




*作者:徐晓锋 YashanDB 资深架构师
“一套系统能不能既扛高并发交易,又做实时分析?”、“白天跑业务、晚上跑批处理,能不能不‘掉链子’?”
当我们走访近百家企业,经常听到类似的提问。数字化深入的今天,OLTP与OLAP的界限正在加速模糊,混合工作负载不再是“特殊场景”,而是“常态需求”。传统解决方案中,企业往往需拆分部署两套独立架构:用OLTP数据库支撑高并发,再搭一套OLAP架构支撑分析需求。两套系统、两份数据、双重运维,给企业造成硬件资源重复投入、运维成本高、业务创新迭代受限的多重负担。
基于企业的共性诉求,YashanDB提出“TP+”核心理念,YashanDB V23.5作为这一理念的核心落地版本,对执行引擎、优化器、内存索引访问等多方面进行优化,在TP基础上全面增强复杂查询能力,真正实现TP+场景的极致性能,为企业提供从TB至数百TB级数据全生命周期管理的一站式解决方案。

为什么是现在?
TP+的时代必然性
TP+的兴起并非偶然,而是技术发展与业务需求共同驱动的必然结果:
-
业务层面,企业决策正从“事后分析”转向“实时智能”,例如银行需要在日终批处理的同时响应实时转账查询,电商平台要在高并发交易峰值期完成库存动态分析,传统“先交易后分析”的模式已无法满足业务实时性要求;
-
技术层面,存储成本的持续降低、多核服务器的普及,为“混合负载同引擎处理”提供了硬件基础,而企业对IT架构简化、TCO优化的诉求,进一步推动了“TP+AP融合”的技术演进。
那么,YashanDB定义的TP+究竟是什么?它不是TP与AP的简单拼接,而是以“业务场景为中心”,通过底层技术革新,实现“交易型负载与分析型负载高效协同”的全新架构:既保留TP场景所需的高并发、低延迟、高可靠特性,又具备AP场景所需的复杂计算、批量处理、高效查询能力,让企业无需在“交易速度”与“分析深度”之间做取舍。

YashanDB做了什么?
构建TP+场景混合负载基石
YashanDB V23.5对TP+的支撑,源于我们对底层技术的持续深耕与原创突破。我们拒绝“修修补补”的优化,而是从执行引擎、优化器、内存数据索引等核心模块进行重构,构建起真正适配TP+场景的技术底座。
一、全新向量化执行引擎:批量数据处理性能实现质的提升
面对大规模数据处理场景,传统单行处理模式存在CPU缓存命中率低、内存访问延迟高等瓶颈。YashanDB V23.5全新设计批量数据向量化处理引擎,完成从“单行处理”到“批量列组织处理”的升级,彻底重构执行层架构。
-
核心技术亮点:采用缓存更友好算法,重新设计数据结构与访问模式,最大化提升CPU缓存命中率,显著降低内存访问延迟;针对Hash join、Hash group、排序等核心算子进行深度优化,适配不同数据重复度场景。
-
性能实测表现:在千万级数据测试中,无论低重复度还是高度重复数据场景,核心算子性能均实现跨越式提升,提升幅度达40%至400%。其中排序算子在高度重复数据场景下性能提升最为显著,为大批量数据分析提供强力支撑。
二、优化器新增TopN智能优化:千万级数据查询毫秒级响应
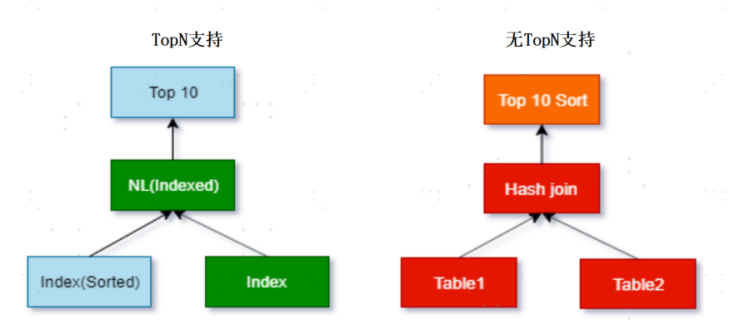
业务中常有“无需全量返回,仅需TopN结果”的场景(如分页查询、热门榜单展示),传统优化器往往会扫描全量数据后再筛选,导致性能浪费。YashanDB V23.5新增优化器TopN模式,通过精细化代价评估实现最优执行计划选择。
-
核心技术亮点:基于统计信息与代价模型,精准评估TopN场景下各算子的计算代价,通过“满足N条记录即终止”的执行逻辑,向上层算子传递记录需求,实现全链路代价最优;智能匹配执行算子,如千万级数据关联场景中自动选择NL join替代Hash join,规避全量数据扫描。
-
性能实测表现:在千万级数据关联+TopN返回场景中,性能提升达上千倍,彻底解决分页查询、热门数据筛选等场景的性能瓶颈。
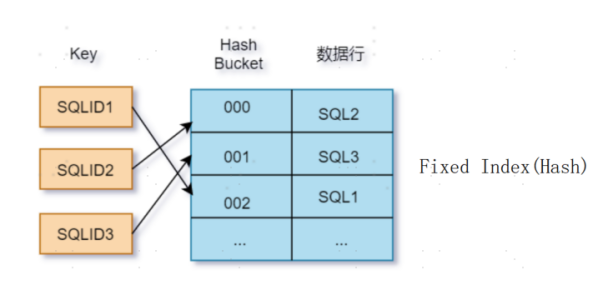
三、优化内存索引访问:高并发点查性能60倍+提升
随着服务器内存容量持续增大,内存数据访问成为高并发实时查询的关键性能节点。YashanDB V23.5实现了内存数据索引访问优化(Fixed Index),基于支持并行操作的Hash结构,实现内存数据的高效点查。
-
核心技术亮点:Hash结构原生支持并行操作,适配高并发场景;索引设计贴合内存数据存取特性,避免冗余数据拷贝与转换开销。
-
性能实测表现:针对客户核心业务的SQL缓存查询场景测试,单值查询性能提升超60倍,多值查询性能提升10倍以上,且内存配置越大,提升幅度越显著,为高并发实时查询提供坚实技术支撑。
四、UDF内联技术优化:复杂业务函数性能大幅提升
用户定义函数(UDF)在企业业务中广泛应用,但传统实现方式存在上下文切换频繁、执行效率低等问题,导致存在显著的性能开销。YashanDB V23.5对UDF内联技术优化,对UDF可以内联的场景,实现了大幅度的性能提升。
-
核心技术亮点:查询编译阶段深度解析UDF的PL/SQL代码,识别可优化模式;将适配的UDF转换为内联子查询,大幅降低上下文切换开销;结合子查询转Join能力,进一步提升执行效率。
-
典型应用示例:以下为子查询转Join的一个示例场景:
-- 原UDF调用语句
create or replace function func_test_so_inline_f1 return varchar2 is
v_out varchar2(32);
begin
select x1 into v_out from t_test_so_inline_1 where a1 = 100;
NULL;
return v_out;
end;
-- 内联优化后自动转为Join执行
select func_test_so_inline_f1
from t_test_so_inline_2
where a2 = 200;
-
性能实测表现:UDF内联优化后,复杂业务函数执行性能大幅提升,彻底解决传统UDF调用导致的性能瓶颈。

