



模型架构
-
设计思路
DeepSeek-V3的设计思路主要围绕提高训练和推理效率,同时保持模型性能。具体包括:
-
高效推理:通过MLA减少推理时的KV缓存,提高推理速度。
-
高效训练:通过DeepSeekMoE架构和辅助损失平衡策略,提高训练效率,避免路由崩溃。
-
负载平衡:通过动态调整偏置项实现负载平衡,提高模型性能。
-
多令牌预测:通过多令牌预测(MTP)目标,提高模型的预测能力。
通过这些设计,DeepSeek-V3在保持高性能的同时,显著降低了训练和推理的成本。
DeepSeek-V3模型的架构基于Transformer框架,采用了Multi-head Latent Attention (MLA)和MoE架构。模型包括671B参数和37B激活参数。
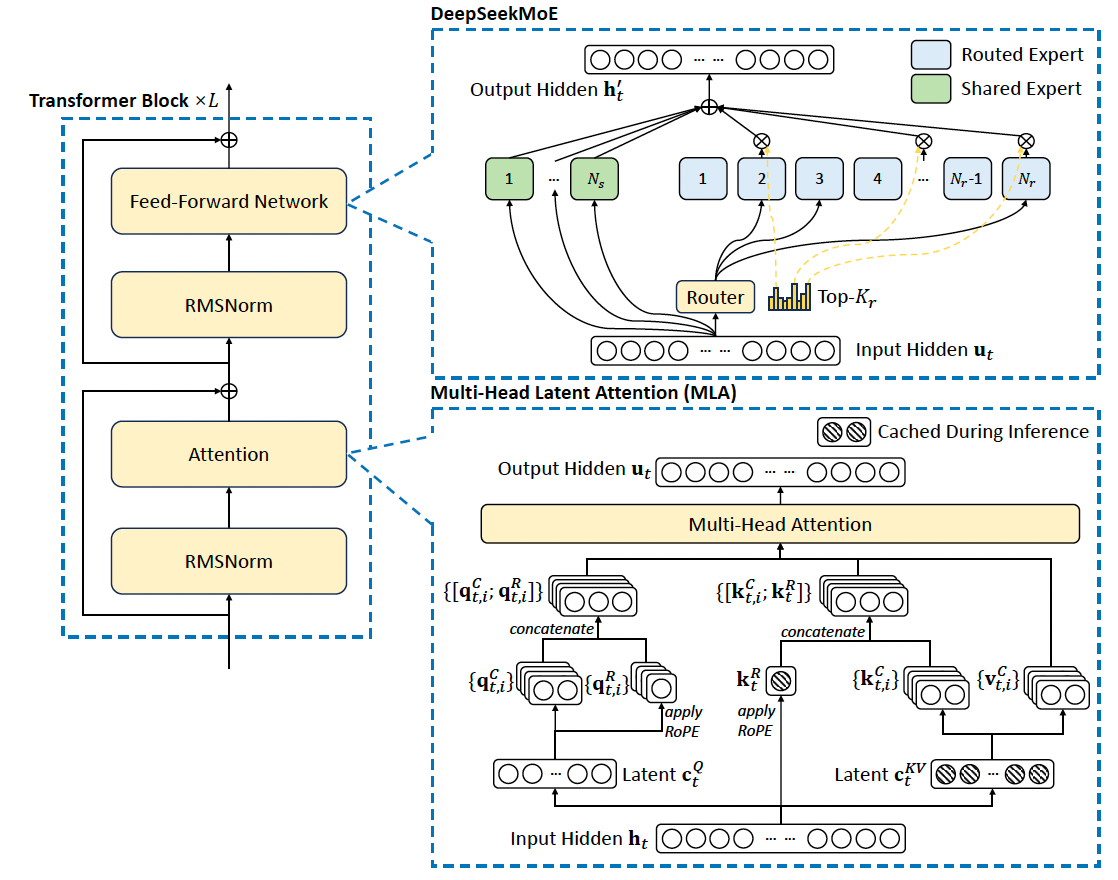
-
Multi-Head Latent Attention (MLA)
MLA通过低秩联合压缩注意力键和值,减少推理时的KV缓存。具体步骤如下:
-
压缩:将注意力键K和值V压缩成低维的潜在向量。
-
解耦:使用RoPE(Rotary Positional Embedding)对解耦的键和值进行处理。
-
查询压缩:对查询也进行低秩压缩,减少训练时的激活内存。
MLA对原始模型的压缩分为两部分:
-
KV压缩:
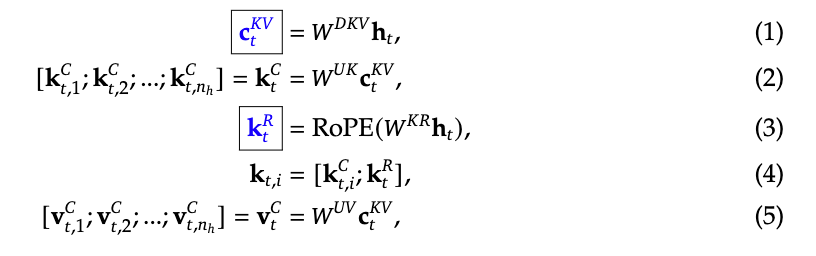
在实际实现中,有四个权重矩阵,分别是W_DKV,W_UK, W_UV和W_KR
其中W_DKV负责将attention模块的输入h 投影到低维的特征空间c,随后再通过W_UK/W_UV得到attention过程中需要的k和v矩阵,将输入h与W_KR相乘并进行RoPE操作后得到对k的位置编码。最终的k矩阵由特征矩阵和位置编码矩阵拼接而成。
最终kvcache缓存只需要保存标蓝的c和k的位置编码矩阵。
注意在实际更新时,kvcache采用滑动窗口的方式进行更新,仅保存上一次forward过程中的kvcache值,不保存更久远的记忆。以deepseekv3源代码为例:
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)- query压缩
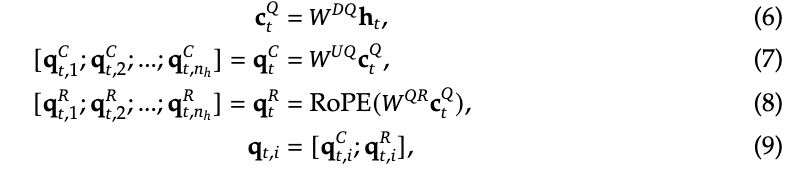
类似的,对query进行相似的操作,可以有效降低激活值的存储大小(Q:怎么降低激活值的存储大小的?A:因为在这个过程中,如果是MHA的话,计算query的权重矩阵大小是input_dim x q_dim,MLA中,计算query的权重矩阵大小是input_dim x low_q_dim + low_q_dim x q_dim,所以可以有效降低激活值的存储大小(类似lora)。)
这里贴一下ds的mla实现代码(仅用作个人学习),详情可参考链接:DeepSeek-V3/inference/model.py at main · deepseek-ai/DeepSeek-V3
class MLA(nn.Module):
"""
Multi-Head Latent Attention (MLA) Layer.
Attributes:
dim (int): Dimensionality of the input features.
n_heads (int): Number of attention heads.
n_local_heads (int): Number of local attention heads for distributed systems.
q_lora_rank (int): Rank for low-rank query projection.
kv_lora_rank (int): Rank for low-rank key/value projection.
qk_nope_head_dim (int): Dimensionality of non-positional query/key projections.
qk_rope_head_dim (int): Dimensionality of rotary-positional query/key projections.
qk_head_dim (int): Total dimensionality of query/key projections.
