






jdk8-21特性
核心特征:
(8)lambda,stream api,optional,方法引用,函数接口,默认方法,新时间Api,函数式接口,并行流,ComletableFuture。
(9)模块系统,jshell命令工具直接写java代码,集合的of方法,接口的private方法,Stream的takeWhile和dropWhile,多版本兼容jar,optional新增ifPresentOfElse(),or(),更强大的
ProcessHandle获取进程信息,响应式流。(10)var局部变量类型推断,不可变集合的增强(CopyOf),Optional.orElseThrow(),并行全垃圾回收器(G1),DK默认包含CA根证书,支持TLS安全通信, 线程本地握手,版本号改为基于发布周期(如
10.0.1),非之前的1.8.0_291格式(11)HTTP Client API(正式版),允许在Lambda表达式中使用
var声明参数(需显式注解@NonNull等),字符串增强方法isBlank()、lines()、repeat(),新的文件读写方法(Files类),直接运行.java文件(无需先编译),Epsilon垃圾回收器,JVM内部优化,允许嵌套类直接访问彼此的私有成员,JVM新增CONSTANT_Dynamic常量池类型,提升动态语言支持,移除Java EE和CORBA模块(如javax.xml.ws),原商业版JFR成为开源功能,用于低开销性能监控。(12-16)简化
switch语法,支持返回值和多标签匹配,Shenandoah GC低停顿时间的垃圾回收器,适合大堆内存应用,Microbenchmark Suite(JMH集成)JDK内置微基准测试工具,简化多行字符串书写,避免转义符String json = """ { "name": "Java", "version": 13 } """;动态CDS归档,底层NIO实现优化,提升性能,instanceof模式匹配(预览)直接类型转换,减少冗余代码,Record类(预览),NullPointerException增强,明确提示NPE发生的具体变量,ZGC(生产就绪)。
(17)record类,密封类,隐藏类,模式匹配,文本块,swith增强,新ZGC/Shenandoah GC,弃用Applet API,强封装JDK内部API,伪随机数生成器(新API),移除实验性AOT和JIT编译器,外部函数和内存API(孵化器模块)
(18-20)默认UTF-8字符集,简易Web服务器(jwebserver)
(21)虚拟线程,记录模式,匹配模式再增强,分代ZGC,有序集合,外部函数与内存API, 弃用Windows 32位安装包,密钥封装机制API(KEM)
jvm
内存模型:本地方法栈,pc register,虚拟机栈,堆
作用:
堆:
类加载器的双亲委派机制:
加载流程:
gc
有哪些垃圾回收器:
gc算法:
一、G1垃圾回收器(Garbage-First)
1. 核心设计目标
- 取代CMS:作为JDK 9+的默认GC,平衡吞吐量和低延迟。
- 适用场景:大内存(数十GB)、要求稳定停顿时间(如200ms内)。
2. 关键算法
分代分区(Region-Based)
将堆划分为等大小(1MB~32MB)的Region,每个Region可以是Eden、Survivor、Old或Humongous(存放大对象)。标记-整理 + 复制混合算法
- 标记阶段:并发标记存活对象(SATB算法处理并发修改)。
- 回收阶段:优先回收垃圾最多的Region(Garbage-First原则),将存活对象复制到空闲Region(整理效果)。
停顿预测模型
根据历史数据预测每次回收的耗时,动态调整回收Region数量以控制停顿时间。3. 工作流程
- 初始标记(STW):标记GC Roots直接关联对象。
- 并发标记:遍历对象图,SATB记录并发修改。
- 最终标记(STW):处理剩余SATB记录。
- 筛选回收(STW):选择高收益Region复制整理。
4. 优缺点
优点 缺点 可控停顿时间 内存占用较高(约堆的10%~20%) 避免Full GC(通过并发标记) 小堆场景不如Parallel GC高效
二、ZGC垃圾回收器(Z Garbage Collector)
