




 提出BeautyGAN,一种基于深度生成对抗网络的面部彩妆转移方法,可在保留人脸特征的同时,将参考彩妆风格转移至非彩妆人脸。通过引入像素级直方图损失和知觉损失,实现高质量的彩妆转移效果。
提出BeautyGAN,一种基于深度生成对抗网络的面部彩妆转移方法,可在保留人脸特征的同时,将参考彩妆风格转移至非彩妆人脸。通过引入像素级直方图损失和知觉损失,实现高质量的彩妆转移效果。
BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network
BeautyGAN:基于深度生成对抗网络的实例级面部彩妆转移
摘要:
人脸彩妆转换的目的是在保留人脸特征的同时,将一个给定的参考彩妆人脸图像转换为另一个非彩妆人脸图像。这种实例级的传输问题比传统的域级传输任务更具挑战性,特别是当成对的数据不可用时。化妆风格也不同于全局风格(如绘画),它由几种局部风格/化妆品组成,包括眼影、口红、粉底等等。这种局部的、精细的化妆信息提取和传递,对于现有的风格传递方法是不可行的。我们通过将全局域级损失和本地实例级损失合并到一个称为BeautyGAN的双输入/输出生成对抗网络中来解决这个问题。具体地说,域级的传输是由鉴别器来保证的,这些鉴别器可以将生成的图像与域的实际样本区分开来。实例级损失由局部人脸区域的像素级直方图损失计算得到。我们进一步引入知觉损失和循环一致性损失来生成高质量的人脸和保持身份。整体目标功能使网络能够通过无监督的对抗性学习在实例级学习翻译。我们还建立了一个新的化妆数据集,包括3834高分辨率的人脸图像。大量的实验表明,BeautyGAN可以生成视觉愉悦的化妆脸和准确的转移效果。数据和代码可以从http://liusi-group.com/projects/BeautyGAN获得。
1. 介绍
化妆是一种无处不在的通过特殊的化妆品来改善一个人的面部外观的方式,如粉底掩盖面部缺陷,眼线,眼影和口红。成千上万的化妆品,从品牌、颜色、使用方式各异,如果没有专业的建议,很难找到适合自己的化妆风格。虚拟化妆应用是一个方便的工具,可以帮助用户从美图秀秀、TAAZ和DailyMakever1等照片中尝试化妆风格。然而,这些工具都需要用户手动交互,并且只提供一定数量的固定化妆风格。在日常生活中,名人总是穿着漂亮的化妆风格,这给了一些例子可以参考。彩妆转换为用户选择最合适的彩妆风格提供了一种有效的方式。如图1所示,化妆转移(我们方法的结果)可以在不改变人脸身份的情况下,将一个给定的参考人脸图像的化妆风格转换为另一个非化妆人脸。

现有的关于自动补妆转移的研究可分为两类:一类是传统的图像处理方法[11,19,29],如图像梯度编辑和基于物理的操作,另一类是基于深度学习的方法,通常基于深度神经网络[23]。图像处理方法通常是将图像分解成若干层(如人脸结构、颜色、皮肤),将参考人脸图像扭曲成非化妆人脸图像后,再将每一层图像进行传输。基于深度学习的方法[23]采用几个独立的网络分别处理每种化妆品。几乎所有以前的方法都是简单组合不同的组件来处理化妆风格,因此整体输出图像看起来不自然,组合的位置有人工合成迹象(见图4)。
