






 本文提供了一个如何在HBase上运行MapReduce作业的教程,涵盖了从版本0.20及以后的更新。通过使用HBase提供的方便的MapReduce类,实现了对用户ID的计数。首先,介绍了如何设置代码和HBase环境,然后通过示例展示了如何填充测试数据到HBase表中,并详细解释了Map和Reduce函数的工作原理。最后,展示了如何将结果存储回HBase表中并打印友好的输出。
本文提供了一个如何在HBase上运行MapReduce作业的教程,涵盖了从版本0.20及以后的更新。通过使用HBase提供的方便的MapReduce类,实现了对用户ID的计数。首先,介绍了如何设置代码和HBase环境,然后通过示例展示了如何填充测试数据到HBase表中,并详细解释了Map和Reduce函数的工作原理。最后,展示了如何将结果存储回HBase表中并打印友好的输出。
This is a tutorial on how to run a map reduce job on Hbase. This covers version 0.20 and later.
Recommended Readings:
– Hbase home,
– Hbase map reduce Wiki
– Hbase Map Reduce Package
– Great intro to Hbase map reduce by George Lars
Version Difference
Hadoop map reduce API changed around v0.20. So did Hbase map reduce package.
– org.apache.hadoop.hbase.mapred : older API, pre v0.20
– org.apache.hadoop.hbase.mapreduce : newer API, post v0.20
We will be using the newer API.
Frequency Counter
For this tutorial lets say our Hbase has records of web_access_logs. We record each web page access by a user. To keep things simple, we are only logging the user_id and the page they visit. You can imagine all sorts of stats can be gathered, such as ip_address, referer_paget ..etc
The schema looks like this:
userID_timestamp => {
details => {
page:
}
}
To make row-key unique, we have in a timestamp at the end making up a composite key.
So a sample setup data might looke like this:
| row | details:page |
| user1_t1 | a.html |
| user2_t2 | b.html |
| user3_t4 | a.html |
| user1_t5 | c.html |
| user1_t6 | b.html |
| user2_t7 | c.html |
| user4_t8 | a.html |
we want to count how many times we have seen each user. The result we want is:
| user | count (frequency) |
| user1 | 3 |
| user2 | 2 |
| user3 | 1 |
| user4 | 1 |
So we will write a map reduce program. Similar to the popular example word-count - couple of differences. Our Input-Source is a Hbase table. Also output is sent to an Hbase table.
First, code access & Hbase setup
The code is in GIT repository at GitHub : http://github.com/sujee/hbase-mapreduce
You can get it by
git clone git://github.com/sujee/hbase-mapreduce.git
This is an Eclipse project. To compile it, define HBASE_HOME to point Hbase install directory.
Lets also setup our Hbase tables:
0) For map reduce to run Hadoop needs to know about Hbase classes. edit ‘hadoop/conf/hadoop-env.sh':
# Extra Java CLASSPATH elements. add hbae jars
export HADOOP_CLASSPATH=/hadoop/hbase/hbase-0.20.3.jar:/hadoop/hbase/hbase-0.20.3-test.jar:/hadoop/hbase/conf:/hadoop/hbase/lib/zookeeper-3.2.2.jar
Change this to reflect your Hbase installation.
instructions are here : (http://hadoop.apache.org/hbase/docs/r0.20.3/api/org/apache/hadoop/hbase/mapreduce/package-summary.html ) to modify Hbase configuration
1) restart Hadoop in pseodo-distributed (single server) mode
2) restart Hbase in psuedo-distributed (single server) mode.
3)
hbase shell
create 'access_logs', 'details'
create 'summary_user', {NAME=>'details', VERSIONS=>1}
‘access_logs’ is the table that has ‘raw’ logs and will serve as our Input Source for mapreduce. ‘summary_user’ table is where we will write out the final results.
Some Test Data …
So lets get some sample data into our tables. The ‘Importer1′ class will fill ‘access_logs’ with some sample data.
