






*重要工具Impala
介绍
Impala是Cloudera提供的⼀一款开源的针对HDFS和HBASE中的PB级别数据进⾏交互式实时查询的一个分布式,大规模并行处理(MPP)数据库引擎,它包括多个进程。最大卖点就是快。
Impala 抛弃了了 MapReduce 使⽤了类似于传统的MPP 数据库技术 ,大大提⾼了查询的速度。MPP (Massively Parallel Processing) ,就是⼤大规模并行处理理,在 MPP 集群中,每个节点资源都是独⽴享有也就是有独⽴立的磁盘和内存,每个节点通过⽹网络互相连接,彼此协同计算,作为整体提供数据服务。简单来说, MPP 是将任务并⾏的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的 结果汇总在⼀一起得到最终的结果对于 MPP 架构的软件来说聚合操作⽐比如计算某张表的总条数,则先进⾏局部聚合 ( 每个节点并⾏计算 ) ,然后把局部汇总结果进⾏行行全局聚合( 与 Hadoop 相似 ) 。Impala 与 Hive 对⽐Impala 的技术优势
- Impala没有采取MapReduce作为计算引擎,MR是⾮非常好的分布式并⾏行行计算框架,但MR引擎更更多的是⾯面向批处理理模式,⽽而不是面向交互式的SQL执行。与 Hive相⽐比:Impala把整个查询任务转为一棵执行计划树,而不是一连串的MR任务,在分发执行计划后,Impala使⽤拉取的方式获取上个阶段的执行结果,把结果数据、按执行树流式传递汇集,减少的了把中间结果写⼊入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MR启动时间。
- 使用LLVM(C++编写的编译器器)产生运行代码,针对特定查询生成特定代码。
- 优秀的IO调度,Impala支持直接数据块读取和本地代码计算。
- 选择适合的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
- 尽可能使用内存,中间结果不写磁盘,及时通过网络以stream的⽅方式传递。
安装配置
Impala ⻆角⾊色
- impala-server:这个进程是Impala真正⼯工作的进程,官⽅方建议把impala-server安装在datanode节点,更靠近数据(短路路读取),进程名impalad
- impala-statestored:健康监控⻆角⾊色,主要监控impala-server,impala-server出现异常时告知给其它impala-server;进程名叫做statestored
- impala-catalogd :管理理和维护元数据(Hive),impala更更新操作;把impala-server更更新的元数据通知给其它impala-server,进程名catalogd