图像到图像翻译最近的进展,如风格转移(8、9、13)表明,一个端到端的结构作用于整个图像能产生高质量的结果。然而,直接将这些技术应用到我们的任务中仍然是不可行的。面部彩妆转移有两个主要的特点,不同于以往的问题。1)化妆风格因人而异,需要实例化。相反,建立在生成对抗网络(GAN)基础上的典型的图像到图像的翻译方法[4,12,35]主要用于领域级的转移。例如,CycleGAN[35]实现了两个集合(例如马和斑马)之间的图像到图像的转换,强调域间差异而忽略域内差异。因此,在我们的问题中使用CycleGAN往往会生成一个平均域级别的样式,它在给定不同参考面时是不变的(参见图4)。具体来说,在传统的风格转移作品[8,9,13]中,风格一般是指笔触、色彩分布等全局性的绘画方式。相比之下,化妆风格更加精致,由眼影、口红、粉底等几种局部化妆品组成。每种化妆品代表一种完全不同的风格。因此,在保留各种化妆品的特定特性的同时,很难从整体上提取出化妆品的风格。
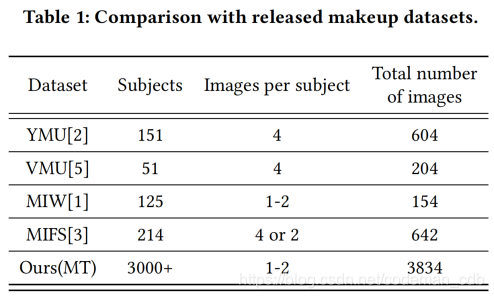
另一个关键问题是缺乏培训数据。一方面,已发布的彩妆数据集(见表1)太小,无法训练足够大的网络,且人脸彩妆图像大多分辨率/质量较低。另一方面,不同的化妆风格很难得到一副排列良好的人脸图像。因此,配对数据的监督学习也是不可信的。
针对以上问题,我们提出了一种新颖的双输入/输出生成对抗网络BeautyGAN,在统一的框架下实现化妆风格的转移。它接受化妆和非化妆的人脸作为输入,并直接输出传输的结果。不需要额外的预处理/后处理。与CycleGAN[35]类似,该网络首先通过几个识别器将非化妆人脸转移到化妆域,这些识别器可以将生成的图像与域的真实样本区分开来。在域级转移的基础上,采用基于不同人脸区域的像素级直方图损失来实现实例级转移。为了保持面部特征和消除伪影,我们还在整体目标函数中加入了感知缺失和循环一致性缺失。采用双输入/输出设计,只需一个生成器即可实现输入与输出的循环一致性,实现了化妆与反化妆同时进行的单次正向传递。此外,整个训练过程中不需要配对数据。如图1所示,生成的图像看起来很自然,并且没有观察到人工合成效果,在视觉上也很令人愉快。
综上所述,主要贡献有三方面:
- 利用双输入/输出生成的对抗性网络实现自动补妆转移。实验证明了该转移策略的有效性,所生成的结果比现有方法具有更高的质量。
- 通过在局部区域成功应用像素级直方图损失,实现了实例级风格的转移。这种实例级的转换方法可以很容易地推广到其他图像转换任务中,如头部人像的风格转换、图像属性转换等。
- 我们构建了一个新的化妆数据集,包含3834张图片,可以在http://liusi-group.com/projects/beautygan上找到。
2. 相关研究
2.1 化妆学习
