



在提到 React Agent 设计模式,我们可以先了解什么是 AI Agent?以及现在的 AI Agent 都有哪些设计思路?
什么是 AI Agent ?
在学术界和工业界对 AI Agent 具有不同的定义:
- 学术界定义:能够感知环境、进行决策并执行动作的智能实体。
- OpenAI 的定义:以大语言模型为大脑驱动的系统,具备自主理解、感知、规划、记忆和使用工具的能力,能够自动化执行完成复杂任务的系统。
我们抽离出五个 AI Agent 核心定义的关键词:
理解自然语言、记忆能力、任务规划、任务执行、环境感知。
Workflows 与 Agent 的区别
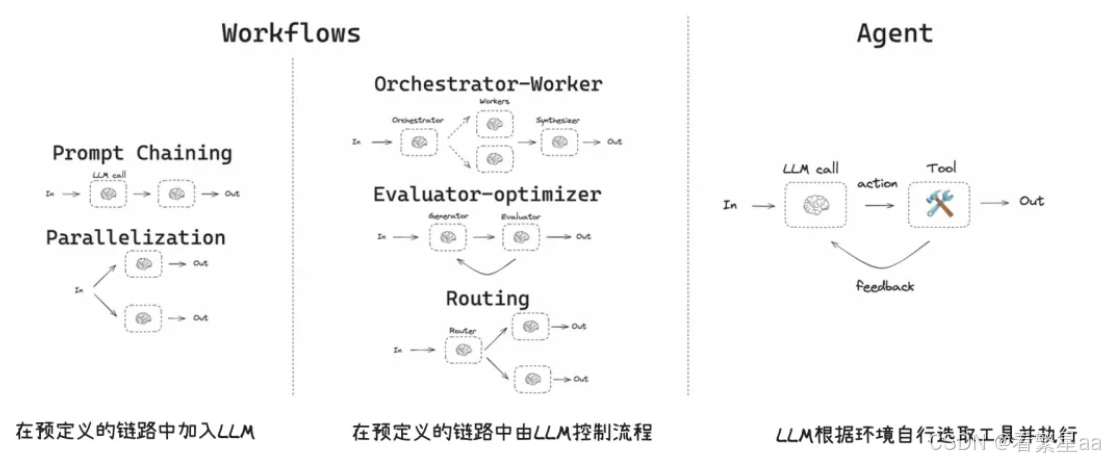
- Workflow 通过用户预定义好的路径执行
- Agent 可感知环境自主规划、自主决策并执行
像 Dify、Coze 等可视化编排工具,非常适合和快速搭建 步骤确定 + 条件有限 的流程。
但一旦问题的所可能产生的 执行分支 相当多时,workflow 就会分支爆炸!
这里举一个例子:
例:同一条“包裹没到”诉求,可能要综合 ①承运商状态 ②发货 SLA ③节假日政策 ④地址异常 ⑤是否会员 ⑥是否已报缺货 ⑦是否已部分签收 ⑧是否叠加优惠券/补发 等。
如果用固定分支描述:假设有 5 个意图 × 6 种物流状态 × 3 种用户等级 × 3 个政策时段(平日/大促/假期) × 3 种地理区域,共5×6×3×3×3=810 条潜在路径。
这还没算异常(报损、拒收、欺诈信号)与“对话澄清”的分支。维护成本和上线速度都会被拖垮。此外,Workflow 对 对话中的“澄清—再决策—再行动 并不天然友好,需要把每一步提问、回答、重试都画成节点,复杂而脆弱。
所以,Agent 的出现就是用来解决这种 “问题执行分支爆炸、不能完全穷举;且在对话中可能需要多次澄清/协商等” 复杂、难以定制的问题。
这里举一个具体的例子:
场景:用户说 “我点的外卖还没到,想换个收货楼层,而且好像多收了配送费”
Agent 核心动作(全程自然对话推进,无固定分支)
- 先澄清关键信息(问一句)
- 不机械罗列问题,而是顺着对话问:“麻烦发下你的外卖订单号呀?另外新楼层是几楼呀?我帮你一起核对~”
