




 本文详细介绍了HTML中的表格控件,包括表格的基本结构、属性设置,以及如何使用CSS进行样式控制。同时,深入讲解了单元格的合并操作,如跨行和跨列合并的具体实现方法。
本文详细介绍了HTML中的表格控件,包括表格的基本结构、属性设置,以及如何使用CSS进行样式控制。同时,深入讲解了单元格的合并操作,如跨行和跨列合并的具体实现方法。
1、表格控件介绍
<table align="",border="" cellpadding="",cellpacing="" ,width=""> ---> 根标签
<thead> -----------------------------------------> 头部标签,头部区域 必须嵌套在 <table>标签中
<tr> ---------------------------------------> 行标签
<th></th> ----------------------------------> 单元格标签,特点内容加粗,且居中
<td></td>-----------------------------------> 单元格标签 必须嵌套在<tr>标签中
</tr>
</thead>
<tbody> ------------------------------------------->主题区域 必须嵌套在 <table>标签中
<tr>
<td></td>
<td></td>
</tr>
</tbody>
</table>
一般不用这些属性,用CSS显示。
align :规定表格相对周围元素对齐方式。属性值有: left, right, center
border :规定表格是否有边框,默认为“”,表示没有边框 属性值:1或者“”
cellpadding:规定单元格边缘与齐内容之间的空白,默认为1像素 (1px)
cellpacing:规定单元格之间的空白,默认为2像素(2px)
width:规定表格的宽度 。属性值:像素或者百分之
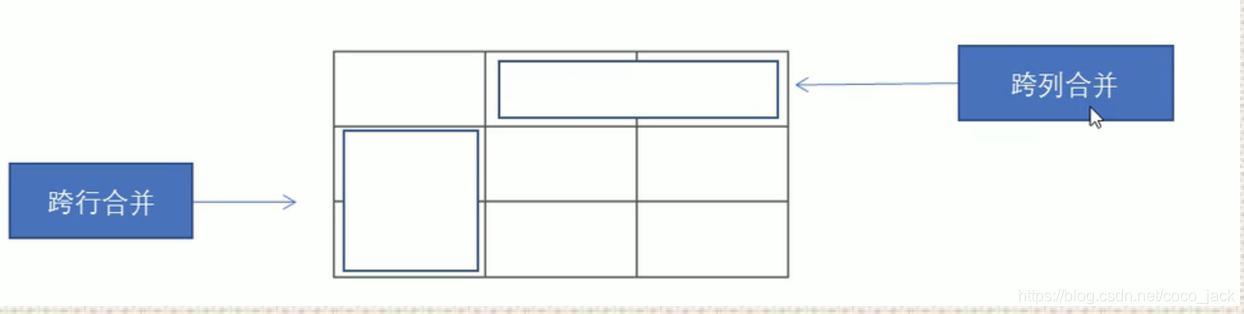
2、合并单元格
- 跨行合并
rowspan=“合并单元格的个数” - 跨列合并
colspan= “合并单元格的个数”
<td rowspan="2" colspan="3" ></td>表示
从上往下数,合并2个单元格 (要合并的第一个单元格为目标单元)。
从左往右数,合并3个单元格.(要合并的最左侧的单元格为目标单元格)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