近年来,化妆品相关的研究引起了越来越多的关注。[31]提出了一种基于位置约束字典学习的人脸卸妆检测框架。[20]引入了一个对抗网络来生成非化妆图像,以进行不变脸的验证。化妆转换是另一个吸引人的应用,它的目的是在保持源图像身份的同时,从参考图像转换化妆风格。[11]将图像分解为三层,逐层传递化妆信息。该方法可以平滑源图像的面部细节,因此[19]引入了另一种图像分解方法。以上的化妆品转移框架都是基于传统的方法,而[23]提出了一个本地化的化妆品转移框架,通过深度学习的方式。它将面部化妆分为几个部分,并对每个面部部分进行不同的方法。采用图像扭曲和结构保存的方法合成妆后图像。
与上述作品不同的是,我们的网络可以同时实现彩妆的转移和卸妆。同时,统一的培训流程可以考虑不同地区化妆品之间的关系。此外,端到端网络本身可以学习源图像中化妆品的适配,从而消除了后处理的需要。
2.2 风格转换
风格转换的目的是将不同图像的内容和风格结合起来。为了实现这一目标,[8]提出了一种通过最小化内容和样式重构损失来生成重构图像的方法。为了更好地控制颜色、尺度、空间位置等信息,提出了一种改进的[9]算法,引入了感知因素。上述方法可以得到高质量的结果,但计算量较大。[13]提出了一种计算量小、质量近似的风格传递前馈网络。
2.3 生成对抗网络
生成对抗网络[10](GANs)是生成模型之一,它由判别器和生成器两部分组成。GAN具有生成逼真的视觉图像的能力,在计算机视觉任务中得到了广泛的应用。[17]提出了一种图像超分辨率生成对抗网络。[6]采用有条件的GAN[25]来解决特殊的眼部彩绘问题。[27]在合成图像上训练对抗性模型,以提高合成图像的真实感。[34]甚至能够结合用户交互来显示实时图像编辑,其中GAN被用来估计图像流形。
2.4 用于图像到图像的GAN
近年来,GAN在这一领域的应用取得了一定的进展[4,12,35]。[12]提出了一种所谓的pix2pix框架,它可以对标签映射的图像进行合成,并从边缘图像重建对象。为了解决训练中缺少成对图像的问题,[22]提出了一种基于权值共享约束的生成器学习联合分布的模型。[35][14]给出了周期一致性损失,对输入和翻译后的图像之间的关键属性进行了正则化。StarGAN[4]甚至解决了单个生成器中多个域之间的映射问题。特别地,[15]引入了一种与GAN协同工作的图像属性传输编码器。
3. 我们的方法:BeautyGAN
我们的目标是在实例级实现参考化妆图像和非化妆图像之间的人脸化妆转换。考虑两个数据集合,A⊂RH×W×3指无化妆图像域和B⊂RH×W×3指化妆品领域各种化妆风格形象。我们同时学习两个域之间的映射,记为G: A×B→B×A,其中‘×’表示笛卡尔积。也就是说,给定两个图像作为输入:一个源图像Isrc∈A和参考图像Iref∈B,网络将生成一个化妆图像IBsrc∈B和卸妆图像IAref∈A,表示为(IBsrc, IAref) = G (Isrc,IAref)。IBsrc在保留Isrc人脸特征的同时,综合了Iref的化妆风格,IAref实现了Iref的卸妆。基本问题是如何学习实例级的对应关系,保证结果图像IBsrc与参考图像Iref的化妆风格一致性。注意,没有成对的训练数据。为了解决这一问题,我们引入了不同化妆品的像素级直方图损失。此外,知觉损失被用来维持人脸的身份和结构。这样我们就可以在不改变面部结构的情况下,将精确的妆容转换成原始图像。该方法基于生成的对抗性网络[10],可以方便地将所有损失项集成到一个完整的目标函数中。对抗损失有助于生成视觉上令人愉快的图像,并细化不同化妆品之间的相关性。损失函数和网络架构的详细信息如下所示。