v_head_dim (int): Dimensionality of value projections.
softmax_scale (float): Scaling factor for softmax in attention computation.
"""
def __init__(self, args: ModelArgs):
super().__init__()
self.dim = args.dim
self.n_heads = args.n_heads
self.n_local_heads = args.n_heads // world_size
self.q_lora_rank = args.q_lora_rank
self.kv_lora_rank = args.kv_lora_rank
self.qk_nope_head_dim = args.qk_nope_head_dim
self.qk_rope_head_dim = args.qk_rope_head_dim
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim
self.v_head_dim = args.v_head_dim
if self.q_lora_rank == 0:
self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim)
else:
self.wq_a = Linear(self.dim, self.q_lora_rank)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
self.kv_norm = RMSNorm(self.kv_lora_rank)
self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim))
self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim)
self.softmax_scale = self.qk_head_dim ** -0.5
if args.max_seq_len > args.original_seq_len:
mscale = 0.1 * args.mscale * math.log(args.rope_factor) + 1.0
self.softmax_scale = self.softmax_scale * mscale * mscale
if attn_impl == "naive":
self.register_buffer("k_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.qk_head_dim), persistent=False)
self.register_buffer("v_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.v_head_dim), persistent=False)
else:
self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False)
self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
"""
Forward pass for the Multi-Head Latent Attention (MLA) Layer.
Args:
x (torch.Tensor): Input tensor of shape (batch_size, seq_len, dim).
start_pos (int): Starting position in the sequence for caching.
freqs_cis (torch.Tensor): Precomputed complex exponential values for rotary embeddings.
mask (Optional[torch.Tensor]): Mask tensor to exclude certain positions from attention.
Returns:
torch.Tensor: Output tensor with the same shape as the input.