- (核心:根据用户混合诉求,动态抓取需补充的关键信息,不用预设 “先问订单号还是新地址”)
- 跨工具同步查询(查一下)
- 调用外卖配送系统:查订单当前位置、预计送达时间、是否有超时情况。
- 调用计费系统:核对配送费规则,看是否存在重复计费、规则适用错误(比如用户是会员本应免配送费)。
- 调用用户信息系统:看是否是常购用户、有没有历史投诉记录(影响后续方案优先级)。
- (核心:不用按固定顺序查,多工具并行获取数据,避免用户等待)
- 结合上下文做决策(再决定)
- 若查询结果:外卖还在配送中(未超时)+ 确实多收 1 次配送费 + 用户是常购会员
- 决策:优先处理改址(同步通知骑手),再解决计费问题,同时给会员小额补偿。
- 若查询结果:外卖已超时 15 分钟 + 配送费无异常(用户误判)+ 新楼层与原地址在同一楼栋
- 决策:先致歉超时问题,承诺加速配送,免费改址,再解释配送费明细(避免用户误解)。
- (核心:无固定决策路径,完全依赖 “用户回答 + 工具查询结果” 动态判断)
- 方案告知与闭环
- 一次性给出整合方案:“订单号 XXX 已查到~已通知骑手改送 X 楼,预计 10 分钟内到。另外核实到确实多收了 5 元配送费,会原路退回,还送你一张 3 元无门槛券补偿,现在就能用~”
- (核心:不用分步骤单独沟通,方案随决策实时生成,贴合对话节奏)
这个例子没有复杂的系统名词,却能直观体现:Agent 不用预设 “超时 / 未超时”“计费有问题 / 没问题” 的固定分支,而是通过 “问关键信息→跨工具查数据→按结果做决策” 的动态流程,自然解决用户的混合诉求,这正是它比固定 Workflow 灵活的核心优势。
LLMs 是一只只有 6s 记忆的鱼
LLMs 本身具备强大的自然语言处理能力,但与它本身没有记忆能力,当你向它提出一个问题后,下次再提问相关问题它就立马“忘记了”!
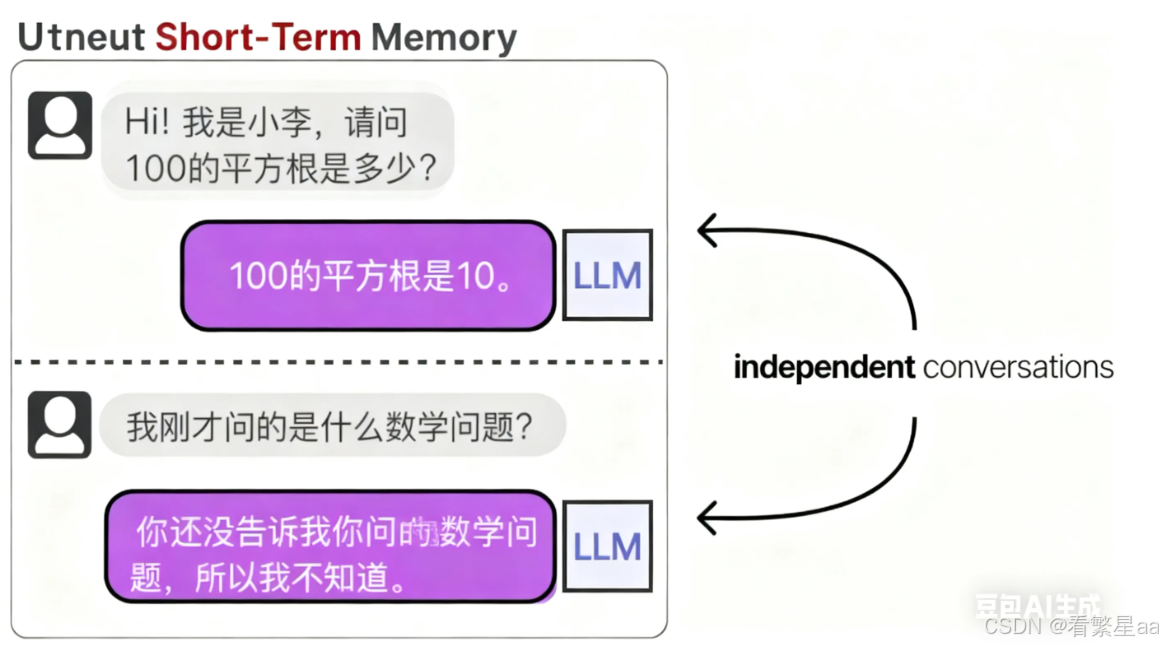
于是就有了一种解决方案,在每次对话时将之前的历史记录给大模型,告诉它之前我们的聊天记录。这样即使大模型只有 6s 的记忆,但我每次提问前都会将历史聊天记录告诉它,也算相当于让他“记住”了!