3.1 完整目标函数
如图二所示,框架由生成器G和两个判别器DA和DB组成。在公式(IBsrc , IAref ) = G(Isrc,Iref )中,G接收两张图片Isrc ∈ A,Iref ∈ B作为输入并且生成两张翻译图片作为输出IBsrc ∈ A,IAref ∈ B。
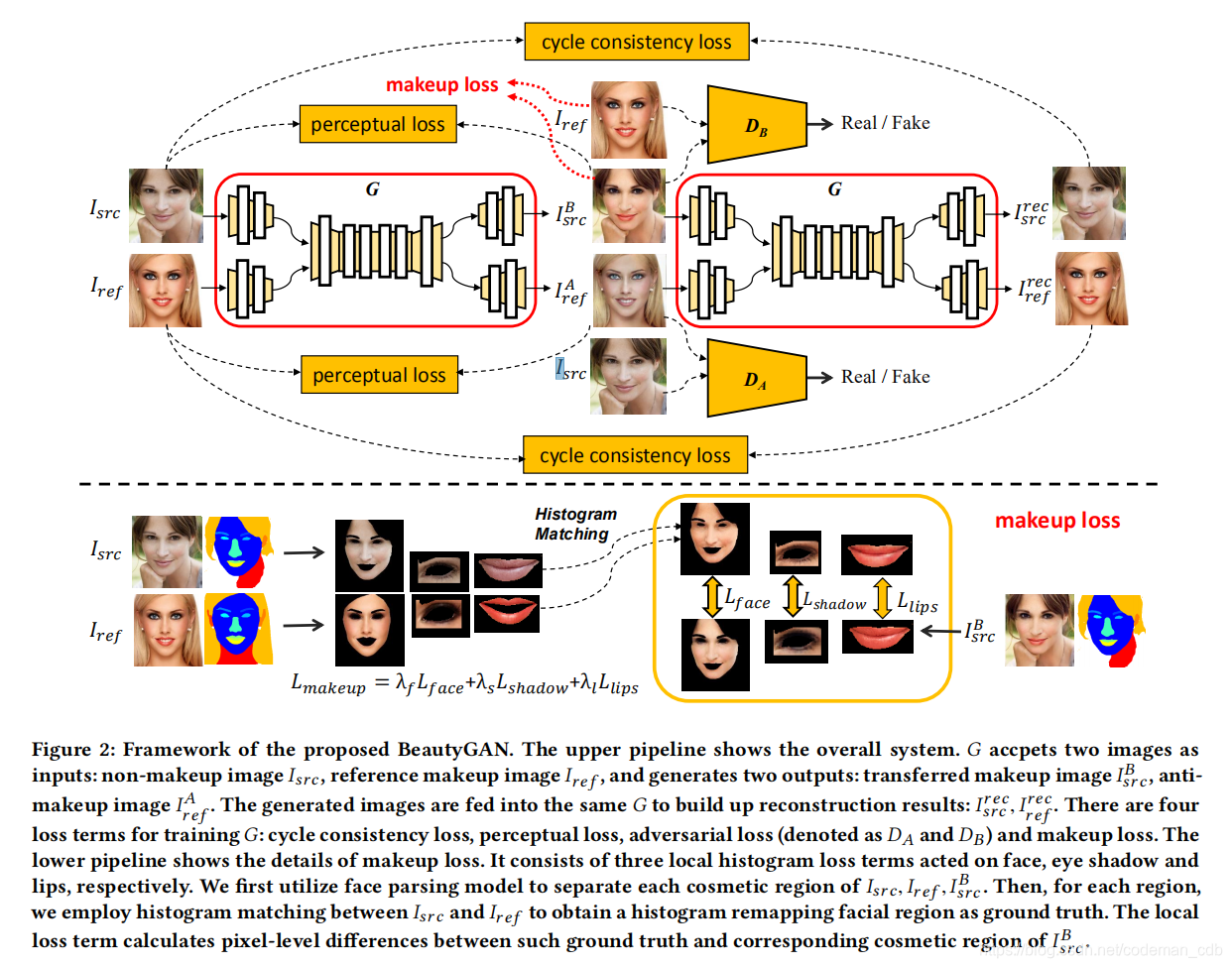
我们给出了只包含对抗损失的DA和DB的目标函数。DA将生成的图像IAref与集合A中的真实样本进行区分,得到:
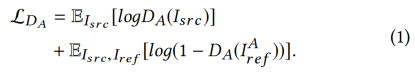
同样的,DB的目标是将生成的图像IBsrc与集合B中的真实样本进行区分,得到:
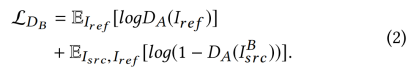
生成器G的完整目标函数包含四种损失:对抗损失、循环一致性损失、知觉损失和化妆限制损失。
![]()
α,β,γ是控制每一项的相对重要性的权重。生成器G的对抗损失为两项LDA和LDB的和:
![]()
注意生成器G和判别器 DA,DB进行最大最小对抗,G试图减少对抗损失而判别器DA,DB 旨在最大化相同的损失函数,其余三项损失将在后面各节详细说明。
3.2 域级化妆转移
我们利用领域级化妆转移作为实例级化妆品转移的基础。依托双输入/输出体系结构,该网络可以在一个生成器中同时学习两个域之间的映射。输出图像被要求保留输入图像的人脸身份和背景信息。为了满足这两个约束条件,我们分别施加感知损失和循环一致性损失。
感知损失不是直接测量像素级欧氏距离之间的差异,而是计算深度卷积网络提取的高级特征之间的差异。本文利用16层VGG网络对ImageNet数据集进行预处理。对于图像x,Fl(x)表示VGG上第l层对应的feature maps,其中Fl∈R Cl×Hl×Wl。Cl为特征图的个数,Hl和Wl分别为每个特征图的高度和宽度。因此,输入图像Isrc、Iref与输出图像IBsrc、IAref之间的感知损失表示为:
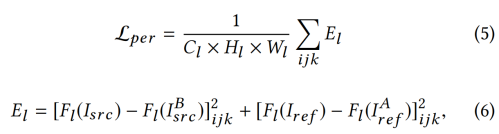
其中,Flijk表示第l层<j, k>位置的第i个过滤器的激活值。
为了维护背景信息,我们还引入了循环一致性损失。当输出图像被传递到生成器时,它应该生成与原始输入图像接近的图像。这个过程可以表示为:
![]()
损失函数的公式为:
![]()
其中 (Irecsrc , Irecref ) = G(G(Isrc , Iref ))。距离函数dist(·)可以选择为L1范数、L2范数或其他指标。
3.3 实例级化妆转移
为了进一步鼓励网络学习实例级的彩妆传输,有必要对彩妆风格一致性进行约束。我们观察到面部化妆可以被视觉上识别为颜色分布。无论是口红、眼影还是粉底,化妆的过程主要可以理解为颜色的变化。在调查[7]中可以找到各种各样的颜色转移方法。采用一种直观的直方图匹配方法(HM),在像素级引入额外的直方图损失,使输出图像IBsrc与参考图像Iref在化妆风格上保持一致。