"""
bsz, seqlen, _ = x.size()
end_pos = start_pos + seqlen
if self.q_lora_rank == 0:
q = self.wq(x)
else:
q = self.wq_b(self.q_norm(self.wq_a(x)))
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
kv = self.wkv_a(x)
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
if attn_impl == "naive":
q = torch.cat([q_nope, q_pe], dim=-1)
kv = self.wkv_b(self.kv_norm(kv))
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim)
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
self.k_cache[:bsz, start_pos:end_pos] = k
self.v_cache[:bsz, start_pos:end_pos] = v
scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz, :end_pos]) * self.softmax_scale
else:
wkv_b = self.wkv_b.weight if self.wkv_b.scale is None else weight_dequant(self.wkv_b.weight, self.wkv_b.scale, block_size)
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
if mask is not None:
scores += mask.unsqueeze(1)
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
if attn_impl == "naive":
x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz, :end_pos])
else:
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
return x
-
DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
-
专家混合网络(Mixture of Expert,MoE)简介:
专家混合网络是指通过选择性激活部分参数来提升大模型计算效率和性能的方法。它的核心思想是:只让部分“专家”参与一次前向传播,减少整体计算负担,同时保持高容量的表达能力。
-
MoE的用途
在transformer中,MoE的作用是作为FFN的替代,从原始的单一FFN变成多个“Expert”,用多个FFN来提升特征的丰富性(类似的,MHA也是对单个QKV attention的改进)。
ps:本质上,这是一种稀疏激活策略,通过有选择性的激活特定的weight,提升模型的整体性能。
-
MoE的常见类型
-
DeepseekMoE (2024,是在deepseekv2里第一次提出,dsv3,r1里都在用)
-
DeepSeekMoE架构介绍
-
公式:
-
ut代表输入,ht代表输出。
-
在该架构中,包含了两类Expert,一类是shared expert(不同输出过程中均被激活的expert,用FFN^s表示),一类是routed expert(在不同输出过程中激活的topk个与当前输出相关的expert,用FFN^r表示)