这是一种短期记忆,本质上并不是让 LLM 记住对话内容,而是将历史对话作为提示词的一部分告诉 LLM。每个 LLM 所能接受的历史对话大小是有限的,专业地说 LLM 的上下文窗口是有大小限制的,一般上下文窗口至少包含8192个token,最多可以到数十万token!
但是对于常见 Agent 来说,需要追踪和规划的任务少则十个,多则几十个步骤,例如常见的 vibe coding(==氛围编程 -- 依托 AI 技术,专注于通过自然语言描述需求,让 AI 自动生成代码并快速实现产品==)。
Agent 需要记住开发者的交互习惯、历史技术选型、编程习惯等,给开发者一个连续的、享受的 coding 体验。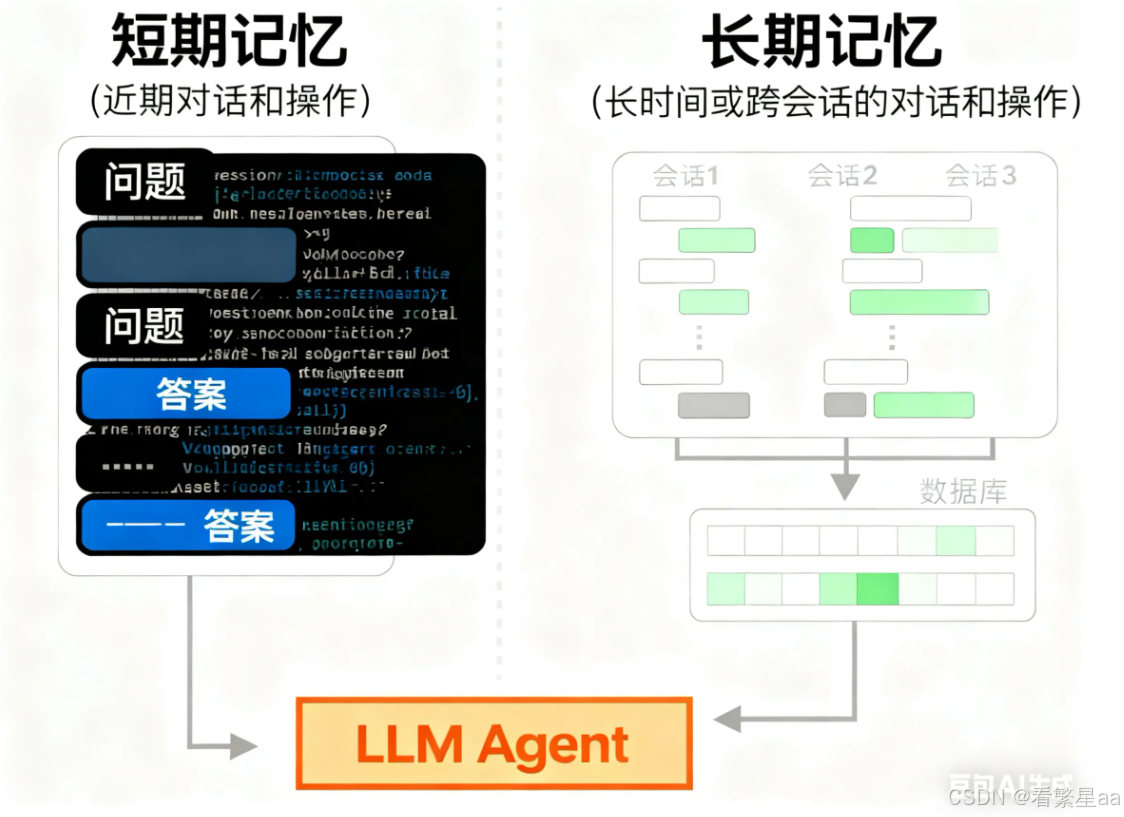
与短期记忆对应而言的便是长期记忆。LLM 的上下文窗口是有限的,但历史记录中并不是所有的信息都是需要大模型进行短期记忆的,所以这会造成对 LLM 上下文窗口的浪费。所以我们可以把需要长期记忆的历史记录存储到数据库中,当 LLM 收到提问时,便会向数据库中只检索对该问题的相关内容,并作为提示词填充到自己的上下文窗口。
LLMs 的任务规划
就像人的大脑一样,当接收到复杂任务时,不是直接给出答案,而是将复杂任务推理拆分为一个个具体可执行的任务串联起来去解决问题。
目前实现 LLM 进行准确的任务规划能力有两种实现思想模式。
- Self - Ask 模式
一种让 LLM 自问自答的模式,目的是细化任务的前置细节。例如接口规范、技术选型、中间件选择等。
LLM 根据用户提出的问题,进行深入的自我提问,将大问题拆分成小问题,然后逐一回答。
举一个例子:
用户输入:写一个用户积分兑换商品的接口。
- 自问:“接口用什么 HTTP 方法?POST(因为涉及数据修改)还是 PUT?”自答:“兑换是创建兑换记录,用 POST 更符合 REST 规范。”
- 自问:“请求参数需要哪些?用户 ID、商品 ID,是否需要校验用户签名?”自答:“必须包含 user_id、goods_id,还需要 token 验证用户身份,防止越权。”