直方图的损失。如果我们直接对两幅图像的像素级直方图采用MSE损失,由于指标函数的关系,梯度为零,对优化过程没有任何帮助。因此,我们采用直方图匹配策略,提前生成一幅基础的真值重映射图像。假设我们要计算原始图像x和参考图像y之间像素上的直方图损失,我们应该首先对x和y进行直方图匹配以获得重新映射图像HM (x, y),使其和y具有同样的颜色分布信息,但仍保留x的内容。在我们得到HM(x, y)后,可以方便利用HM(x, y)和x之间的MSE损失,然后通过逆向传播梯度进行优化。
面部解析。我们没有利用整个图像的直方图损失,而是将化妆风格分为三个重要的部分——口红、眼影、粉底。当前最先进的方法,如[23]也采取这三个组成部分作为化妆表示。然后我们对每个部分应用局部直方图损失。原因有两方面。首先,背景像素和头发与妆容无关。如果我们不把它们分开,它们就会扰乱正确的颜色分布。其次,面部化妆不是一个全局性的风格,而是在不同的化妆品领域的一系列独立风格。在这个意义上,我们使用[32]中的人脸解析模型来获得人脸引导掩码,即M = FP(x)。对于每个输入图像x,经过预处理的人脸解析模型将生成一个索引掩码M,表示多个面部位置,包括嘴唇、眼睛、面部皮肤(对应粉底)、头发、背景等。最后,对于每个M,我们根据不同的标签,生成三个对应的二进制掩码,分别代表化妆品的空间性:Mlip, Meye, Mface。需要注意的是,眼影没有标注在M上,因为化妆前的图片没有眼影。但我们期望结果图像IBsrc具有与参考图像Iref相似的眼影颜色和形状。根据眼睛掩码Meye,我们计算了两个矩形区域包围眼影,然后排除了眼睛区域和中间的一些头发和眉毛区域。因此,我们可以为眼影Mshadow创建一个特定的二进制掩码。
妆容损失。整体妆容损失由嘴唇、眼影和脸部区域的局部直方图损失三部分综合而成,分别为:
![]()
其中,λl,λs,λf为权重因子。我们将图像按相应的二进制掩码进行多元化并对结果图像与参考图像进行空间直方图匹配。在形式上,我们将局部直方图损失定义为:
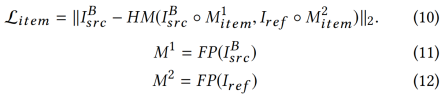
◦表示按元素多元化,且item是{唇,阴影,脸}集合中的元素。
4. 数据收集
我们收集了一个新的面部化妆数据集,包括3834张女性图片,1115张非化妆图片和2719张化妆图片。我们把这个数据集称为补强传输(MT)数据集。它包括种族、姿势、表情和背景的变化。组合了大量的化妆风格,包括烟眼妆风格、浮华妆风格、复古妆风格、韩国妆风格和日本妆风格,从细微到厚重,不一而足。具体来说,有一些裸体化妆图片,为了方便起见,被划分为非化妆类。
最初的数据是从网站上抓取的。我们手动去除了在光照条件较差的情况下的低分辨率图像。然后使用保留的图像与68个标志进行人脸对齐。根据两眼的位置,我们将它们转换为相同的空间尺寸256×256。在3834幅图像中,我们随机选取100幅非化妆图像和250幅化妆图像进行测试。剩下的图像分为训练集和验证集,与其他已发布的化妆品数据集相比,