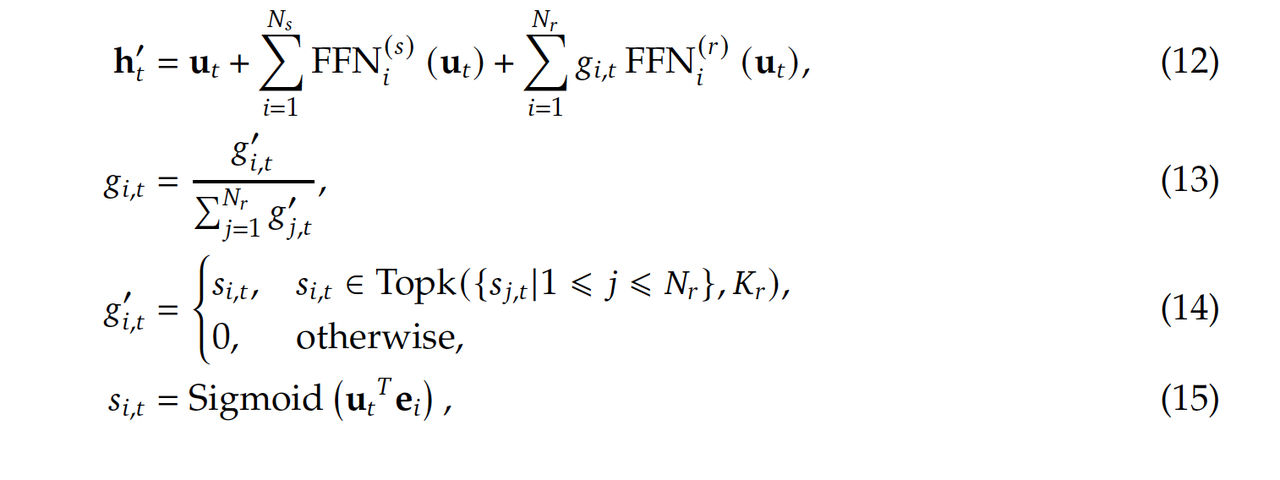
-
-
具体代码
-
MoE forward函数:
def forward(self, x: torch.Tensor) -> torch.Tensor:
shape = x.size()
x = x.view(-1, self.dim)
# weights 代表被选中的expert的权重,indices代表被选中的expert的id
weights, indices = self.gate(x)
y = torch.zeros_like(x)
counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts).tolist()
for i in range(self.experts_start_idx, self.experts_end_idx):
if counts[i] == 0:
continue
expert = self.experts[i]
idx, top = torch.where(indices == i)
y[idx] += expert(x[idx]) * weights[idx, top, None]
z = self.shared_experts(x) # FFN^s(x)
if world_size > 1:
# 这里all_reduce(y)的作用是在分布式计算过程中把所有计算得到的y收集起来
dist.all_reduce(y)
# 此处为FFN^r(u) + FFN^s(u), +u的操作在class Block中进行
return (y + z).view(shape)Gate forward函数:
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
scores = linear(x, self.weight)
if self.score_func == "softmax":
scores = scores.softmax(dim=-1, dtype=torch.float32)
else:
scores = scores.sigmoid() # s_it = sigmoid(u*e)
original_scores = scores
# 选择topk个expert的过程
if self.bias is not None:
# 这一行对应auxiliary-loss-free load balancing strategy,通过加bias的方式平衡不同expert
scores = scores + self.bias
if self.n_groups > 1:
scores = scores.view(x.size(0), self.n_groups, -1)
if self.bias is None:
group_scores = scores.amax(dim=-1)
else:
group_scores = scores.topk(2, dim=-1)[0].sum(dim=-1)
indices = group_scores.topk(self.topk_groups, dim=-1)[1]
mask = scores.new_ones(x.size(0), self.n_groups, dtype=bool).scatter_(1, indices, False)
scores = scores.masked_fill_(mask.unsqueeze(-1), float("-inf")).flatten(1)
indices = torch.topk(scores, self.topk, dim=-1)[1]