官⽅方建议 statestore 与 catalog 安装在同⼀一节点上!!⭐⭐⭐HIVE要集群模式 开启Metastore 建议Matestore与impala-server在一个机子linux3安装:yum install impala -yyum install impala-server -yyum install impala-state-store -yyum install impala-catalog -yyum install impala-shell -ylinux1 linux2 安装yum install impala-server -yyum install impala-shell -ylinux3启动nohup hive --service metastore &linux1启动nohup hive --service hiveserver2 &短路路读取:就是 Client 与 DataNode 属于同⼀一节点,⽆无需再经过⽹网络传输数据,直接本地读取。所有impala节点执行命令:ln -s /opt/lxq/servers/hadoop-2.9.2/etc/hadoop/core-site.xml/etc/impala/conf/core-site.xmlln -s /opt/lxq/servers/hadoop-2.9.2/etc/hadoop/hdfs-site.xml/etc/impala/conf/hdfs-site.xmlln -s /opt/lxq/servers/hive-2.3.7/conf/hive-site.xml/etc/impala/conf/hive-site.xml所有节点修改:vim /etc/default/impala<!-- 更更新如下内容 -->IMPALA_CATALOG_SERVICE_HOST=linux123IMPALA_STATE_STORE_HOST=linux123MYSQL_CONNECTOR_JAR=/usr/share/java/mysql-connector-java.jar所有节点创建:# 所有节点 创建节点,并建立软连接mkdir -p /usr/share/javaln -s /opt/lxq/servers/hive-2.3.7/lib/mysql-connector-java-5.1.46.jar/usr/share/java/mysql-connector-java.jarvim /etc/default/bigtop-utilsexport JAVA_HOME = /opt/lxq/servers/jdk1.8.0_231#linux123 启动如下⻆角⾊色service impala-state-store startservice impala-catalog startservice impala-server start# 其余节点启动如下⻆角⾊色service impala-server startps -ef | grep impala访问 impalad 的管理理界⾯面http://linux123:25000/访问 statestored 的管理理界⾯面http://linux123:25010/启动之后所有关于 Impala 的⽇日志默认都在 /var/log/impala 这个路路径下, Linux123 机器器上⾯面应该有三个进程,Linux121 与 Linux122 机器器上⾯面只有⼀一个进程,如果进程个数不不对,去对应⽬目录下查看报错⽇日志.Impala会附带安装一些其它东西,要删除[root@linux122 conf] # which hadoop/usr/bin/hadoop[root@linux122 conf] # which