MT是最大的化妆品数据集。现有的化妆数据集大多不超过1000张图片。他们通常为一个主题组合成对的图像:化妆前图像和化妆后图像对。虽然在这对图像中得到了相同的物体,但它们在视觉上有不同:姿势、表情甚至光照,一般用于研究化妆对人脸识别的影响,不适用于化妆转移任务。MT数据集包含了不同的化妆风格和超过3000个主题。表1列出了化妆数据集之间的详细比较。图3是MT数据集的示例。

5. 实验
在本节中,我们将描述网络体系结构和训练设置。所有的实验都使用了我们发布的相同的MT数据集。我们从定性和定量的角度比较了我们的方法和其他一些基线性能。并且我们并对BeautyGAN的组件进行了深入分析。
5.1 实现细节
网络体系结构。我们设计了具有两个输入和两个输出的生成器。具体来说,网络包含两个独立的带有卷积的输入分支。在中间,我们将这两个分支连接在一起,并将它们提供给几个残差块。在此之后,输出特征图将由两个独立的转置运算分支进行上采样,生成两个结果图像。注意,分支在层内不共享参数。对于生成器G,我们也使用实例归一化[30]。对于鉴别器DA和DB,我们利用相同的70×70 PatchGANs[18]对局部重叠图像块进行分类,将其分为真或假。
训练细节。为了稳定训练过程并生成高质量的图像,我们采用了另外两种训练策略。首先,受[35]的启发,我们用最小二乘损失[24]替换了对抗性损失中的所有负对数似然目标。如公式1定义如下,公式2和4同样道理。

其次,我们介绍了用于稳定训练识别器的谱归一化[26]。它便于计算且容易组合,满足Lipschitz约束条件σ(W) = 1:
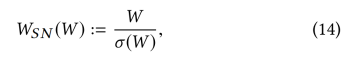
σ(W)是W的谱模,定义为:
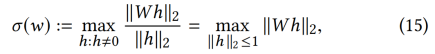
其中,h是每一层的输入。
在所有的实验中,我们都使用经过训练的用于人脸分割的PSPNet[33]在不同的人脸区域上获得标注的掩码。利用VGG16[28]网络的relu_4_1特征层进行身份保持。这种VGG16是在ImageNet上进行预训练的,在整个训练过程中参数都是固定的。参数方程3和9:α= 1,β= 10,γ= 0.005,λl = 1,λs = 1,λf = 0.1。我们使用Adam[16]从零开始训练网络,学习率为0.0002,批量大小为1。
5.2 基线
数字人脸彩妆[11]是一种早期彩妆转换工作,应用传统的图像处理方法。
DTN[23]是最先进的化妆转移工作。提出了一种深度本地化的彩妆传输网络,可以独立传输不同的彩妆。
深度图像类比[21]是近年来的一项研究,它实现了两幅语义相关图像之间的视觉属性转换。它采用图像类比的方法来匹配从深度神经网络中提取的特征。我们将其应用于化妆品转移任务中进行比较。
CycleGAN[35]是一个具有代表性的无监督图像到图像的翻译作品。为了适应化妆转移任务,我们使用两个分支作为输入来修改其中的生成器,但保持所有其他架构和设置不变。