weights = original_scores.gather(1, indices)
if self.score_func == "sigmoid":
weights /= weights.sum(dim=-1, keepdim=True)
weights *= self.route_scale
return weights.type_as(x), indices # g_it-
DeepseekMoE在v3中的改进
-
负载均衡
- Auxiliary-Loss-Free Load Balancing
- 目标:提升不同专家之间的负载均衡。与常见的负载均衡(防止少数专家被持续激活,其他专家起不到作用)过程利用auxiliary loss的方式不同,动态调整每个专家的偏置项,从而确保不会让少数专家占据大多数的计算过程。(具体的实现就是对每个s_it,加上一个bi项(偏置项))
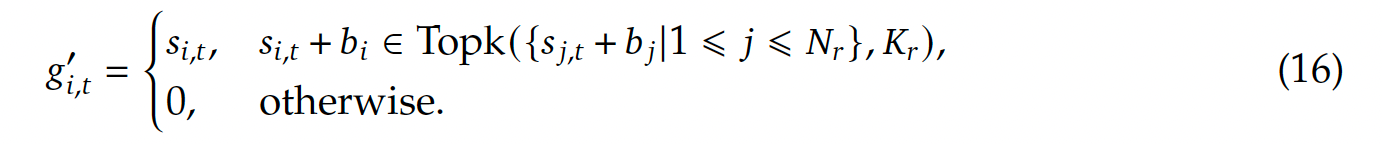
- 训练时,在每个训练步(training step)上,会关注整个batch中的expert load,如果一个expert i起到了很多次作用,就降低bi,反之则提升bi,这一步是通过一个超参数 bias update speed(bias更新速率) $$\gamma $$来进行的,bi' = $$\gamma $$bi (提升bi),bi' = bi / $$\gamma $$ (降低bi),因此推测$$\gamma >1 $$.
- 目标:提升不同专家之间的负载均衡。与常见的负载均衡(防止少数专家被持续激活,其他专家起不到作用)过程利用auxiliary loss的方式不同,动态调整每个专家的偏置项,从而确保不会让少数专家占据大多数的计算过程。(具体的实现就是对每个s_it,加上一个bi项(偏置项))
- Complementary Sequence-Wise Auxiliary Loss.
- 目标:降低单个序列中的极端不平衡现象。
- 损失函数计算过程:
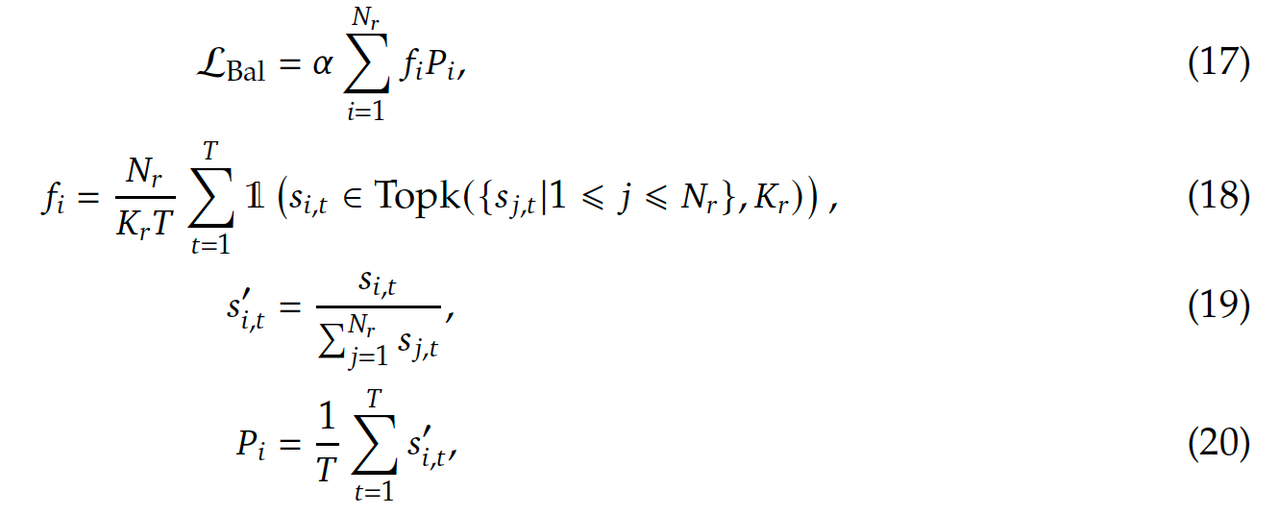
- Auxiliary-Loss-Free Load Balancing
- Node-Limited Routing(限制每个token只被有限个节点获取并计算,从而限制通信开销。)
- No Token Dropping(在训练过程中不需要随机去除token)
多token预测(Multi-Token Prediction)
MTP模块的作用:
-
通过MTP的训练方式,提升数据的利用效率(例如之前一个句子只预测一个单词,但现在可以预测多个,并测试效果)
-
使模型能够提前预测token,从而提升输出的token质量。
MTP思路:顺序连接主模型和D个MTP模块,序列化预测未来的D个token
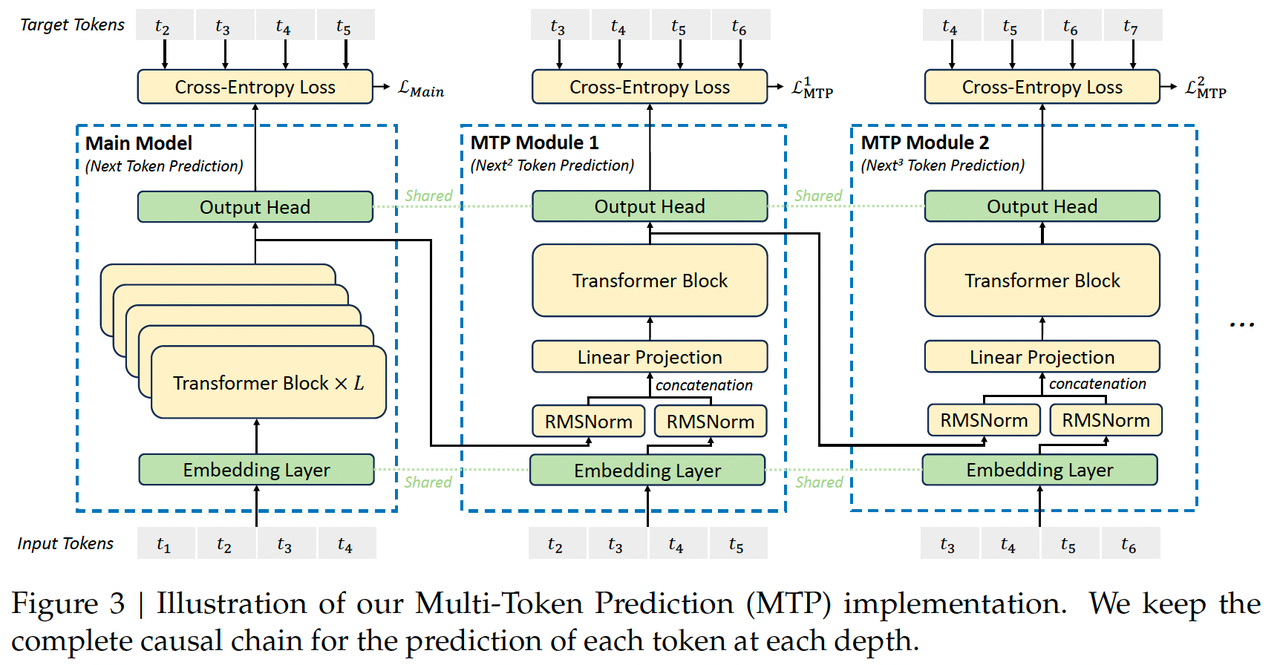
一个MTP模块中包含一个共享的嵌入(embedding)层Emb(·),共享的输出层OutHead(·),transformer block TRM_k(·),投影矩阵M_k,参数大小dx2d。
该模块的输入为上一层的输入$h_i^{k-1} \in \mathcal{R}^d$与输入token中的第i+k个token的嵌入$Emb(t_{i+k})\in \mathcal{R}^d$各自经过RMSNorm后的拼接,随后再经过一个线性层得到最终输入。公式如下:![]()
这个输入经过transformer block得到输出。![]()
这个过程中使用了滑动窗口的技术,只关注从1:t-k之间的 token。
随后利用OutHead()计算第k个预测token的概率分布, ,其中V是指词表的长度:
![]()