hive/usr/bin/hivewhich 命令 查找 hadoop,hive 等会发现,命令文件是 /usr/bin/hadoop ⽽非我们自己安装的路径,需要把这些删除掉 , 所有节点都要执⾏[root@linux122 conf] # which hadoop/usr/bin/hadoop[root@linux122 conf] # which hive/usr/bin/hiverm -rf /usr/bin/hadooprm -rf /usr/bin/hdfsrm -rf /usr/bin/hiverm -rf /usr/bin/beelinerm -rf /usr/bin/hiveserver2# 重新⽣生效环境变量量source /etc/profile
进入impala命令: impala-shell
impala的操作流程更HIVE差不多,就不多重复写了
原理
查询原理
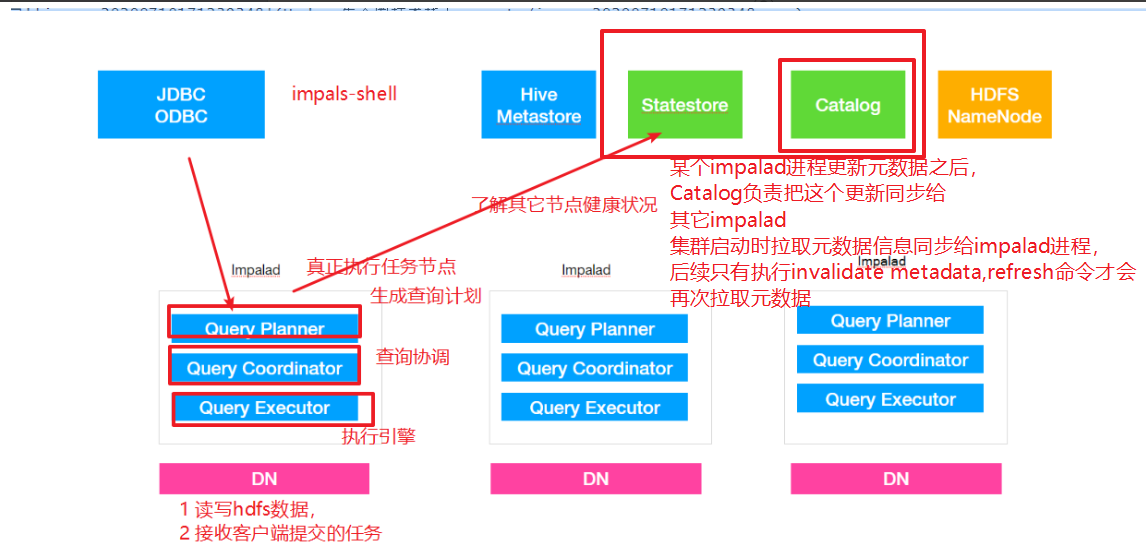
impalad
- 作⽤用,负责读写数据⽂文件,接收来⾃自Impala-shell,JDBC,ODBC等的查询请求,与集群其它Impalad分布式并行完成查询任务,并将查询结果返回给中心协调者。
- 角色名称为Impala Daemon,是在每个节点上运⾏行行的进程,是Impala的核⼼心组件,进程名是 Impalad;
- 为了保证Impalad进程了了解其它Impalad的健康状况,Impalad进程会一直与statestore保持通信。
- Impalad服务由三个模块组成:Query Planner、Query Coordinator和Query Executor,前两个 模块组成前端,负责接收SQL查询请求,解析SQL并转换成执⾏行行计划,交由后端执⾏行行,
statestored
- statestore监控集群中Impalad的健康状况,并将集群健康信息同步给Impalad,
- statestore进程名为statestored
catalogd
- Impala执行的SQL语句句引发元数据发⽣生变化时,catalog服务负责把这些元数据的变化同步给其它Impalad进程(⽇日志验证,监控statestore进程⽇日志)
- catalog服务对应进程名称是catalogd
- 由于⼀一个集群需要⼀一个catalogd以及⼀一个statestored进程,⽽而且catalogd进程所有请求都是经过statestored进程发送,所以官⽅方建议让statestored进程与catalogd进程安排同个节点。
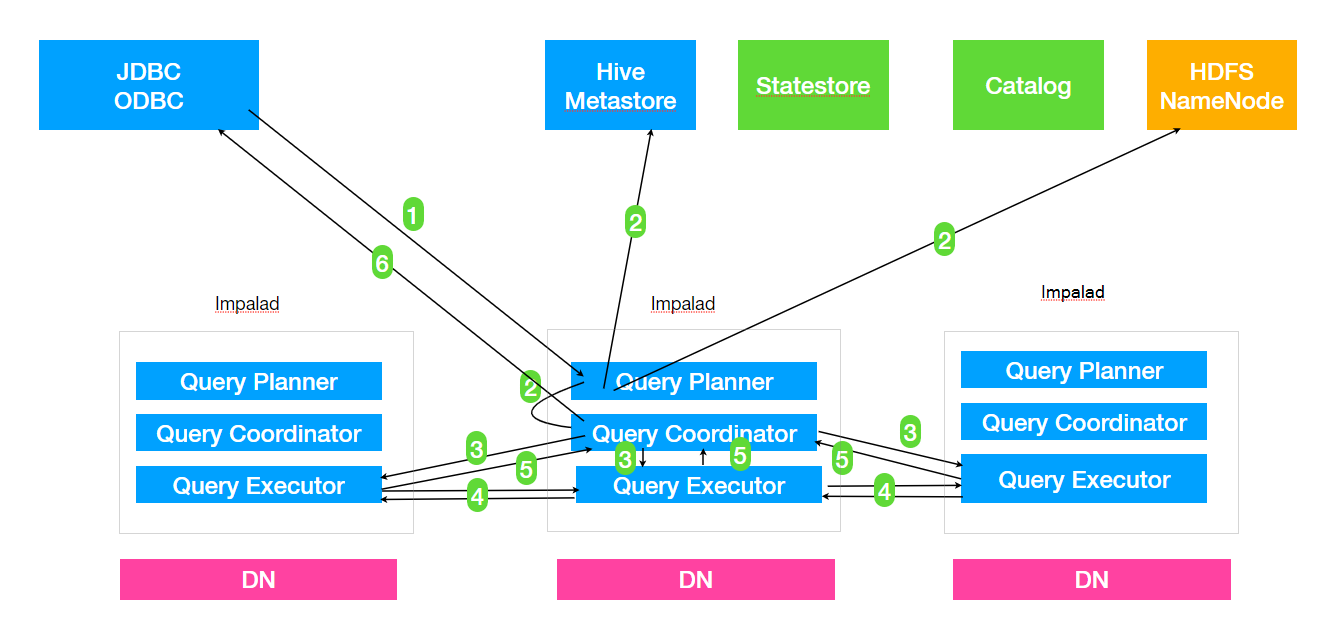
1. Client 提交任务Client 发送⼀一个 SQL 查询请求到任意⼀一个 Impalad 节点,会返回⼀一个 queryId ⽤用于之后的客户端操作。2. ⽣生成单机和分布式执⾏行行计划SQL 提交到 Impalad 节点之后, Analyser 依次执⾏行行 SQL 的词法分析、语法分析、语义分析等操作;从 MySQL 元数据库中获取元数据,从 HDFS 的名称节点中获取数据地址,以得到存储这个查询相关数据的所有数据节点单机执⾏行行计划: 根据上⼀一步对 SQL 语句句的分析,由 Planner 先⽣生成单机的执⾏行行计划,该执⾏行行计划是有 PlanNode 组成的⼀一棵树,这个过程中也会执⾏行行⼀一些 SQL 优化,例例如 Join 顺序改变、谓词下推等。