




 本文通过使用KNN算法对鸢尾花数据集进行分类预测,并展示了如何通过交叉验证选择最优的K值。
本文通过使用KNN算法对鸢尾花数据集进行分类预测,并展示了如何通过交叉验证选择最优的K值。
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# cross_validation交叉验证
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
# n_neightbors 综合附近5个点来考虑y的值
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)
print(knn.score(X_test,y_test))结果:0.9555555555555556
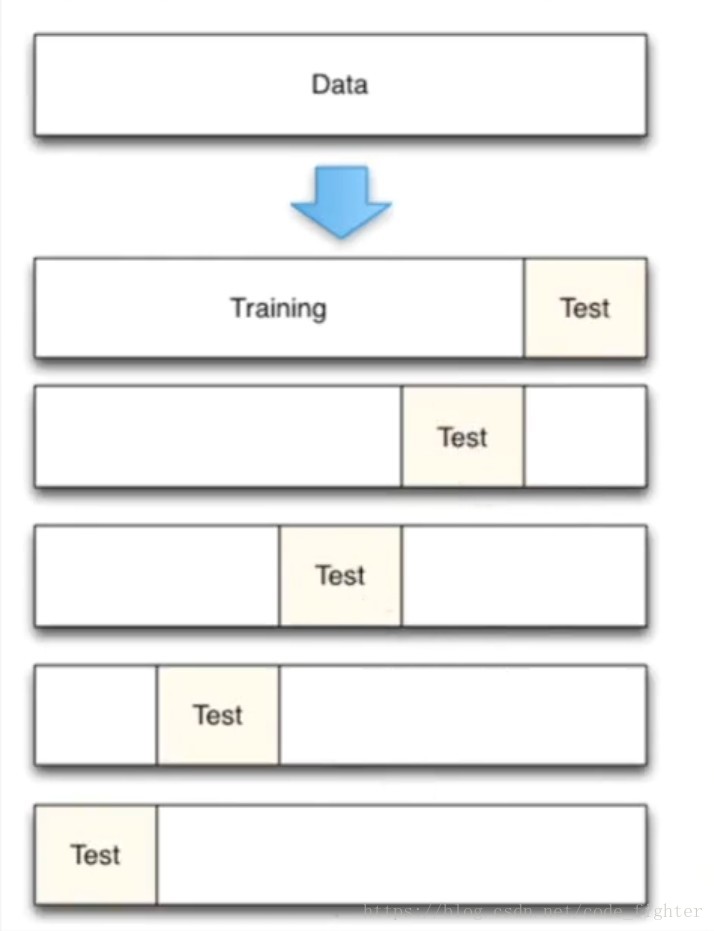
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# cross_validation交叉验证
iris = datasets.load_iris()
X = iris.data
y = iris.target
from sklearn.cross_validation import cross_val_score
knn = KNeighborsClassifier(n_neighbors=5)
# 使用的model是knn 但是X,y 被自动分成5组,
# 每组的test_data和train_data 是不一样的
scores = cross_val_score(knn,X,y,cv=5,scoring='accuracy')
print(scores.mean())结果:0.9733333333333334
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# cross_validation交叉验证
iris = datasets.load_iris()
X = iris.data
y = iris.target
from sklearn.cross_validation import cross_val_score
import matplotlib.pyplot as plt
k_range = range(1,31)
k_score = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn,X,y,cv=10,scoring='accuracy')# for classification
#loss = -cross_val_score(knn,X,y,cv=10,scoring='mean_squared_error')# for regression
k_score.append(scores.mean())
plt.plot(k_range, k_score)
plt.xlabel('Value of K for KNN')
plt.ylabel('Corss-Validated Accuracy')
plt.show()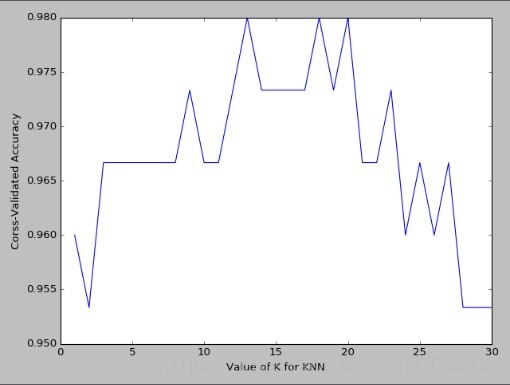

















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