- 自问:“积分扣减和商品库存扣减需要事务吗?万一扣了积分但库存不足怎么办?”自答:“必须用数据库事务(如 Go 的 sql.Tx),确保积分和库存操作要么同时成功,要么同时回滚。”
- 自问:“兑换成功后需要发消息通知用户吗?用 RabbitMQ 还是 Kafka?”自答:“需要,项目里现有 RabbitMQ,用它发消息到用户通知队列。”
这些都是后端开发必须明确的细节,否则代码会漏洞百出。
其实这里我们在做设计接口、编写代码的时候也应该多自问自答,保持好问与好奇心。
- chain of thought 模式
这是一种思维链模式,目标是拆解为具体的执行步骤。会逐步拆解完成任务的执行步骤,并梳理步骤之间的依赖关系。
- 定义接口结构体:用 Go 的 struct 定义请求体(Request)和响应体(Response),例如:go运行
type ExchangeRequest struct { UserID int64 `json:"user_id" binding:"required"` GoodsID int64 `json:"goods_id" binding:"required"`}Plain Text
Go
- 参数校验:用 gin 框架的 binding 验证请求参数,同时校验用户 token 有效性(调用 auth middleware)。
- 查询数据:查用户当前积分( SELECT points FROM user_account WHERE user_id = ? )和商品库存( SELECT stock, price_points FROM goods WHERE id = ? )。
- 业务判断:检查用户积分是否≥商品所需积分,商品库存是否≥1,若不满足返回错误。
- 事务操作:开启数据库事务,执行:
- 扣减用户积分( UPDATE user_account SET points = points - ? WHERE user_id = ? )
- 扣减商品库存( UPDATE goods SET stock = stock - 1 WHERE id = ? )
- 新增兑换记录( INSERT INTO exchange_records (...) VALUES (...) )若任一操作失败,回滚事务。