分布式并⾏行行物理理计划:将单机执⾏行行计划转换成分布式并⾏行行物理理执⾏行行计划,物理理执⾏行行计划由⼀一个个的 Fragment 组成, Fragment 之间有数据依赖关系,处理理过程中需要在原有的执⾏行行计划之上加⼊入⼀一些 ExchangeNode 和 DataStreamSink 信息等。Fragment : sql ⽣生成的分布式执⾏行行计划的⼀一个⼦子任务;DataStreamSink :传输当前的 Fragment 输出数据到不不同的节点3. 任务调度和分发Coordinator 将 Fragment( ⼦子任务 ) 根据数据分区信息发配到不不同的 Impalad 节点上执⾏行行。 Impalad节点接收到执⾏行行 Fragment 请求交由 Executor 执⾏行行。4. Fragment 之间的数据依赖每⼀一个 Fragment 的执⾏行行输出通过 DataStreamSink 发送到下⼀一个 Fragment , Fragment 运⾏行行过程中不不断向 coordinator 节点汇报当前运⾏行行状态。5. 结果汇总查询的 SQL 通常情况下需要有⼀一个单独的 Fragment ⽤用于结果的汇总,它只在 Coordinator 节点运⾏行行,将多个节点的最终执⾏行行结果汇总,转换成 ResultSet 信息。6. 获取结果客户端调⽤用获取 ResultSet 的接⼝口,读取查询结果。
优化
⽂文件格式对于⼤大数据量量来说, Parquet ⽂文件格式是最佳的避免⼩小⽂文件insert ... values 会产⽣生⼤大量量⼩小⽂文件,避免使⽤用合理理分区粒度利利⽤用分区可以在查询的时候忽略略掉⽆无⽤用数据,提⾼高查询效率,通常建议分区数量量在 3 万以下( 太多的分区也会造成元数据管理理的性能下降 )分区列列数据类型最好是整数类型分区列列可以使⽤用 string 类型,因为分区列列的值最后都是作为 HDFS ⽬目录使⽤用,如果分区列列使⽤用整数类型可以降低内存消耗获取表的统计指标:在追求性能或者⼤大数据量量查询的时候,要先获取所需要的表的统计指标( 如 : 执⾏行行 compute stats )减少传输客户端数据量量聚合 ( 如 count 、 sum 、 max 等 )过滤 ( 如 WHERE )limit 限制返回条数返回结果不不要使⽤用美化格式进⾏行行展示 ( 在通过 impala-shell 展示结果时,添加这些可选参数 : -B 、 --output_delimiter )在执⾏行行之前使⽤用 EXPLAIN 来查看逻辑规划,分析执⾏行行逻辑Impala join ⾃自动的优化⼿手段就是通过使⽤用 COMPUTE STATS 来收集参与 Join 的每张表的统计信息,然后由 Impala 根据表的⼤大⼩小、列列的唯⼀一值数⽬目等来⾃自动优化查询。为了了更更加精确地获取每张表的统计信息,每次表的数据变更更时 ( 如执⾏行行 Insert,add partition,drop partition 等 ) 最好都要执⾏行行⼀一遍 COMPUTE STATS 获取到准确的表统计信息。
调度工具airflow
以后在更新吧,心累!!!!