风格转换[13]是一项相关的工作,它训练一个前馈网络来组合各自图像的风格和内容信息。我们采用非化妆图像作为实验内容并采用参考的化妆图像的风格来进行实验。
5.3 Comparison Against Baselines(比较对抗基线?)
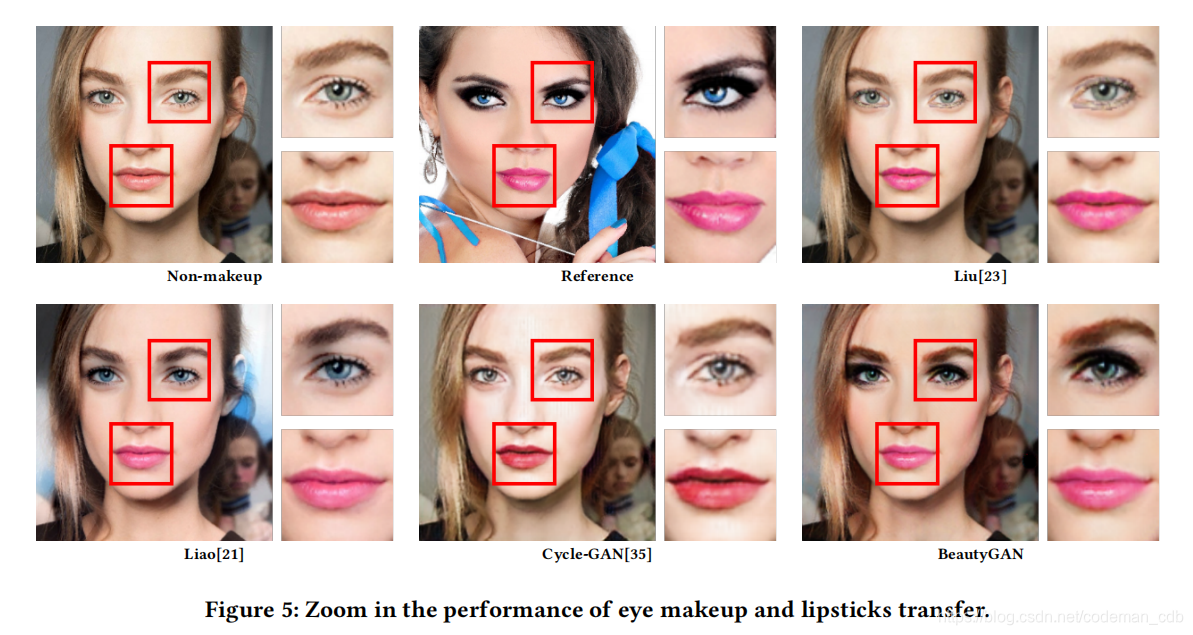
定性评估。如图4所示,我们展示了与基线的定性比较结果。我们观察到,虽然郭等人的[11]产生的图像化妆,结果都有可见的人工制品。它看起来就像一个假面具附在不化妆的脸上。不匹配问题发生在面部和眼部轮廓周围。一些不正确的细节被转移,例如第二行和第四行的黑色眼影被转移到蓝色。Liu等人,[23]独立传输不同的妆容,结果显示眼睛区域和嘴唇区域存在对齐伪影。粉底和眼影也没有正确的转移。风格转换[13]生成引入颗粒状伪影的图像,这会降低图像质量。它通常像绘画笔触一样传递整体风格,因此对于精致的妆容风格传递是不可行的。与上述方法相比,CycleGAN[35]可以生成较为真实的图像。然而,化妆风格与参考文献并不一致。廖等人以类似的化妆风格作为参考,制作出输出,显示出自然的效果。然而,它不仅转移了面部化妆,而且还转移了参考图像中的其他特征。例如,第三幅图像将背景颜色由黑色改为灰色,第四幅图像将头发颜色改为灰色,所有的图像都将瞳孔颜色修改为参考色。此外,它转移了比参考更轻的化妆风格,特别是在唇膏和眼影。

与基线相比,我们的方法生成高质量的图像与最准确的化妆风格,无论是在眼影,口红或基础上比较。例如,在第二行中,只有我们的结果传输了参考图像的深色眼影。研究结果还表明,BeautyGAN保留了与化妆无关的其他成分,如头发、衣服和背景等,与原始的非化妆图像保持一致。在图5中,我们放大了眼部化妆和唇膏转移的效果,以便更好地展示对比。更多结果显示在补充文件中。
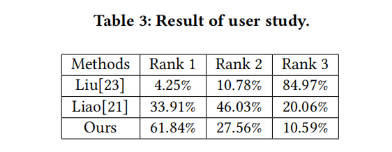
定量比较。为了定量评价BeautyGAN,我们对84名志愿者进行了用户研究。我们随机选择10张非化妆测试图像和20张化妆测试图像,每种化妆转移方法得到10×20的化妆后效果。比较了两个具有代表性的基线:Liao等人的[21]和Liu等人的[23]。每次我们展示五幅图像,包括一幅非化妆图像,一幅作为参考的化妆图像,以及三幅由不同方法生成的随机打乱的化妆转移图像。参与者被要求根据质量、真实感和化妆风格的相似性,对生成的三幅图像进行排序。排名1代表最好的化妆转移性能,排名3代表最差的化妆转移性能。
