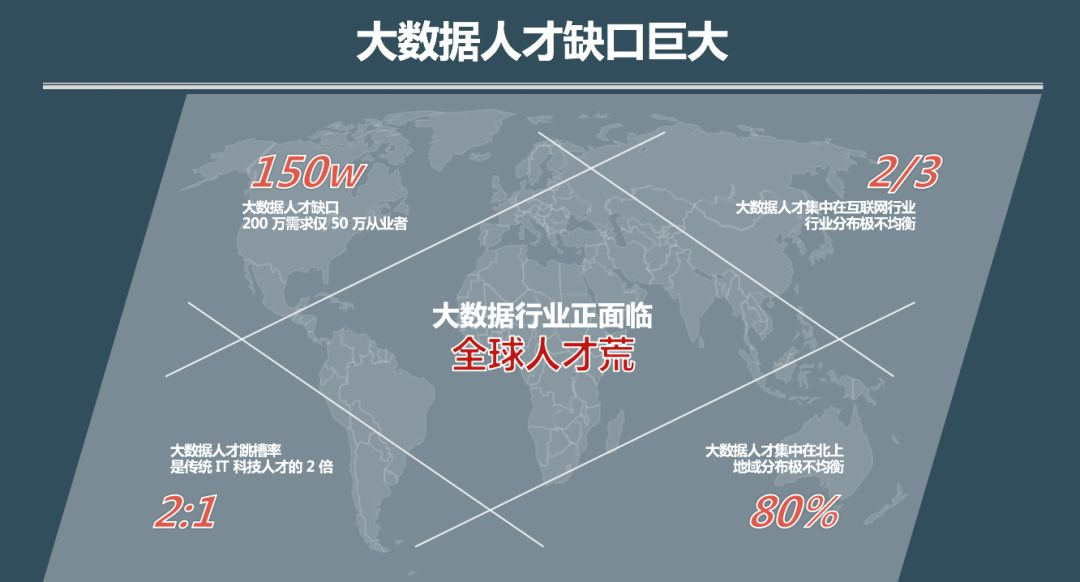
大数据人才缺口巨大
信息技术的高速发展与高校人才培养之间的矛盾日异突出,导致大数据人才的缺口巨大,从四个维度来分析:
1、据国内知名企业调查发现,目前大数据人才需求在200万左右,而大数据人才从业者才50万左右,整体大数据人才缺口在150万;
2、大数据人才集中在互联网行业,占了2/3,行业分布极不均衡;
3、大数据人才集中在北京、上海等发达区域,区域分布级不均衡;
4、大数据人才跳槽率是传统IT科技人才的2倍,因为稀缺,物依稀为贵。
所以学习大数据开发,是非常急迫的事情,抓住机遇,努力拼搏,必有成就。
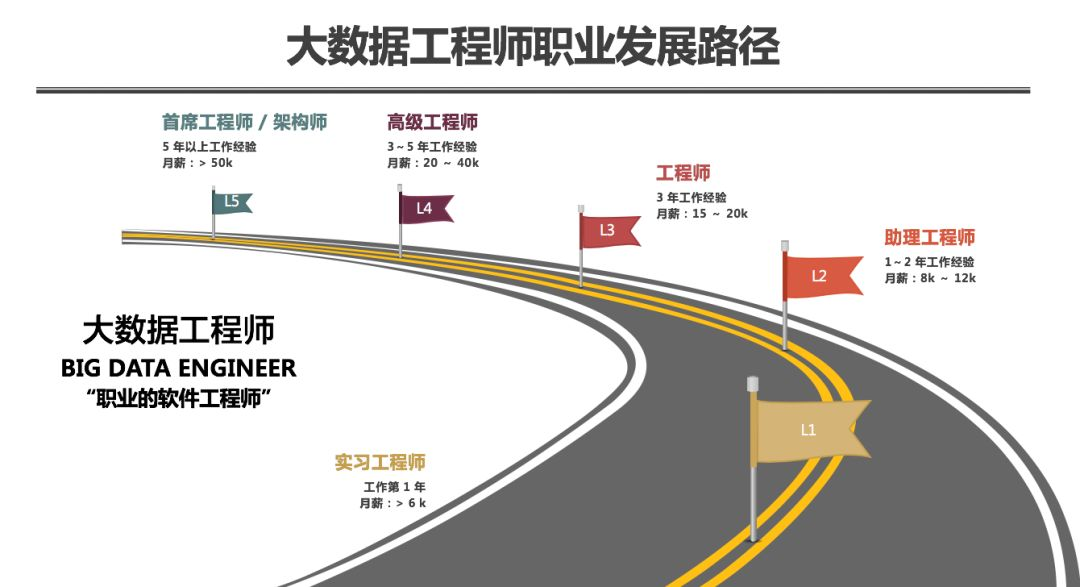
大数据工程师职业发展路径
大数据工程师职业发展路径分为5个阶段,每个阶段对应职位和薪水是不一样的:
第一阶段
实习工程师,工作第一年,月薪大于6K;
第二阶段:
助理工程师,有1-2年工作经验,月薪8K-12K;
第三阶段:
初、中级工程师,3年工作经验,月薪15-20K;
第四阶段:
高级工程师3-5年工作经验,月薪20-40K;
第五阶段:
首席工程师/架构师,月薪大于50K;
这个薪水非常的有竞争力,这也是为什么这么多学生要学习大数据开发技术。
作为大数据岗位中的 “大熊猫”,大数据工程师的收入待遇可以说达到了同类的顶级。
大数据开发工程师技能图谱
作为人少钱多的高薪岗位,大数据开发工程师需要掌握的技能图谱也是非常有挑战性的。如果做成思维导图的话,大概是这个样子:

(思维导图原文件,扫码后即可领取)
目前,无论是Facebook, Twitter, Google, 百度,腾讯,阿里,网易,这些国内外知名的互联网巨头公司,还是国内处于成长期的小公司,都在使用Spark。
Spark主要的业务场景包括:数据ETL处理、数据仓库建设、流式计算、欺诈检测、风险评估、图关系建设和分析、机器学习等。
当然,有了思维导图后,还需要辅以资料以及大牛的指导!这里还为你准备了免费的大数据专题讲解直播和全面的学习资料!
3.10-3.12 晚上8点免费看
专题直播视频包含:
1、使用HUE玩转大数据可视化
1 | 业务场景,通过使用Hue组件,让操作大数据不在困难 |
2 | 工具介绍,Hue图形化工具箱安装和配置 |
3 | 利用Hue快速操作HDFS等大数据组件 |
2、使用Pig玩转大数据ETL
1 | 业务场景,通过使用Pig组件,快速创建大数据业务流 |
2 | 工具介绍,Pig工具的安装和配置 |
3 | 利用Pig工具快速搭建企业数据业务流 |
3、大数据实时计算引擎Storm
1 | 什么是实时计算?大数据的离线计算和实时计算 |
2 | Storm的体系架构 |
3 | Demo演示:使用Storm执行WordCount Storm的数据处理流程 |
那么怎么免费看呢?
高清导图 &直播视频 & 重磅资料库
扫码免费领取!

扫码二维码,免费领取

回复“大数据”,快速通过

















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