Flume
安装配置
下载地址: http://archive.apache.org/dist/flume/vim /etc/profileexport FLUME_HOME = /opt/lxq/servers/flume-1.9.0export PATH = $PATH : $FLUME_HOME /binsource /etc/profilecd $FLUME_HOME /confmv flume-env.sh.template flume-env.shvi flume-env.shexport JAVA_HOME = /opt/lxq/servers/jdk1.8.0_231
source
( 1 ) avro source :监听 Avro 端口来接收外部 avro 客户端的事件流。 avro-source接收到的是经过avro 序列化后的数据,然后反序列化数据继续传输。如果是 avro source的话,源数据必须是经 avro 序列化后的数据。利用 Avro source 可以实现多级流动、扇出流、扇入流等效果。接收通过flume 提供的 avro 客户端发送的日 志信息。( 2 ) exec source :可以将命令产生的输出作为 source 。如 ping 192.168.234.163、 tail -f hive.log 。( 3 ) netcat source :一个 NetCat Source 用来监听一个指定端口,并接收监听到的数据。( 4 ) spooling directory source :将指定的文件加入到 “ 自动搜集 ” 目录中。 flume 会持续监听这个目录,把文件当做source 来处理。注意:一旦文件被放到目录中后,便不能修改,如果修改,flume 会报错。此外,也不能有重名的文件。( 5 ) Taildir Source ( 1.7 ):监控指定的多个文件,一旦文件内有新写入的数据,就会将其写入到指定的sink 内,本来源可靠性高,不会丢失数据。其不会对于跟踪的文件有任何处理,不会重命名也不会删除,不会做任何修改。目前不支持Windows系统,不支持读取二进制文件,支持一行一行的读取文本文件。
channel
( 1 ) memory channel :缓存到内存中(最常用)( 2 ) file channel :缓存到文件中( 3 ) JDBC channel :通过 JDBC 缓存到关系型数据库中( 4 ) kafka channel :缓存到 kafka 中
sink
( 1 ) logger sink :将信息显示在标准输出上,主要用于测试( 2 ) avro sink : Flume events 发送到 sink ,转换为 Avro events ,并发送到配置好的hostname/port 。从配置好的 channel 按照配置好的批量大小批量获取 events( 3 ) null sink :将接收到 events 全部丢弃( 4 ) HDFS sink :将 events 写进 HDFS 。支持创建文本和序列文件,支持两种文件类型压缩。文件可以基于数据的经过时间、大小、事件的数量周期性地滚动( 5 ) Hive sink :该 sink streams 将包含分割文本或者 JSON 数据的 events 直接传送到Hive 表或分区中。使用 Hive 事务写 events 。当一系列 events 提交到 Hive 时,它们马上可以被Hive 查询到( 6 ) HBase sink :保存到 HBase 中( 7 ) kafka sink :保存到 kafka 中
样例:
# 定义Agent名称和组件
agent.sources = netcat-source
agent.channels = file-channel
agent.sinks = logger-sink
# Netcat Source配置(带事务参数)
agent.sources.netcat-source.type = netcat
agent.sources.netcat-source.bind = 0.0.0.0
agent.sources.netcat-source.port = 44444
agent.sources.netcat-source.channels = file-channel
agent.sources.netcat-source.batchSize = 100 # 每批处理事件数
agent.sources.netcat-source.transactionCapacity = 1000 # 事务容量
agent.sources.netcat-source.ackEveryEvent = true # 每个事件单独确认
# 自定义拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.dsj.lxq.flumedemo.LogTypeInterceptor$Builder
# 文件通道配置(持久化事务支持)
agent.channels.file-channel.type = file
agent.channels.file-channel.checkpointDir = /var/lib/flume/checkpoint
agent.channels.file-channel.dataDirs = /var/lib/flume/data
agent.channels.file-channel.capacity = 100000 # 最大事件容量
agent.channels.file-channel.transactionCapacity = 1000 # 单事务最大事件数
agent.channels.file-channel.keep-alive = 30 # 事务超时时间(秒)
agent.channels.file-channel.useDualCheckpoints = true # 双检查点机制
agent.channels.file-channel.backupCheckpointDir = /var/lib/flume/backup
agent.channels.file-channel.checkpointInterval = 30000 # 检查点间隔(ms)
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/%{logtype}/dt=%{logtime}/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
agent.sinks.logger-sink.batchSize = 100 # 每批写入事件数
agent.sinks.logger-sink.transactionCapacity = 1000 # 事务容量
# 监控配置
agent.sources.netcat-source.metrics.type = org.apache.flume.instrumentation.SourceCounter
agent.channels.file-channel.metrics.type = org.apache.flume.instrumentation.ChannelCounter
agent.sinks.logger-sink.metrics.type = org.apache.flume.instrumentation.SinkCounter
自定义拦截器
package ;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.compress.utils.Charsets;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.interceptor.Interceptor;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
// 逐条处理event
public Event intercept(Event event) {
// 获取 event 的 body
String eventBody = new String(event.getBody(), Charsets.UTF_8);
// 获取 event 的 header
Map<String, String> headersMap = event.getHeaders();
// 解析body获取json串