1. 核心设计目标
- 超低延迟:目标停顿<10ms(TB级堆),JDK 15+正式生产可用。
- 全并发性:仅初始标记需短暂STW。
2. 关键算法
染色指针(Colored Pointers)
在指针元数据中存储标记信息(而非对象头),64位指针划分:
[18位未用 | 1位Finalizable | 1位Remapped | 1位Marked1 | 1位Marked0 | 42位地址]读屏障(Load Barrier)
访问对象时检查指针颜色,若需处理则触发即时修正(如对象移动后更新指针)。并发压缩(Concurrent Compaction)
通过对象转移表(Forwarding Table)实现对象移动与引用更新完全并发。3. 工作流程
- 初始标记(STW):标记GC Roots(约1ms)。
- 并发标记:遍历对象图,染色指针记录存活。
- 并发预备重分配:确定回收区域。
- 并发重分配:移动对象并更新引用(通过读屏障)。
- 并发重映射:修正旧引用指向新地址。
4. 优缺点
优点 缺点 亚毫秒级停顿 JDK 16+才支持Windows/macOS 吞吐量损失<15%(相比G1) 暂不支持分代(ZGC Generational在JDK 21实验)
三、对比总结
维度 G1 ZGC 最大堆 数十GB 4TB+ 停顿时间 100~500ms <1ms 算法核心 分区回收 + 停顿预测 染色指针 + 读屏障 适用版本 JDK 7+(9+默认) JDK 11+(15+生产) 分代支持 是 否(实验性)
四、选型建议
- G1:中等堆(<32GB)、兼顾吞吐量与延迟(如Web服务)。
- ZGC:超大堆、极致低延迟(如金融交易系统)。
- Shenandoah:OpenJDK的替代选择,类似ZGC但兼容JDK 8+。
arthas
内存泄漏定位过程以及使用的命令:
确认泄漏现象 → 定位TOP对象 → 追踪引用链 → 监控增量 → 分析创建路径 → 生成堆转储 → 修复代码 → 验证回收
# 查看JVM内存实时状态(重点关注Old Gen)
dashboard -i 3000 -n 3 | grep -E 'Heap|Old Gen'# 监控GC活动(频繁Full GC是泄漏标志)
jvm | grep -A 5 'GC'# 统计堆内存中对象数量TOP 10(立即执行)
memory --classloader -t 10# 示例输出(泄漏对象通常数量异常):
# com.example.CacheEntry 1,234,567 1.2GB
# java.util.HashMap$Node 890,123 450MB
# 获取对象实例地址(以com.example.CacheEntry为例) vmtool --action getInstances --className com.example.CacheEntry --limit 1 # 输出实例地址后,追踪GC Roots引用路径 ognl '@com.taobao.arthas.core.advisor.Advice@toGCRoots(<INSTANCE_ADDRESS>)'# 每30秒统计一次泄漏对象的增量(持续观察)
monitor -c 30 -n 5 'java.lang.Class getInstancesCount "com.example.CacheEntry"'# 动态观察对象创建堆栈(关键!)
stack com.example.CacheManager "addEntry" -n 10
# 生成轻量级堆转储(建议低峰期执行)
heapdump --live /tmp/leak_snapshot.hprof# 仅dump可疑对象(减少文件大小)
heapdump --include com.example.CacheEntry /tmp/partial_dump.hprof
# 检查对象是否被正确释放(对比操作前后)
watch com.example.CacheService clearCache '{params,returnObj,throwExp}' -n 5 -x 3# 追踪对象finalize情况
trace java.lang.Object finalize -n 5
- 临时缓解:通过Arthas强制清除泄漏集合(慎用!)