package hbase_mapred1;
import java.util.Random;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
/**
* writes random access logs into hbase table
*
* userID_count => {
* details => {
* page
* }
* }
*
* @author sujee ==at== sujee.net
*
*/
public class Importer1 {
public static void main(String[] args) throws Exception {
String [] pages = {"/", "/a.html", "/b.html", "/c.html"};
HBaseConfiguration hbaseConfig = new HBaseConfiguration();
HTable htable = new HTable(hbaseConfig, "access_logs");
htable.setAutoFlush(false);
htable.setWriteBufferSize(1024 * 1024 * 12);
int totalRecords = 100000;
int maxID = totalRecords / 1000;
Random rand = new Random();
System.out.println("importing " + totalRecords + " records ....");
for (int i=0; i < totalRecords; i++)
{
int userID = rand.nextInt(maxID) + 1;
byte [] rowkey = Bytes.add(Bytes.toBytes(userID), Bytes.toBytes(i));
String randomPage = pages[rand.nextInt(pages.length)];
Put put = new Put(rowkey);
put.add(Bytes.toBytes("details"), Bytes.toBytes("page"), Bytes.toBytes(randomPage));
htable.put(put);
}
htable.flushCommits();
htable.close();
System.out.println("done");
}
}
Go ahead and run ‘Importer1′ in Eclipse.
In hbase shell lets see how our data looks:
hbase(main):004:0> scan ‘access_logs’, {LIMIT => 5}
ROW COLUMN+CELL
\x00\x00\x00\x01\x00\x00\x00r column=details:page, timestamp=1269330405067, value=/
\x00\x00\x00\x01\x00\x00\x00\xE7 column=details:page, timestamp=1269330405068, value=/a.html
\x00\x00\x00\x01\x00\x00\x00\xFC column=details:page, timestamp=1269330405068, value=/a.html
\x00\x00\x00\x01\x00\x00\x01a column=details:page, timestamp=1269330405068, value=/b.html
\x00\x00\x00\x01\x00\x00\x02\xC6 column=details:page, timestamp=1269330405068, value=/a.html
5 row(s) in 0.0470 seconds
About Hbase Mapreduce
Lets take a minute and examine the Hbase map reduce classes.
Hadoop mapper can take in ( KEY1, VALUE1) and output (KEY2, VALUE2). The Reducer can take (KEY2, VALUE2) and output (KEY3, VALUE3).
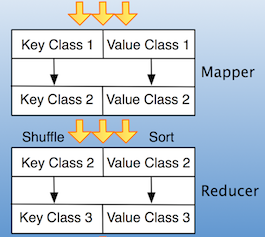
(image credit : http://www.larsgeorge.com/2009/05/hbase-mapreduce-101-part-i.html)
Hbase provides convenient Mapper & Reduce classes – org.apache.hadoop.hbase.mapreduce.TableMapper andorg.apache.hadoop.hbase.mapreduce.TableReduce. These classes extend Mapper and Reducer interfaces. They make it easier to read & write from/to Hbase tables


TableMapper:
Hbase TableMapper is an abstract class extending Hadoop Mapper.
The source can be found at : HBASE_HOME/src/java/org/apache/hadoop/hbase/mapreduce/TableMapper.java
package org.apache.hadoop.hbase.mapreduce;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.mapreduce.Mapper;
public abstract class TableMapper<KEYOUT, VALUEOUT>
extends Mapper<ImmutableBytesWritable, Result, KEYOUT, VALUEOUT> {
}
Notice how TableMapper parameterizes Mapper class.
| Param | class | comment |
| KEYIN (k1) | ImmutableBytesWritable | fixed. This is the row_key of the current row being processed |
| VALUEIN (v1) | Result | fixed. This is the value (result) of the row |
| KEYOUT (k2) | user specified | customizable |
| VALUEOUT (v2) | user specified | customizable |
The input key/value for TableMapper is fixed. We are free to customize output key/value classes. This is a noticeable difference compared to writing a straight hadoop mapper.
TableReducer
src : HBASE_HOME/src/java/org/apache/hadoop/hbase/mapreduce/TableReducer.java
package org.apache.hadoop.hbase.mapreduce;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Reducer;
public abstract class TableReducer<KEYIN, VALUEIN, KEYOUT>
extends Reducer<KEYIN, VALUEIN, KEYOUT, Writable> {
}
Lets look at the parameters:
| Param | Class | Comment |
| KEYIN (k2 – same as mapper keyout) | user-specified (same class as K2 ouput from mapper) | |
| VALUEIN(v2 – same as mapper valueout) | user-specified (same class as V2 ouput from mapper) | |
| KEYIN (k3) | user-specified | |
| VALUEOUT (k4) | must be Writable |
TableReducer can take any KEY2 / VALUE2 class and emit any KEY3 class, and a Writable VALUE4 class.
Back to Frequency Counting
We will extend TableMapper and TableReducer with our custom classes.