MTP的训练目标函数:
使用交叉熵损失函数计算预测的概率分布和真实token之间的差异,平均每个MTP的loss并乘以一个参数\lambda来获得最后的MTP loss,作为dsv3的一个额外损失项。
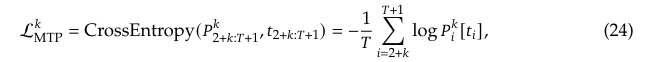

MTP推理:
在推理过程中,可以直接禁用MTP模块,只使用主模型进行token预测。同时,也可以考虑使用MTP模块来提升生成的速度,降低延迟。(在主模型生成之前提前生成可能的结果,降低模型的计算负担。)
归一化方法
DeepSeek-V3使用了RMSNorm(Root Mean Square Layer Normalization)进行归一化,具体步骤如下:
-
RMSNorm:对每个特征维度进行归一化,计算每个特征的均方根值,并用该值进行缩放。
公式表示如下:
其中,x 是输入,N 是特征维度,是小的常数,以避免除以零。
预训练
DeepSeek-V3的预训练流程是一个多阶段的过程,涉及数据构建、超参数设置、长上下文扩展和评估等多个步骤。以下是详细的介绍:
预训练流程
数据构建:
-
数据来源:预训练数据集包含14.8万亿个多样化的高质量标记。数据集为多语言的语料(Deepseek-v2训练时仅包含英文和中文语料)。同时,增加了语料中的数学和程序样本。
question:训练过程中每次输入的内容长度相同,但是样本的长度是不同的,dsv3如何处理不等长的样本?采用Fewer truncations improve language modeling文章中的方法,对于一个批次中的数据,在尽可能减少同一个样本截断的前提下,将部分短样本与短样本或长样本末尾截断的部分进行拼接,保证单一样本尽可能完整。(下图中的best-fit packing方法)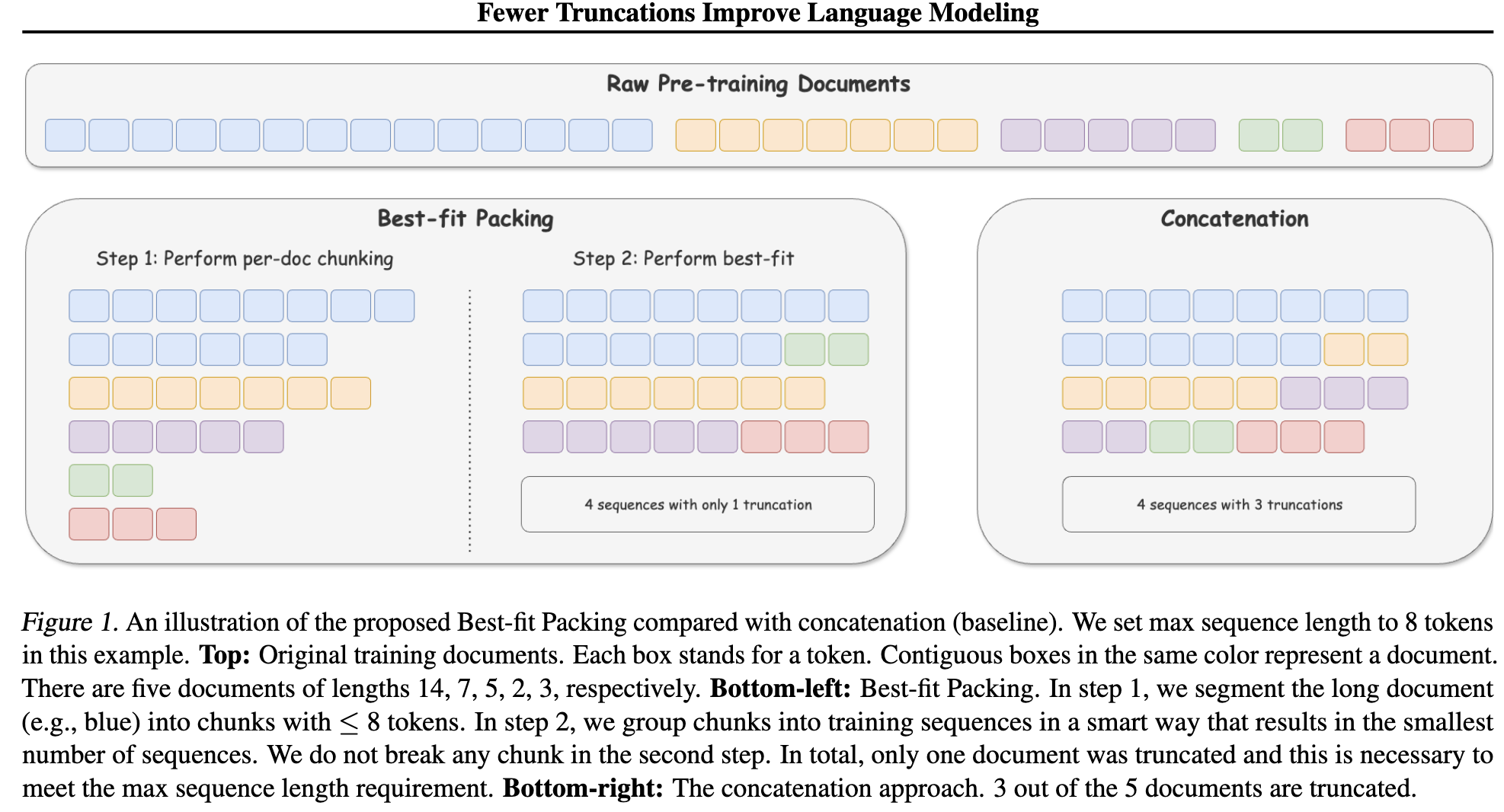
Fewer truncations improve language modeling[3]中的best-fit packing方法 -
FIM(Fill-in-Middle)策略:采用Prefix-Suffix-Middle(PSM)框架,结构化数据为
question:为什么用这种策略?<|fim_begin|> pre<|fim_hole|> suf<|fim_end|> middle<|eos_token|>(模型的目标是根据pre和suf的内容,预测<|fim_hole|>标记部分的内容,这部分内容的gt值保存在middle处。),FIM策略的应用率为0.1(即10%的训练样本采用这种形式)。- 在DeepSeekCoder-V2模型的训练过程中证明了这种方式不会影响模型next token预测的能力,同时还会提升模型基于上下文预测中间text的能力;
- 另外,这种方式直观上讲,会提升模型对双向上下文的理解能力。
-
数据处理:使用字节级BPE(Byte-level BPE)分词器,词汇量为128K。数据处理流程经过优化,以减少冗余并保持数据多样性。
-
超参数设置:
-
模型参数:Transformer层数为61,隐藏维度为7168。MLA中,注意力头数为128,每个头的维度为128,KV压缩维度为512,query压缩维度为1536。对于解耦的q和k,每个头的维度设置为64。
为什么kv的压缩维度比query的小?-
Query 的动态生成特性:Query 在每个解码步骤中动态计算,无需缓存历史结果,因此可保留更高维度(1536 维)以维持语义表达能力。
-
KV 的缓存特性:KV 在推理阶段被重复使用,其压缩维度直接影响显存瓶颈。选择 512 维可显著降低内存占用,使模型能处理超长上下文(如 128K Token)。
-
-