- 发送通知:事务提交后,用 RabbitMQ 客户端发送兑换成功消息(包含用户 ID、商品名等)。
- 返回响应:给前端返回兑换结果(成功 / 失败原因)。
这两种模式都只能通过大模型微调,或提示词来保证。
LLMs 的任务执行
这要引入一个概念 **工具(Tool)。**LLM 可以根据需要选择使用合适的工具去执行任务。
对于工具调用的方式,一般分为两种:
- 函数调用 (Function Calling)
- 通过 MCP(Model Context Protocol) 调用工具
无论使用哪种方式,LLM 都必须生成符合给定工具 API 的文本,一般来说为 JSON 格式的字符串。
举个例子:
我们在本地实现了一个乘法的函数并作为 LLM 的 Tool。
当用户输入 "5乘以3等于多少?",LLM 会选择 Tool,并生成对应的 JSON 格式字符串,用程序根据字符串判断使用哪个工具以及如何调用。
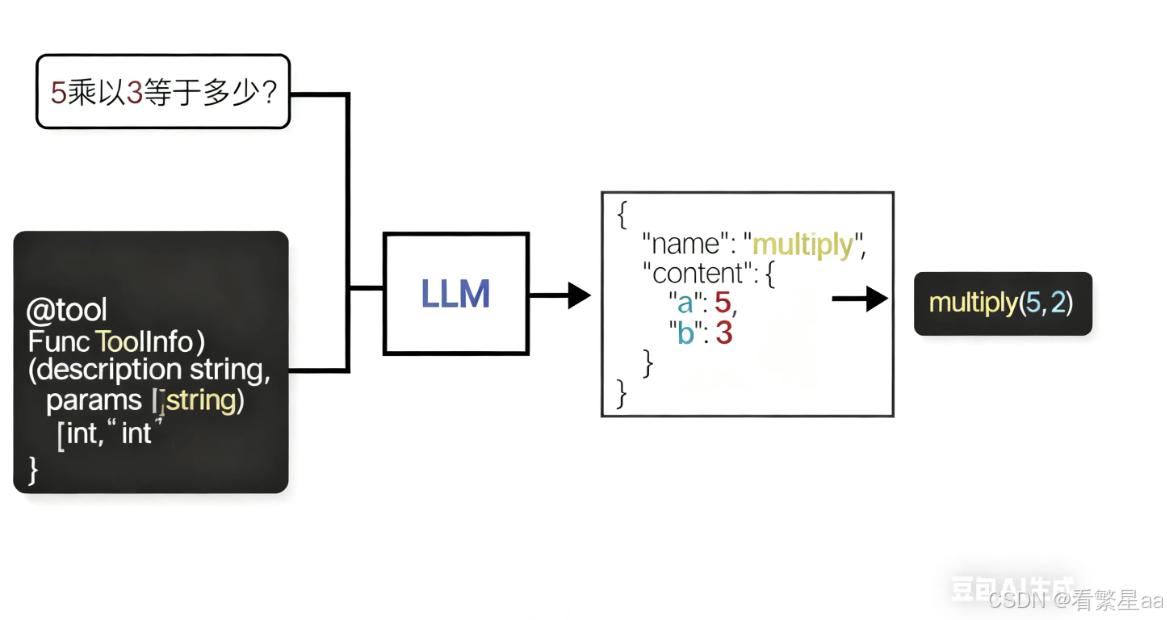
所以,一般来说一个 Tool 需要有两个行为:一是要描述自身的功能,二是要定义执行过程。
type Tool interface {
Info() ToolInfo
Execute(params map[string]any) any
}
这些设计思想体现了 Agent 最基本的核心能力,即
- 如何更好地理解用户意图;
- 如何进行任务规划;
- 如何执行任务
解决了实现 Agent 核心的各种问题后,我们该如何更好地将这些能力设计与组合,以更好地感知环境?
ReAct Agent 设计思想
前面我们分别介绍了 AI Agent 的五个核心能力:理解自然语言、记忆能力、任务规划(Self-Ask 和 Chain of Thought)、任务执行(工具调用)。
但这些能力单独存在时,还不足以构成一个真正智能的 Agent。就像人有眼睛、大脑、双手,但如果不协同工作,也做不了什么事。
ReAct(Reasoning and Acting)设计模式的核心价值,就是把这些能力有机地组合起来,并通过"循环反馈"的方式,让 Agent 具备真正的环境感知和自主解决问题的能力。
ReAct 如何融合五大核心能力?