String[] bodyArr = eventBody.split("\\s+");
try {
String jsonStr = bodyArr[6];
// 解析json串获取时间戳
String timestampStr = "";
JSONObject jsonObject = JSON.parseObject(jsonStr);
if (headersMap.getOrDefault("logtype", "").equals("start")) {
// 取启动日志的时间戳
timestampStr = jsonObject.getJSONObject("app_active").getString("time");
} else if (headersMap.getOrDefault("logtype", "").equals("event")) {
// 取事件日志第一条记录的时间戳
JSONArray jsonArray = jsonObject.getJSONArray("event");
if (!jsonArray.isEmpty()) {
timestampStr = jsonArray.getJSONObject(0).getString("time");
}
}
// 将时间戳转换为字符串 "yyyy-MM-dd"
// 将字符串转换为Long
long timestamp = Long.parseLong(timestampStr);
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
Instant instant = Instant.ofEpochMilli(timestamp);
LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
String date = formatter.format(localDateTime);
// 将转换后的字符串放置header中
headersMap.put("logtime", date);
event.setHeaders(headersMap);
} catch (Exception e) {
headersMap.put("logtime", "Unknown");
event.setHeaders(headersMap);
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
List<Event> lstEvent = new ArrayList<>();
for (Event event : events) {
Event outEvent = intercept(event);
if (outEvent != null) {
lstEvent.add(outEvent);
}
}
return lstEvent;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
public void startJunit() {
String str = "2020-08-02 18:19:32.959 [main] INFO com.ecommerce.AppStart - " +
"{\"app_active\":{\"name\":\"app_active\",\"json\":{\"entry\":\"1\",\"action\":\"0\"," +
"\"error_code\":\"0\"},\"time\":1596342840284},\"attr\":{\"area\":\"大庆\",\"uid\":\"2F10092A2\"," +
"\"app_v\":\"1.1.15\",\"event_type\":\"common\",\"device_id\":\"1FB872-9A1002\",\"os_type\":\"2.8\"," +
"\"channel\":\"TB\",\"language\":\"chinese\",\"brand\":\"iphone-8\"}}";
Map<String, String> map = new HashMap<>();
// new Event
Event event = new SimpleEvent();
map.put("logtype", "start");
event.setHeaders(map);
event.setBody(str.getBytes(Charsets.UTF_8));
// 调用interceptor处理event
LogTypeInterceptor customerInterceptor = new LogTypeInterceptor();
Event outEvent = customerInterceptor.intercept(event);
// 处理结果
Map<String, String> headersMap = outEvent.getHeaders();
System.out.println(JSON.toJSONString(headersMap));
}
public void eventJunit() {
String str = "2020-08-02 18:20:11.877 [main] INFO com.ecommerce.AppEvent - " +
"{\"event\":[{\"name\":\"goods_detail_loading\",\"json\":{\"entry\":\"1\",\"goodsid\":\"0\"," +
"\"loading_time\":\"93\",\"action\":\"3\",\"staytime\":\"56\",\"showtype\":\"2\"}," +
"\"time\":1596343881690},{\"name\":\"loading\",\"json\":{\"loading_time\":\"15\",\"action\":\"3\"," +
"\"loading_type\":\"3\",\"type\":\"1\"},\"time\":1596356988428},{\"name\":\"notification\"," +
"\"json\":{\"action\":\"1\",\"type\":\"2\"},\"time\":1596374167278},{\"name\":\"favorites\"," +
"\"json\":{\"course_id\":1,\"id\":0,\"userid\":0},\"time\":1596350933962}],\"attr\":{\"area\":\"长治\"," +
"\"uid\":\"2F10092A4\",\"app_v\":\"1.1.14\",\"event_type\":\"common\",\"device_id\":\"1FB872-9A1004\"," +
"\"os_type\":\"0.5.0\",\"channel\":\"QL\",\"language\":\"chinese\",\"brand\":\"xiaomi-0\"}}";
Map<String, String> map = new HashMap<>();
// new Event
Event event = new SimpleEvent();
map.put("logtype", "event");
event.setHeaders(map);
event.setBody(str.getBytes(Charsets.UTF_8));
// 调用interceptor处理event
LogTypeInterceptor customerInterceptor = new LogTypeInterceptor();
Event outEvent = customerInterceptor.intercept(event);
// 处理结果
Map<String, String> headersMap = outEvent.getHeaders();
System.out.println(JSON.toJSONString(headersMap));
}
}运行命令
nohup flume-ng agent --conf /opt/apps/flume-1.9/conf --conf-file /data/lxqdw/conf/flumelog2hdfs3.conf -name a1 -Dflume.root.logger=INFO,LOGFILE > /dev/null 2>&1 &Sqoop