模型设置:除了前三个FFN为传统FFN外,其他所有的都设置为MoE层。每个MoE层包含一个共享expert和256个路由专家,专家的中间隐藏层维度为2048。在路由专家中,每个token激活8个experts,每个token会被确保最多仅送到4个节点。MTP深度D设置为1,即除了要预测下一个token外,还要再额外预测一个token。
-
训练参数:使用AdamW优化器,学习率从0线性增加到2.2×10^-4,然后保持不变,直到模型消耗10T训练标记。之后,学习率逐渐衰减到2.2×10^-5。(更详细的参数设置请参考原文)
-
-
长上下文扩展:
-
YaRN方法:使用YaRN方法将上下文窗口从4K扩展到32K,然后进一步扩展到128K。每个阶段包含1000步训练。
-
在训练过后,使用YaRN方法额外训练两个训练阶段,每一个包含1000训练步,扩展上下文窗口,从4K到32K再到128K。
-
超参数:在扩展阶段,序列长度分别设置为32K和128K,批量大小分别为1920和480。学习率保持为7.3×10^-6。
-
-
评估:
-
基准测试:使用多种基准测试评估模型性能,包括多选题、语言理解、阅读理解、代码和数学等。
-
评估结果:DeepSeek-V3在多个基准测试中表现优异,尤其是在代码和数学任务上。
-
损失函数
-
交叉熵损失:
-
输入输出:模型的输入是标记序列,输出是每个标记的概率分布。
-
损失计算:使用交叉熵损失函数计算预测概率分布和真实标记之间的差异。具体公式为:
其中,
是真实标记的独热编码,
是模型预测的概率。
-
-
多标记预测(MTP)损失:
-
MTP模块:在每个预测深度,模型预测多个未来标记。具体实现是将当前标记的表示和下一个标记的嵌入组合,通过Transformer块生成输出表示。
-
损失计算:对于每个预测深度,计算交叉熵损失,并将所有深度的MTP损失平均后乘以权重因子,得到总的MTP损失:
-
,
其中,D是预测深度, 是权重因子。
模型输入输出
-
输入:模型的输入是标记序列,经过分词器处理后转换为嵌入向量。
-
输出:模型的输出是每个标记的概率分布,用于计算损失函数和生成文本。
通过这些步骤和方法,DeepSeek-V3在预训练阶段能够高效地学习语言模式,并在多个基准测试中表现出色。
后训练
DeepSeek-V3的后训练流程主要包括两个阶段:监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL)。以下是这两个阶段的具体方法、使用的损失函数以及训练过程中的损失计算方式:
监督微调(SFT)
监督微调过程中使用指令调整数据集,增强模型的指令遵循能力。
-
数据准备:
-
推理数据:
-
DeepSeek-V3的指令调整数据集包含1.5M个实例,覆盖多个领域,每个领域的数据都是基于领域的特定需求构建的。
-
对于推理相关数据集(如数学、编程竞赛问题和逻辑谜题),使用内部DeepSeek-R1模型生成数据。这些数据虽然准确性高,但可能存在过度思考、格式不佳和长度过长的问题。因此,目标是在保持R1生成数据的准确性的同时,平衡数据的清晰度和简洁性。这个目标通过对每个领域的数据独立训练一个专家模型来实现,训练步骤包括SFT和RL。这些专家模型会作为最终的数据生成器。通过这样的训练过程,确保生成的数据在保留R1的推理能力的同时,生成简洁且有效的数据。
-
训练过程:
-
SFT:首先对每个实例生成两种类型的回复,原始的回复格式为 <problem, original response>,第二种结合系统prompt,问题和R1回复,格式为:<system prompt, problem, R1 response>。这种系统提示经过精心设计,包含了引导模型生成富含反思和验证机制回复的指令。
-