我们用一个实际场景来理解 ReAct 是如何把前面讲的所有能力串起来的:
场景:用户说:"帮我给用户 12345 发个积分到账通知,他刚兑换了一个 199 元的耳机。"
这个需求看似简单,但实际上涉及多个步骤和不确定性:需要查用户信息、查商品、扣积分、发通知,任何一步出问题都可能导致失败。
ReAct 的执行循环
ReAct 通过 Thought(思考)→ Action(行动)→ Observation(观察) 三个步骤循环执行,直到任务完成。
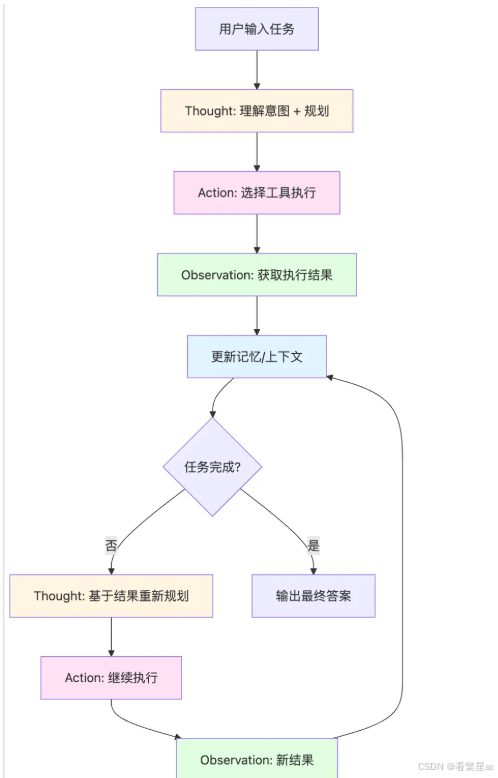
让我们看看这个例子中,ReAct 是如何一步步运作的。
第 1 轮循环
1. Thought(Self-Ask + CoT 任务规划模式)
【理解自然语言】
用户要"发积分到账通知",涉及到用户、积分、兑换商品三个要素。
【Self-Ask 自问】
- 用户 12345 真的兑换成功了吗?我需要先确认兑换记录存在。
- 积分是多少?199 元的耳机对应多少积分?
- 用户的联系方式是什么?手机号?邮箱?
【Chain of Thought 推理】
第一步应该先查兑换记录,确认这笔兑换是否真实存在。
如果存在,再获取积分数和用户联系方式。
2. Action(任务执行)
LLM 完成任务规划后,决定是否调用以及调用什么工具来执行任务。
一般通过上文讲的两种方式:
- Function Calling
- MCP
{
"tool": "query_exchange_record",
"params": {
"user_id": 12345,
"goods_name": "耳机",
"price": 199
}
}3. Observation(环境感知)
{
"success": true,
"data": {
"exchange_id": "EX_88776",
"user_id": 12345,
"goods_name": "索尼 WH-1000XM5 耳机",
"points_used": 19900,
"exchange_time": "2025-11-08 10:25:12",
"status": "success"
}
}
记忆更新:Agent 将这条信息存入短期记忆,作为下一步决策的依据。
第 2 轮循环
1. Thought(基于上一轮观察结果重新规划)
【分析 Observation】
好,兑换记录确实存在,用户花了 19900 积分兑换了耳机。
【Self-Ask】
- 用户的手机号是什么?需要查用户信息表。
- 通知内容该怎么写?应该包含商品名、积分数、兑换时间。
【Chain of Thought】
下一步:查用户信息,获取手机号,然后构造通知内容。
2. Action
{
"tool": "query_user_info",
"params": {
"user_id": 12345
}
}
3. Observation
{
"success": true,
"data": {
"user_id": 12345,
"name": "张三",
"phone": "138****5678",
"email": "zhangsan@example.com"
}
}
记忆更新:现在 Agent 知道了用户手机号和姓名。
第 3 轮循环
1. Thought
【分析当前状态】
现在我有了:
- 兑换记录:EX_88776,索尼 WH-1000XM5 耳机,19900 积分
- 用户信息:张三,138****5678
【Self-Ask】
- 通知渠道用什么?短信?App 推送?还是都发?
- 通知内容需要包含哪些关键信息?