ognl '@com.example.CacheManager@clearAll()'- 立即告警:当Old Gen使用率超过90%时触发告警
jvm | grep 'Old Gen' | awk '{if($3>90) print "ALERT"}'cpu过高:
dashboard -i 2000 -n 3
thread -n 5前五个cpu占用最高的完整堆栈 最忙的5个线程的堆栈(推荐)
thread -b看哪里阻塞死锁堆栈
thread pid查看指定线程的完整堆栈
watch com.example.aa.类名 方法名 '{params,returnObj,throwExp}' -n 5 -x 3通过输出最近5次方法的调用查看这个方法的参数返回和异常
trace 类名 方法名 -n 5过输出最近5次方法调用查看方法得耗时
stack 类名 方法名 -n 5通过输出最近5次方法的调用栈 查看被哪里调用了
monitor -c 10 -n 5 'java.lang.Class getInstancesCount "com.example.*"' 每10秒统计一次类实例数(持续监控)
jad 类名 反编译看下代码是不是没更新
# 1. 启动采样(默认30秒)
profiler start# 2. 停止采样生成SVG
profiler stop --format svg# 3. 下载文件并用浏览器打开
其它场景:
线程
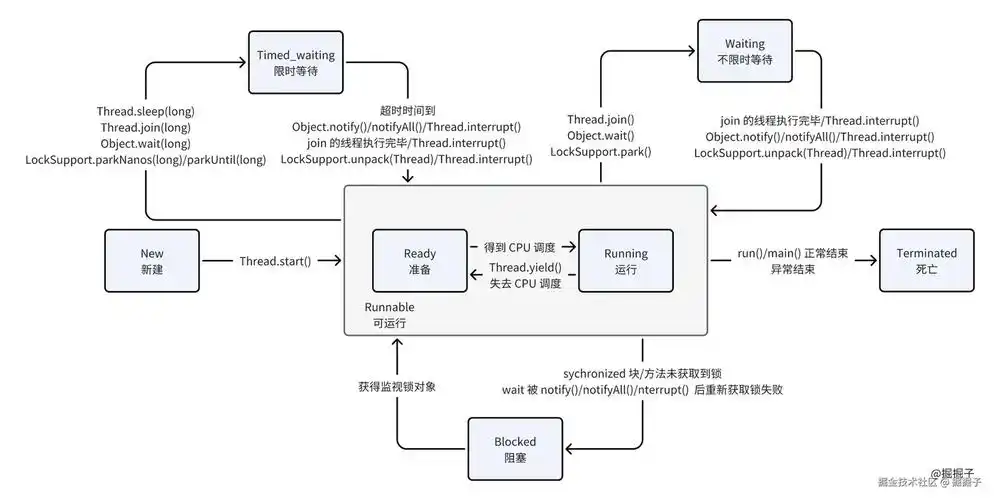
生命周期:
线程池:
java原生包:java.util.concurrent.Executor创建线程池:固定线程数的,单线程的,带缓存的,周期性执行的,自定义的,jdk7开始有的ForkJoinPool spring封装:
org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor
org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor
每个参数的意思:
拒绝策略:
CallerRunsPolicy是不是立即调用:
匹配队列:
ThreadLocal原理以及常见问题:
Volitale原理:
指令重排原理:
锁
乐观锁:
mybatis-plus中@Version乐观锁,通过拦截器从写sql语句,自动管理版本号,可通过异常捕获后添加补偿机制,version字段添加索引来优化
悲观锁:
synchronized(用在方法和代码块上)
synchronized实现线程安全的核心机制可以这样理解: 对象监视器(Monitor)机制 每个Java对象都关联一个隐藏的Monitor对象 Monitor包含三个关键组件: Owner:记录当前持有锁的线程 EntryList:竞争锁的线程队列 WaitSet:调用wait()的等待线程队列 锁状态转换系统 无锁 → 偏向锁(首次获取时) 偏向锁 → 轻量级锁(出现竞争时) 轻量级锁 → 重量级锁(竞争加剧时) 通过对象头中的Mark Word标志位标识当前锁状态 内存屏障保障 在monitorenter和monitorexit处插入内存屏障 保证同步块内的操作不会被重排序到同步块外 确保锁释放时所有修改对后续获取锁的线程可见 互斥访问控制 通过CAS操作竞争锁所有权 失败线程进入阻塞状态(重量级锁) 依赖操作系统mutex实现线程挂起/唤醒 可重入设计 通过_recursions计数器记录重入次数 每次退出同步块只减少计数器 计数器归零时才真正释放锁 这些机制共同保障了: 原子性:同步块内的操作不可分割 可见性:锁释放时强制写回主内存 有序性:防止指令重排序破坏同步语义ReentrantLock
ReentrantReadWriteLock
CountDownLatch 倒计时锁 countdown() await()
StampedLock (Java8+)
分布式锁(redission,zk)