Mapper
| Input | Output |
| ImmutableBytesWritable (RowKey = userID + timestamp) | ImmutableBytesWritable (userID) |
| Result (Row Result) | IntWritable (always ONE) |
Reducer
| Input | Output |
| ImmutableBytesWritable (uesrID) (from output K2 from mapper) | ImmutableBytesWritable (userID : same as input) (this will be the KEYOUT k3. And it will serve as the ‘rowkey’ for output Hbase table) |
| Iterable<IntWriable> (all ONEs combined for this key) (from output V2 from mapper, all combined into a ‘list’ for this key) | IntWritable (total of all ONEs for this key) (this will be the VALUEOUT v3. And it will be PUT value for Hbase table) |
In mapper we extract the USERID from the composite rowkey (userID + timestamp). Then we just emit the userID and ONE – as in number ONE.
Visualizing Mapper output
(user1, 1)
(user2, 1)
(user1, 1)
(user3, 1)
The map-reduce framework, collects similar output keys together and send them to reducer. This is why we see a ‘list’ or ‘iterable’ for each userID key at reducer. In Reducer, we simply add all the values and emit <UserID , total Count>.
Visualizing Input to Reducer:
(user1, [1, 1])
(user2, [1])
(user3, [1])
And the output of reducer:
(user1, 2)
(user2, 1)
(user3, 1)
Ok, now onto the code.
Frequency Counter Map Reduce Code
package hbase_mapred1;
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.FirstKeyOnlyFilter;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
/**
* counts the number of userIDs
*
* @author sujee ==at== sujee.net
*
*/
public class FreqCounter1 {
static class Mapper1 extends TableMapper<ImmutableBytesWritable, IntWritable> {
private int numRecords = 0;
private static final IntWritable one = new IntWritable(1);
@Override
public void map(ImmutableBytesWritable row, Result values, Context context) throws IOException {
// extract userKey from the compositeKey (userId + counter)
ImmutableBytesWritable userKey = new ImmutableBytesWritable(row.get(), 0, Bytes.SIZEOF_INT);
try {
context.write(userKey, one);
} catch (InterruptedException e) {
throw new IOException(e);
}
numRecords++;
if ((numRecords % 10000) == 0) {
context.setStatus("mapper processed " + numRecords + " records so far");
}
}
}
public static class Reducer1 extends TableReducer<ImmutableBytesWritable, IntWritable, ImmutableBytesWritable> {
public void reduce(ImmutableBytesWritable key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
Put put = new Put(key.get());
put.add(Bytes.toBytes("details"), Bytes.toBytes("total"), Bytes.toBytes(sum));
System.out.println(String.format("stats : key : %d, count : %d", Bytes.toInt(key.get()), sum));
context.write(key, put);
}
}
public static void main(String[] args) throws Exception {
HBaseConfiguration conf = new HBaseConfiguration();
Job job = new Job(conf, "Hbase_FreqCounter1");
job.setJarByClass(FreqCounter1.class);
Scan scan = new Scan();
String columns = "details"; // comma seperated
scan.addColumns(columns);
scan.setFilter(new FirstKeyOnlyFilter());
TableMapReduceUtil.initTableMapperJob("access_logs", scan, Mapper1.class, ImmutableBytesWritable.class,
IntWritable.class, job);
TableMapReduceUtil.initTableReducerJob("summary_user", Reducer1.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Code Walk-through
- Since our mapper/reducer code is pretty compact, we have it all in one file
- At line 26 :
static class Mapper1 extends TableMapper<ImmutableBytesWritable, IntWritable> {we configure class type Emitted from mapper. Remember, map inputs are already defined for us by TableMapper (as ImmutableBytesWritable and Result)
- At line 34:
ImmutableBytesWritable userKey = new ImmutableBytesWritable(row.get(), 0, Bytes.SIZEOF_INT);we are extracting userID from the composite key (userID + timestamp = INT + INT). This will be the key that we will emit.
- at line 36:
context.write(userKey, one);Here is where we EMIT our output. Notice we always output ONE (which is IntWritable(1)).
- At line 46, we configure our reducer to accept the values emitted from the mapper (ImmutableBytessWriteable, IntWritable)
- line 52:
for (IntWritable val : values) { sum += val.get();we simply aggregate the count. Since each count is ONE, the sum is total is number values.
- At line 56:
Put put = new Put(key.get()); put.add(Bytes.toBytes("details"), Bytes.toBytes("total"), Bytes.toBytes(sum)); context.write(key, put);Here we see the familiar Hbase PUT being created. The key being used is USERID (passed on from mapper, and used unmodified here). The value is SUM. This PUT will be saved into our target Hbase Table (‘summary_user’).
Notice how ever, we don’t write directly to output table. This is done by super class ‘TableReducer’. - Finally, lets look at the job setup.