表3显示了结果。对于每一种方法,我们对投票进行标准化,并获得三个等级顺序的百分比。BeautyGAN排名第一的结果为61.84%,廖等为33.91%,刘等为4.25%。此外,BeautyGAN在排名第三的栏目中所占比例最低。我们观察到,BeautyGAN的得票以1票居多,Liao等人的得票以2票居多,Liu等人的得票以3票居多。用户研究表明,我们的方法比其他基线具有更好的性能。
5.4 BeautyGAN的组件分析
为了研究各组件在整体目标功能中的重要性(Eqn. 3),我们进行了消融研究。我们主要分析了知觉损失项(Eqn. 5)和弥补损失项(Eqn. 9)的影响,因此实验一直采用对抗性和循环一致性损失进行。表2显示了设置,图6显示了结果。在实验A中,我们将知觉损失项从Eqn中去除。在这种情况下,结果都是假图像,就像两个输入在像素上扭曲和合并一样。相反,其他包含知觉损失项的实验表明,非化妆人脸的身份得到了保持。因此,它表明知觉损失有助于保持图像的同一性。


实验B、C、D、E是为了研究化妆损失项,它包括三个作用于不同化妆区域的局部直方图损失:Lface、Lshadow、Llips。在实验B中,我们直接从Eqn中去除补妆损失。我们发现生成的图像在肤色和唇膏上有轻微的修改,但没有从参考图像中转移化妆风格。然后在实验C、D、e上依次添加Lface、Lshadow和Llips,C列表明图像基础可以成功地从参考图像中转移出来。实验D在基础转移的基础上,添加眼影约束Lshadow。我们观察到局部的眼部化妆品也转移了。E列是经过整体卸妆训练的结果。与d列相比,口红有了额外的转移。综上所述,对于实例级的转移,化妆损失是必要的。在粉底、眼影和唇膏的转移上,化妆损失有三个方面的作用。
6. 结论及未来工作
在这篇论文中,我们提出了一种双输入/输出BeautyGAN,用于实例级的面部化妆转移。通过一个发生器,BeautyGAN可以在一次向前传递的同时实现化妆和反化妆。我们引入像素级直方图损失来约束化妆风格的相似性。知觉损失和循环一致性损失被用来保持身份。实验结果表明,与现有方法相比,我们的方法可以获得显著的性能提升。



















 8321
8321



 到【灌水乐园】发言
到【灌水乐园】发言