安装配置
Sqoop 下载地址: http://www.apache.org/dyn/closer.lua/sqoop/tar zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gzmv sqoop-1.4.7.bin__hadoop-2.6.0/ ../servers/sqoop-1.4.7/vi /etc/profile# 增加以下内容export SQOOP_HOME = /opt/lxq/servers/sqoop-1.4.7export PATH = $PATH : $SQOOP_HOME /binsource /etc/profile# 配置文件位置 $SQOOP_HOME/conf ;要修改的配置文件为 sqoop-env.shcp sqoop-env-template.sh sqoop-env.shvi sqoop-env.sh# 在文件最后增加以下内容export HADOOP_COMMON_HOME = /opt/lxq/servers/hadoop-2.9.2export HADOOP_MAPRED_HOME = /opt/lxq/servers/hadoop-2.9.2export HIVE_HOME = /opt/lxq/servers/hive-2.3.7# 拷贝 jdbc 驱动到 sqoop 的 lib 目录下(备注:建立软链接也可以)ln -s /opt/lxq/servers/hive-2.3.7/lib/mysql-connector-java-5.1.46.jar /opt/lxq/servers/sqoop-1.4.7/lib/# 硬拷贝 和 建立软链接都可以,选择一个执行即可。下面是硬拷贝cp $HIVE_HOME /lib/hive-common-2.3.7.jar $SQOOP_HOME /lib/# 建立软链接ln -s /opt/lxq/servers/hive-2.3.7/lib/hive-common-2.3.7.jar /opt/lxq/servers/sqoop-1.4.7/lib/hive-common-2.3.7.jarcp $HADOOP_HOME /share/hadoop/tools/lib/json-20170516.jar $SQOOP_HOME /lib/
样例脚本
#! /bin/bash
source /etc/profile
# 如果第一个参数不为空,则作为工作日期使用
if [ -n "$1" ]
then
do_date=$1
else
# 昨天日期,减一
do_date=`date -d "-1 day" +"%Y%m%d"`
fi
# 定义sqoop命令位置,Hive命令位置,在hadoop2
sqoop=/opt/lxq/servers/sqoop-1.4.7/bin/sqoop
# Hive=/opt/hive
# 定义工作日期
# 编写导入数据通用方法 接收两个参数:第一个:表名,第二个:查询语句
import_data(){
$sqoop import \
--connect jdbc:mysql://linux3:3306/lg_logstic \
--username root \
--password Root_root123 \
--target-dir /user/hive/warehouse/lg_ods.db/$1/dt=$do_date \
--delete-target-dir \
--query "$2 and \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by ',' \
--null-string '\\N' \
--null-non-string '\\N'
}
# 全量导入订单数据方法
import_lg_orders(){
import_data lg_orders "select
*
from lg_orders
where date_format(modifyTime, '%Y%m%d')='20200918'"
}
# 全量导入订单明细数据(包含商品)方法
import_lg_order_items(){
import_data lg_order_items "select
*
from lg_order_items
where date_format(modifyTime, '%Y%m%d')='20200918'"
}
# 全量导入商品方法
import_lg_items(){
import_data lg_items "select
*
from lg_items
where date_format(createTime, '%Y%m%d')='${do_date}'"
}
# 全量导入仓库方法
import_lg_entrepots(){
import_data lg_entrepots "select
*
from lg_entrepots
where createTime='2020-02-22'"
}
# 全量导入商品分类数据方法
import_lg_item_cats(){
import_data lg_item_cats "select
*
from lg_item_cats
where date_format(createTime, '%Y%m%d')='${do_date}'"
}
# 全量导入订单仓库关联数据方法
import_lg_order_entrepot(){
import_data lg_order_entrepot "select
*
from lg_order_entrepot
where date_format(createTime, '%Y%m%d')='${do_date}'"
}
# 调用全量导入订单数据方法
# import_lg_orders
# 调用全量导入订单明细数据方法
# import_lg_order_items
# 调用全量导入商品数据方法
import_lg_items
# 调用全量导入仓库数据方法
# import_lg_entrepots
# 调用全量导入商品分类数据方法
# import_lg_item_cats
# 调用全量导入订单仓库关联数据方法
# import_lg_order_entrepotDataX
安装配置
下载 DataX 工具包http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz下载后解压至本地某个目录,进入 bin 目录,即可运行同步作业
样例脚本(.json文件)
{
"job":{
"setting":{
"speed":{
"channel":1
}
},
"content":[
{
"reader":{
"name":"hdfsreader",
"parameter":{
"path":"/lxq/hive/warehouse/ads.db/ads_ad_show_place/dt=$do_date/*",
"defaultFS":"hdfs://hadoop1:9000",
"column":[
{
"index":0,
"type":"string"
},
{
"index":1,
"type":"string"
},
{
"index":2,
"type":"string"
},
{
"index":3,
"type":"string"
},
{
"index":4,
"type":"string"
},
{
"type":"string",
"value":"$do_date"
}
],
"fileType":"text",
"encoding":"UTF-8",
"fieldDelimiter":","
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"writeMode":"insert",
"username":"hive",
"password":"12345678",
"column":[
"ad_action",
"hour",
"place",
"product_id",
"cnt",
"dt"
],
"preSql":[
"delete from ads_ad_show_place where dt='$do_date'"
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://hadoop2:3306/dwads?