HBaseConfiguration conf = new HBaseConfiguration(); Job job = new Job(conf, "Hbase_FreqCounter1"); job.setJarByClass(FreqCounter1.class); Scan scan = new Scan(); String columns = "details"; // comma seperated scan.addColumns(columns); scan.setFilter(new FirstKeyOnlyFilter()); TableMapReduceUtil.initTableMapperJob("access_logs", scan, Mapper1.class, ImmutableBytesWritable.class, IntWritable.class, job); TableMapReduceUtil.initTableReducerJob("summary_user", Reducer1.class, job); System.exit(job.waitForCompletion(true) ? 0 : 1);We setup Hbase configuration, Job and Scanner. Optionally, we are also configuring the scanner on which columns to read. And using the ‘TableMapReduceUtil’ to setup mapper class.
TableMapReduceUtil.initTableMapperJob( "access_logs", // table to read data from scan, // scanner Mapper1.class, // map class ImmutableBytesWritable.class, // mapper output KEY class IntWritable.class, // mapper output VALUE class job // job );Similarly we setup Reducer
TableMapReduceUtil.initTableReducerJob( "summary_user", // table to write to Reducer1.class, // reducer class job); // job
Running the Job
Single Server mode
We can just run the code from Eclipse. Run ‘FreqCounter1′ from Eclipse. (You may need to up the memory for JVM using -Xmx300m in launch configurations).
Output looks like this:
...
10/04/09 15:08:32 INFO mapred.JobClient: map 0% reduce 0%
10/04/09 15:08:37 INFO mapred.LocalJobRunner: mapper processed 10000 records so far
10/04/09 15:08:40 INFO mapred.LocalJobRunner: mapper processed 30000 records so far
...
10/04/09 15:08:55 INFO mapred.JobClient: map 100% reduce 0%
...
stats : key : 1, count : 999
stats : key : 2, count : 1040
stats : key : 3, count : 986
stats : key : 4, count : 983
stats : key : 5, count : 967
...
10/04/09 15:08:56 INFO mapred.JobClient: map 100% reduce 100%
Alright… we see mapper progressing and then we see ‘frequency output’ from our Reducer! Neat !!
Running this on a Hbase cluster (multi machines)
For this we need to make a JAR file of our classes.
Open a terminal and navigate to the directory of the project.
jar cf freqCounter.jar -C classes .
This will create a jar file ‘freqCounter.jar’. Use this jar file with ‘hadoop jar’ command to launch the MR job
hadoop jar freqCounter.jar hbase_mapred1.FreqCounter1
You can track the progress of the job at task tracker : http://localhost:50030
Plus you can monitor the program output on the task-tracker website as well.
Checking The Result
Lets do a scan of results table
hbase(main):002:0> scan ‘summary_user’, {LIMIT => 5}
ROW COLUMN+CELL
\x00\x00\x00\x00 column=details:total, timestamp=1269330349590, value=\x00\x00\x04\x0A
\x00\x00\x00\x01 column=details:total, timestamp=1270856929004, value=\x00\x00\x03\xE7
\x00\x00\x00\x02 column=details:total, timestamp=1270856929004, value=\x00\x00\x04\x10
\x00\x00\x00\x03 column=details:total, timestamp=1270856929004, value=\x00\x00\x03\xDA
\x00\x00\x00\x04 column=details:total, timestamp=1270856929005, value=\x00\x00\x03\xD7
5 row(s) in 0.0750 seconds
ok, looks like we have our frequency count. But they are in all byte-display. Lets write a quick scanner to print out a more user friendly display
package hbase_mapred1;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
public class PrintUserCount {
public static void main(String[] args) throws Exception {
HBaseConfiguration conf = new HBaseConfiguration();
HTable htable = new HTable(conf, "summary_user");
Scan scan = new Scan();
ResultScanner scanner = htable.getScanner(scan);
Result r;
while (((r = scanner.next()) != null)) {
ImmutableBytesWritable b = r.getBytes();
byte[] key = r.getRow();
int userId = Bytes.toInt(key);
byte[] totalValue = r.getValue(Bytes.toBytes("details"), Bytes.toBytes("total"));
int count = Bytes.toInt(totalValue);
System.out.println("key: " + userId+ ", count: " + count);
}
scanner.close();
htable.close();
}
}
Running this will print out output like …
key: 0, count: 1034
key: 1, count: 999
key: 2, count: 1040
key: 3, count: 986
key: 4, count: 983
key: 5, count: 967
key: 6, count: 987
...
...
That’s it
thanks!

















 2万+
2万+


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