AQS(AbstractQueuedSynchronizer)深度解析 AQS是Java并发包中的核心框架,你可以把它想象成一个"并发控制的乐高积木",它提供了构建锁和同步器的标准化模板。以下是它的核心要点: 1. AQS的本质 🧩 同步器骨架: 位于java.util.concurrent.locks包 采用模板方法设计模式 提供同步状态管理的通用实现 支持独占和共享两种模式 2. 核心组成 ⚙️ 三大核心部件: state(volatile int):同步状态的核心字段 CLH队列:线程等待队列(双向链表实现) ConditionObject:条件变量实现 3. 工作原理 🔄 工作流程: 线程尝试获取锁(修改state) 成功则执行,失败则进入等待队列 前驱节点释放时会唤醒后继节点 被唤醒线程再次尝试获取锁 4. 为什么锁都依赖AQS 🔗 设计优势: 复用性强:只需实现tryAcquire/tryRelease等模板方法 性能优异:CAS操作+自旋优化 功能完备:支持中断、超时、公平/非公平等特性 扩展性强:可构建各种同步工具 5. 典型实现 📚 基于AQS的同步器: ReentrantLock Semaphore CountDownLatch ReentrantReadWriteLock FutureTask等 6. 关键源码简析 java Copy Code // 获取独占锁的典型流程 public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); } AQS通过这种精巧的设计,成为了Java并发包的基石。理解AQS是掌握Java并发编程的关键一步,它就像并发世界中的"操作系统内核",为上层同步工具提供了稳定高效的基础设施。
事务
acid:
脏读:
不可重复读:
幻读:
事务隔离级别:
spring事务原理和流程:
分布式事务原理和流程:
MySQL中InnoDB存储引擎如何解决幻读?
如何防止脏读、不可重复读和幻读?
脏读、不可重复读和幻读哪个更严重?
mysql
函数:
索引:
事务:
锁:
存储结构:
同步机制:
优化:
redis
数据类型:
缓存击穿:
缓存穿透:
缓存雪崩:
分布式锁实现原理:
lua:
redis与mysql的同步机制与原理:
mongodb
存储格式:
索引:
优化:
原理:
rocketmq / kafka
角色:
消息路由:
顺序消费如何保证:
重试队列机制:
死信队列机制:
背压机制:
sharding-jdbc
大数据分库分表方案:
具体配置:
spring全家桶
如何理解spring:
1. Spring IOC容器是什么?有什么作用?实现机制是什么?
2. IOC和依赖注入Dl的区别是什么?
3. AOP是什么?用在什么场景?与AspectJ Aop有什么区别?
4. AOP的底层原理是什么?
5. 创建 Spring Bean的方法有哪些?
6. 注入Bean的注解有哪些?@Autowired和@Resource的区别是什么?
7. Bean的生命周期?
8. Bean的作用域有哪些?
9. Spring中的单例 Bean是线程安全的吗?
10. 有几种依赖注入方式?
11. Spring事务是什么?有几种类型?
12. Spring中的事务是如何实现的?13. Spring事务的传播机制有哪些?
14. Spring如何解决循环依赖?
15. Spring中用到了那些设计模型?16. SpringMVC是如何处理一个请求的?
1. 谈谈你对SpringBoot的理解,它有哪些特性?
2. Spring和SpringBoot的关系和区别?
3. SpringBoot的核心注解?
4. SpringBoot的自动配置原理?
5. 为什么SpringBoot的jar能直接运行?
6. SpringBoot的启动原理?
7. SpringBoot内置tomcat启动原理?
8. SpringBoot打war包,外部tomcat启动原理?
9. 什么是Spring Profiles?
10. Spring Boot中的监视器?
11. SpringBoot是否可以使用xml配置?
12. 什么是yml?
13. SpringBoot的配置文件加载原理?
14.
如何理解springboot:
springboot如何优化启动速度和内存占用量:
springcloud有哪些组件:
springcloudalibaba有哪些组件:
版本对应问题:
nacos:
openfeign:
setinel:
loadbalance:
seata:
es
归档方案:
复杂的查询语句:
ik分词器原理:
算法
令牌桶思想算法
漏桶思想算法
设计模式
单例:
工厂:
策略:
发布订阅:
责任链:
装饰器:
适配器模式:

















 4819
4819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