RL:在强化学习阶段,即使没有明确的系统提示,模型也会利用高温采样生成融合 R1 生成数据和原始数据模式的回复。经过数百步强化学习后,中间的强化学习模型学会融入 R1 模式,从而提升整体性能。
-
-
-
-
非推理数据(如创意写作、角色扮演和简单问答):
-
使用DeepSeek-V2.5生成响应,并由人类标注者验证数据的准确性和正确性。
-
-
-
训练设置:
-
使用SFT数据集对DeepSeek-V3-Base进行两轮微调,采用余弦衰减学习率调度,从5 × 10^-6开始逐渐降低到1 × 10^-6。
-
在训练过程中,将多个样本打包成单个序列,但采用样本掩码策略,确保这些样本在训练时相互独立且不可见。
-
-
损失函数:
-
使用交叉熵损失(Cross-Entropy Loss)来计算模型输出和真实标签之间的差异。
-
强化学习(RL)
-
奖励模型(Reward Model, RM):
-
规则基RM(Rule-based RM):对于可以通过特定规则验证的问题(如数学问题和编程问题),使用规则基奖励系统来确定反馈。例如,某些数学问题有确定的结果,模型需要在指定格式内提供最终答案,从而可以应用规则进行验证。
-
模型基RM(Model-based RM):对于自由形式的真实答案问题,依赖奖励模型来确定响应是否与预期的真实答案匹配。对于没有明确真实答案的问题(如创意写作),奖励模型根据问题和对应答案提供反馈。奖励模型从DeepSeek-V3的SFT检查点训练而来,通过构建偏好数据来增强其可靠性。
-
-
组相对策略优化(Group Relative Policy Optimization, GRPO):
-
GRPO方法不依赖于与策略模型大小相同的Critic模型(降低开销),而是从组分数中估计基线。具体来说,对于每个问题,GRPO从旧策略模型中采样一组输出,然后通过最大化以下目标来优化策略模型:
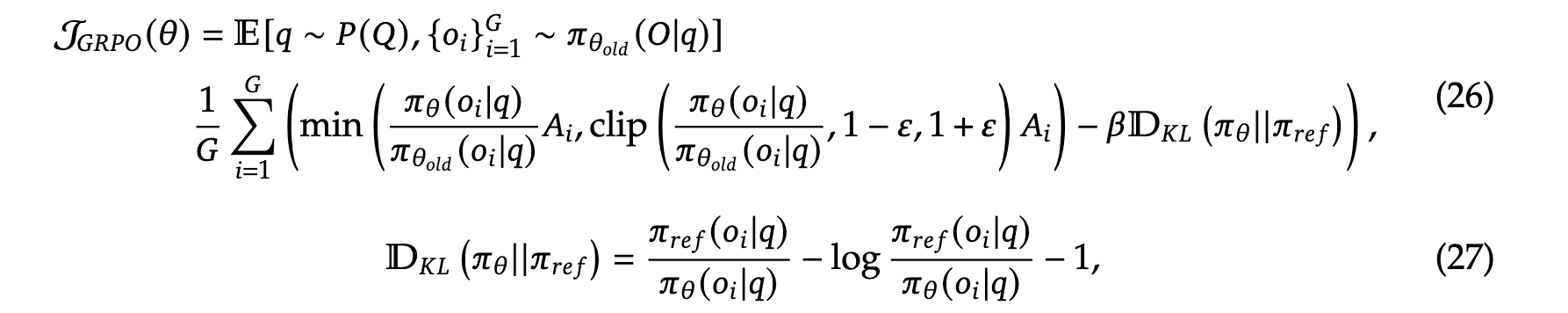 其中,\(\epsilon\) 和 \(\beta\) 是超参数;\(\pi_{\theta'}\) 是参考模型;\(A_i\) 是优势,由每个组内的输出对应的奖励 \(\{r_1, r_2, \ldots, r_A\}\) 计算得出:
其中,\(\epsilon\) 和 \(\beta\) 是超参数;\(\pi_{\theta'}\) 是参考模型;\(A_i\) 是优势,由每个组内的输出对应的奖励 \(\{r_1, r_2, \ldots, r_A\}\) 计算得出: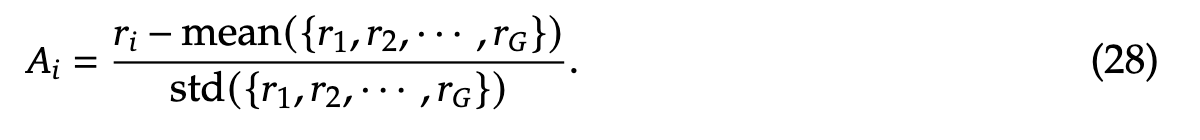
-
-
损失函数:
-
在RL过程中,使用奖励模型计算的奖励来更新策略模型。具体来说,使用上述GRPO目标函数来计算损失,并通过优化这个目标函数来更新模型参数。
-
模型的输入输出
-
输入:模型的输入是经过预处理的文本数据,这些数据可以是自然语言文本、代码片段、数学问题等。
-
输出:模型的输出是生成的文本,这些文本可以是回答、代码、数学解题步骤等,具体取决于输入的任务类型。
通过上述方法,DeepSeek-V3在后训练阶段能够更好地适应人类的偏好,并进一步释放其潜力。
参考资料:
[1] deepseekv3技术报告: https://arxiv.org/pdf/2412.19437
[2] deepseek v3官方github仓库: https://github.com/deepseek-ai/DeepSeek-V3
[3] Ding et al, Fewer truncations improve language modeling: https://arxiv.org/pdf/2404.10830

















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