useUnicode=true&characterEncoding=utf-8",
"table":[
"ads_ad_show_place"
]
}
]
}
}
}
]
}
}执行命令
python /data/modules/datax/bin/datax.py -p "-Ddo_date=2020-08-02"
/data/lagoudw/script/advertisement/ads_ad_show_place.jsonCanal
工作原理
Canal 的工作原理复制过程分成三步:1) Master 主库将改变记录写到二进制日志 (binary log) 中2) Slave 从库向 MySQL master 发送 dump 协议,将 master 主库的 binary log events 拷贝到它的中继日志 (relay log) ;3) Slave 从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。Canal 的工作原理很简单,就是把自己伪装成 slave ,假装从 master 复制数据。
安装配置和启动关闭
下载: https://github.com/alibaba/canal/releases[root@linux123 ~]# mkdir /opt/modules/canal[root@linux123 mysql]# tar -zxf canal.deployer-1.1.4.tar.gz -C /opt/modules/canal修改 conf/canal.properties这个文件是 canal 的基本通用配置,主要关心一下端口号,不改的话默认就是 11111修改内容如下:(zk和kafka地址根据个人事迹情况调整)
# 配置 zookeeper 地址canal.zkServers =linux121:2181,linux123:2181# tcp, kafka, RocketMQcanal.serverMode = kafka# 配置 kafka 地址canal.mq.servers =linux121:9092,linux123:9092修改 conf/example/instance.properties这个文件是针对要追踪的 MySQL 的实例配置修改内容如下 :# 配置 MySQL 数据库所在的主机canal.instance.master.address = linux123:3306# username/password ,配置数据库用户和密码canal.instance.dbUsername =canalcanal.instance.dbPassword =canal# mq config, 对应 Kafka 主题:canal.mq.topic=test# 启动 Canalsh bin/startup.sh# 关闭 Canash bin/stop.sh
FileBeat
安装配置
官方地址:https://www.elastic.co/guide/en/beats/filebeat/7.3/index.html
cd /opt/lxq/servers/ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.0-linux-x86_64.tar.gztar -zxvf filebeat-7.3.0-linux-x86_64.tar.gzmv filebeat-7.3.0-linux-x86_64 filebeat/cd filebeatfilebeat.inputs:- type: logpaths:- /usr/local/nginx/logs/access.logfields:app: wwwtype: nginx-accessfields_under_root: true- type: logpaths:- /usr/local/nginx/logs/error.logfields:app: wwwtype: nginx-errorfields_under_root: trueoutput.kafka:hosts: ["linux123:9092"]topic: "nginx_access_log"
Logstash 是运行在 jvm ,资源消耗比较大, 启动一个 Logstash 就需要消耗 500M 左右的内存(这就是为什么 Logstash 启动特别慢的原因),而 filebeat 只需要 10 来 M 内存资源 。常用的 ELK 日志采集方案中,大部分的做法就是将 所有节点的日志内容通过 filebeat 发送 Kafka 集群, Logstash 消费 kafka 数据, Logstash 根据配置文件进行过滤。然后将过滤之后的文件输送到 elasticsearch 中,通过 kibana 去展示 。

















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