场景价值兑现:
从通用能力到业务精准适配
技术的终极价值,是解决真实业务问题。YashanDB V23.5针对企业高频场景做深度适配,让TP+能力真正落地。
一、分页查询优化:亿级数据分页毫秒级响应
分页查询是电商列表、报表分页等场景的核心操作,但传统实现方式随着数据量增长,性能会急剧下降。YashanDB V23.5针对该场景推出Rownum与StopKey协同优化方案,实现全场景分页性能突破。
1. 核心技术亮点
-
条件推导与下推:将Rownum限制条件下推至底层算子,实现数据提前过滤,减少无效数据扫描;
-
索引协同优化:若底层存在有序索引,直接利用索引有序性提前返回结果,避免全表扫描与排序;
-
无索引场景优化:通过StopKey排序机制,显著减少排序内存占用,提升排序效率。
2. 典型应用示例:如下是一个经典的分页查询的例子,可以看到YashanDB基于该类查询优化后的执行计划。
select * from(
select a.*, rownum as rn from (
select custom_id from item order by custom_id desc
)
a)
where rn > 10 and rn < 20;
3. 执行计划优化:优化器自动选择"INDEX FULL SCAN DESCENDING"结合"COUNT STOPKEY",仅扫描必要索引数据,避免全表排序,在千万级数据的测试中,响应时间从秒级降至毫秒级。
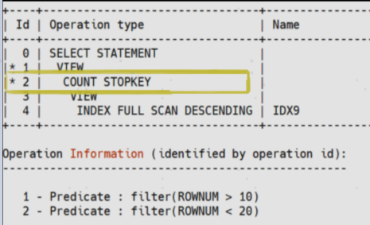
可以使用索引的场景
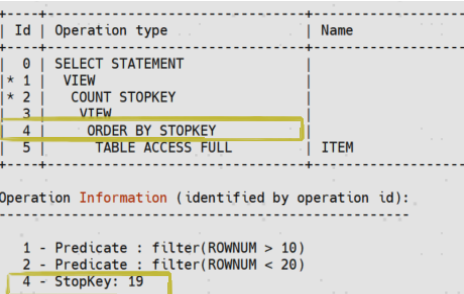
无索引的场景
二、混合批处理优化:企业核心业务全链路加速
针对TP+场景的混合业务操作,典型批处理场景,如日终批处理、大规模数据装载、全局临时表操作、循环处理等,YashanDB V23.5进行全链路优化,充分满足企业级混合业务需求。
1.核心优化点
-
临时表缓存淘汰策略优化:提升临时数据处理吞吐量,减少缓存失效导致的性能波动;
-
Bulk Collection增强:优化PL/SQL批量数据处理性能,提升混合业务下大数据吞吐能力;
-
单列索引创建优化:针对批量处理中临时索引创建需求,提升索引构建效率;
-
子查询转Join扩展:更多复杂子查询可自动转为Join执行,降低嵌套查询开销。
2.业务价值:日终批处理耗时显著缩短,大规模数据装载效率提升,支持企业核心业务(如金融批量结算、零售库存盘点)高效完成。

未来:以TP+为钥
一站式解决数据管理问题
YashanDB对TP+的探索,始终围绕“三个同一”的核心坚守——同一时间支持交易与分析并行、同一空间无需两套系统部署、同一引擎承载全场景负载,这正是崖山数据库与其他“伪融合”方案的本质区别。未来,YashanDB将进一步增强自适应混合负载框架的发展,其核心包括:
-
统一执行引擎:向量化与行处理的无缝切换,火山模型与Pipeline模型的协同调度,兼顾数据流处理的灵活性与并行效率。
-
融合优化框架:基于增强的代价模型,根据查询特征自动选择最优处理模式,为不同负载类型生成最优执行计划。比如点查询采用高效的行式处理,分析查询采用向量化批量处理。
-
多模态混合查询:关系查询、全文检索与向量检索的一体化支持,为多模态数据应用提供统一接口。
我们将持续深化底层技术,让TP+场景的数据管理更智能、更融合,真正一站式解决TB至数百TB级数据全生命周期管理问题,高效支撑密集数据更新与大批量数据分析的混合负载。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