【Chain of Thought】
最后一步:调用消息通知工具,发送积分到账通知。
通知内容应该包含:商品名、积分数、兑换时间,让用户清楚知道扣了多少分。
渠道选短信 + App 推送双保险。
2. Action
{
"tool": "send_notification",
"params": {
"user_id": 12345,
"type": "points_deduction",
"message": "尊敬的张三,您已成功兑换索尼 WH-1000XM5 耳机,消耗积分 19900 分,兑换时间 2025-11-08 10:25。",
"channels": ["sms", "app_push"]
}
}
JSON
3. Observation
{
"success": true,
"send_time": "2025-11-08 14:30:22",
"channels_sent": ["sms", "app_push"]
}
第 4 轮循环
1. Thought
【检查任务状态】
✅ 查到兑换记录(EX_88776)
✅ 获取用户信息(张三,138****5678)
✅ 发送通知成功(短信 + App 推送)
任务完成,可以返回结果了。
2. Action
Finish(任务结束)
3. 最终输出
已成功为用户 12345(张三)发送积分到账通知:
- 兑换商品:索尼 WH-1000XM5 耳机
- 消耗积分:19900 分
- 兑换时间:2025-11-08 10:25
- 通知渠道:短信 + App 推送
- 发送时间:2025-11-08 14:30
ReAct 的 “能力融合与增强”
从上面的例子可以看到,ReAct 把五大核心能力完美融合:
| 核心能力 | 在 ReAct 中的体现 |
|---|---|
| 理解自然语言 | Thought 阶段,LLM 理解用户意图:"发积分到账通知"涉及查记录、查用户、发通知 |
| 记忆能力 | 每轮 Observation 结果被记录到上下文,后续 Thought 可以基于历史信息做决策 |
| 任务规划(Self-Ask) | Thought 中不断自问:"需要查什么?""用户手机号在哪?""通知内容怎么写?" |
| 任务规划(CoT) | Thought 中推理执行顺序:"先查兑换记录 → 再查用户信息 → 最后发通知" |
| 任务执行 | Action 阶段调用具体工具:query_exchange_record、query_user_info、send_notification |
| 环境感知 | 通过 Observation 获取每步执行结果,根据结果动态调整下一步行动(不是死板的预设流程) |
ReAct 的循环反馈增强 Agent 的环境感知力
如果没有 Observation → Thought 的循环反馈,Agent 只能"盲目执行"预定好的步骤。一旦某一步出问题(比如兑换记录不存在、用户手机号为空),就直接崩溃。
但 ReAct 的循环机制让 Agent 可以"看到"每一步的执行结果,然后根据实际情况调整策略。
举个例子:出现异常时 ReAct 如何应对
假设第 1 轮查询兑换记录时,返回了这样的结果:
{
"success": false,
"error": "未找到用户 12345 在 2025-11-08 兑换 199 元耳机的记录"
}
传统固定流程(如 Workflow)会直接报错:"兑换记录不存在,任务失败。"
ReAct 的处理方式(进入下一轮循环):
Thought
【分析 Observation】
查询失败,可能的原因:
1. 用户还没完成兑换,只是咨询
2. 价格不是 199 元(可能是 299、399)
3. 兑换时间不是今天
【Self-Ask】
我应该先问用户确认一下,还是扩大查询范围?
【Chain of Thought】
先扩大查询范围,查最近 3 天内该用户的所有兑换记录,看看有没有耳机相关的。
Action
{
"tool": "query_exchange_record",
"params": {
"user_id": 12345,
"goods_type": "耳机",
"date_range": "last_3_days"
}
}
Observation
{
"success": true,
"data": [
{
"exchange_id": "EX_88776",
"goods_name": "索尼 WH-1000XM5 耳机",
"price": 299, // 注意:实际是 299 元,不是 199
"points_used": 29900,
"exchange_time": "2025-11-07 16:20:00"
}
]
}
这就是"环境感知"的威力:Agent 发现实际情况与用户描述有出入(299 vs 199),但通过扩大查询范围找到了正确记录,然后继续执行后续步骤,而不是直接失败。
总结
ReAct 不是一个全新的能力,而是一个组合框架,它把前面讲的五大核心能力(理解、记忆、规划、执行、感知)通过 Thought → Action → Observation 循环 串联起来。
- Thought 融合了 Self-Ask(自问自答细化细节)和 Chain of Thought(推理执行步骤)
- Action 就是调用工具执行任务
- Observation 就是环境感知,获取执行结果
- 记忆 贯穿整个循环,每轮结果都被记录,供后续决策使用
通过这个循环,Agent 不再是"死板地按步骤执行",而是"看一步走一步",根据实际情况动态调整。这正是 ReAct 比传统 Workflow 强大的核心原因。
这里附一下字节跳动开源框架 Eino 对 ReAct Agent 的具体设计:
https://www.cloudwego.io/zh/docs/eino/core_modules/flow_integration_components/react_agent_manual/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









