



Pandas数据结构 - Series
类似表格中的一个列,类似一个一维数组,可以保存任何数据
Series 特点:
-
索引: 每个
Series都有一个索引,它可以是整数、字符串、日期等类型。如果没有显式指定索引,Pandas 会自动创建一个默认的整数索引。 -
数据类型:
Series可以容纳不同数据类型的元素,包括整数、浮点数、字符串等
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,但具有标签(索引),使得数据在处理和分析时更具灵活性。
以下是关于 Pandas 中的 Series 的详细介绍: 创建 Series: 可以使用 pd.Series() 构造函数创建一个 Series 对象,传递一个数据数组(可以是列表、NumPy 数组等)和一个可选的索引数组。
pandas.Series(data, index, dtype, name, copy)参数说明:
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar[1])输出结果为:2
我们可以指定索引值,如下
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar["y"])输出结果为:Runoob
我们也可以使用 key/value 对象,类似字典来创建 Series:
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)输出结果如下:

从上图可知,字典的 key 变成了索引值。
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)
设置Series的参数名
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)输出结果如下:

更多Series操作
基本操作:
# 获取值
value = series[2] # 获取索引为2的值
# 获取多个值
subset = series[1:4] # 获取索引为1到3的值
# 使用自定义索引
value = series_with_index['b'] # 获取索引为'b'的值
# 索引和值的对应关系
for index, value in series_with_index.items():
print(f"Index: {index}, Value: {value}")基本运算:
# 算术运算
result = series * 2 # 所有元素乘以2
# 过滤
filtered_series = series[series > 2] # 选择大于2的元素
# 数学函数
import numpy as np
result = np.sqrt(series) # 对每个元素取平方根属性和方法:
# 获取索引
index = series_with_index.index #返回索引值
# 获取值数组
values = series_with_index.values #返回Series中所有值的Nupmy数组形式
# 获取描述统计信息
stats = series_with_index.describe()
#describe() 函数会返回该 Series 对象的主要描述性统计指标,包括计数、均值、标准差、最小值、四分位数(25%、50% 和 75%)以及最大值。
# 获取最大值和最小值的索引
max_index = series_with_index.idxmax()
min_index = series_with_index.idxmin()注意事项:
Series中的数据是有序的。- 可以将
Series视为带有索引的一维数组。 - 索引可以是唯一的,但不是必须的。
- 数据可以是标量、列表、NumPy 数组等。
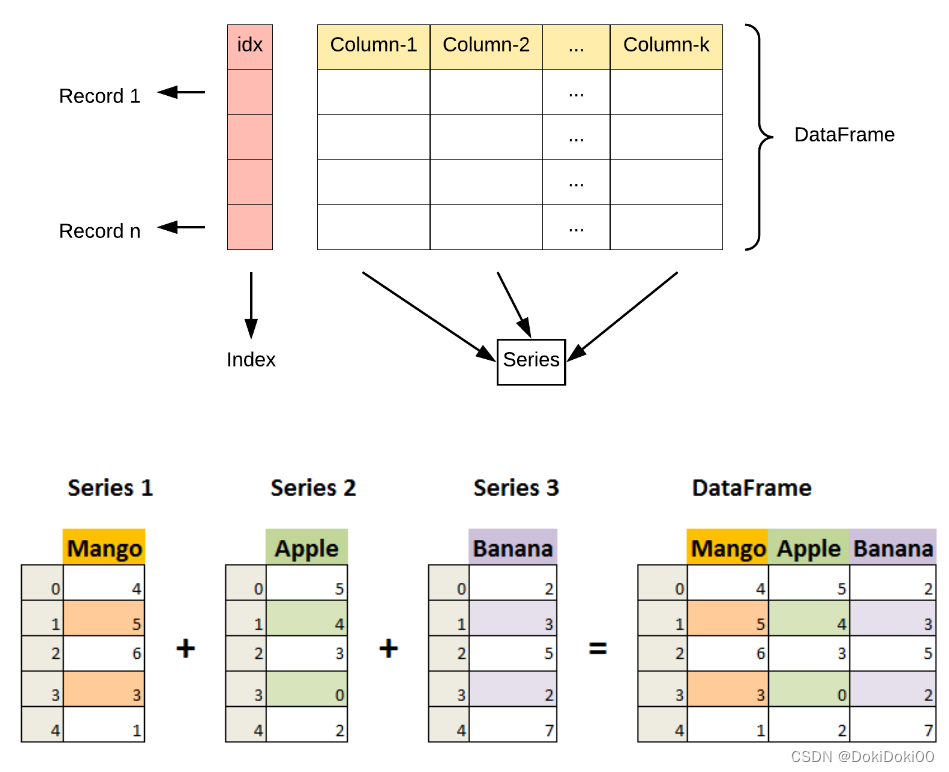
Pandas数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
DataFrame 特点:
-
列和行:
DataFrame由多个列组成,每一列都有一个名称,可以看作是一个Series。同时,DataFrame有一个行索引,用于标识每一行。 -
二维结构:
DataFrame是一个二维表格,具有行和列。可以将其视为多个Series对象组成的字典。 -
列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串等。
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
使用列表来创建
import pandas as pd
data = [['Google', 10], ['Runoob', 12], ['Wiki', 13]]
# 创建DataFrame
df = pd.DataFrame(data, columns=['Site', 'Age'])
# 使用astype方法设置每列的数据类型
df['Site'] = df['Site'].astype(str)
df['Age'] = df['Age'].astype(float)
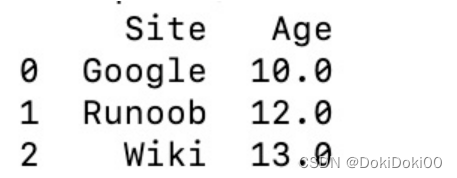
print(df)使用字典来创建:
import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)以下实例使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
使用ndarray来创建
import numpy as np
import pandas as pd
# 创建一个包含网站和年龄的二维ndarray
ndarray_data = np.array([
['Google', 10],
['Runoob', 12],
['Wiki', 13]
])
# 使用DataFrame构造函数创建数据帧
df = pd.DataFrame(ndarray_data, columns=['Site', 'Age'])
# 打印数据帧
print(df)输出结果如下
还可以使用字典(key/value),其中字典的 key 为列名:
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)输出结果为:
a b c
0 1 2 NaN
1 5 10 20.0没有对应的部分数据为 NaN。
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])输出结果如下
calories 420
duration 50
Name: 0, dtype: int64
calories 380
duration 40
Name: 1, dtype: int64
注意:返回结果其实就是一个 Pandas Series 数据。
也可以返回多行数据,使用 [[ ... ]] 格式,... 为各行的索引,以逗号隔开:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])输出结果为:
calories duration
0 420 50
1 380 40注意:返回结果其实就是一个 Pandas DataFrame 数据。
我们可以指定索引值,如下实例:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df)输出结果为:
calories duration
day1 420 50
day2 380 40
day3 390 45Pandas 可以使用 loc 属性返回指定索引对应到某一行:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 指定索引
print(df.loc["day2"])输出结果为:
calories 380
duration 40
Name: day2, dtype: int64更多 DataFrame 说明
基本操作:
# 获取列
name_column = df['Name']
# 获取行
first_row = df.loc[0]
# 选择多列
subset = df[['Name', 'Age']]
# 过滤行
filtered_rows = df[df['Age'] > 30]属性和方法:
# 获取列名
columns = df.columns
# 获取形状(行数和列数)
shape = df.shape
# 获取索引
index = df.index
# 获取描述统计信息
stats = df.describe()数据操作:
# 添加新列
df['Salary'] = [50000, 60000, 70000]
# 删除列
#设置axis=1表示删除列,inplace=True表示在原始DataFrame上进行修改,而不是返回#一个有新的DataFrame
df.drop('City', axis=1, inplace=True)
# 排序
#根据age列的值对DataFrame进行排序
#by='Age'排序依据 ascending=False 表示降序排序(从大到小)
df.sort_values(by='Age', ascending=False, inplace=True)
# 重命名列
#这里将 'Name' 列名修改为 'Full Name'
df.rename(columns={'Name': 'Full Name'}, inplace=True)从外部数据源创建 DataFrame:
# 从CSV文件创建 DataFrame
df_csv = pd.read_csv('example.csv')
# 从Excel文件创建 DataFrame
df_excel = pd.read_excel('example.xlsx')
# 从字典列表创建 DataFrame
data_list = [{'Name': 'Alice', 'Age': 25}, {'Name': 'Bob', 'Age': 30}]
df_from_list = pd.DataFrame(data_list)注意事项:
DataFrame是一种灵活的数据结构,可以容纳不同数据类型的列。- 列名和行索引可以是字符串、整数等。
DataFrame可以通过多种方式进行数据选择、过滤、修改和分析。- 通过对
DataFrame的操作,可以进行数据清洗、转换、分析和可视化等工作。
pandas CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
下文以nba.csv为例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df)输出结果为:
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
.. ... ... ... ... ... ... ... ... ...
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')执行成功后,我们打开 site.csv 文件,显示结果如下:

数据处理
head()
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())tail()同理
info()方法返回表格的一些基本信息
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())输出结果为:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 458 entries, 0 to 457 # 行数,458 行,第一行编号为 0
Data columns (total 9 columns): # 列数,9列
# Column Non-Null Count Dtype # 各列的数据类型
--- ------ -------------- -----
0 Name 457 non-null object
1 Team 457 non-null object
2 Number 457 non-null float64
3 Position 457 non-null object
4 Age 457 non-null float64
5 Height 457 non-null object
6 Weight 457 non-null float64
7 College 373 non-null object # non-null,意思为非空的数据
8 Salary 446 non-null float64
dtypes: float64(4), object(5) # 类型
non-null 为非空数据,我们可以看到上面的信息中,总共 458 行,College 字段的空值最多。
pandas常用函数
读取数据
| 函数 | 说明 |
| pd.read_csv(filename) | 读取 CSV 文件; |
| pd.read_excel(filename) | 读取 Excel 文件; |
| pd.read_sql(query, connection_object) | 从 SQL 数据库读取数据; |
| pd.read_json(json_string) | 从 JSON 字符串中读取数据; |
| pd.read_html(url) | 从 HTML 页面中读取数据。 |
查看数据
| 函数 | 说明 |
| df.head(n) | 显示前 n 行数据; |
| df.tail(n) | 显示后 n 行数据; |
| df.info() | 显示数据的信息,包括列名、数据类型、缺失值等; |
| df.describe() | 显示数据的基本统计信息,包括均值、方差、最大值、最小值等; |
| df.shape | 显示数据的行数和列数。 |
实例:
import pandas as pd
data = [
{"name": "Google", "likes": 25, "url": "https://www.google.com"},
{"name": "Runoob", "likes": 30, "url": "https://www.runoob.com"},
{"name": "Taobao", "likes": 35, "url": "https://www.taobao.com"}
]
df = pd.DataFrame(data)
# 显示前两行数据
print(df.head(2))
# 显示前最后一行数据
print(df.tail(1))输出结果为:
name likes url
0 Google 25 https://www.google.com
1 Runoob 30 https://www.runoob.com
name likes url
2 Taobao 35 https://www.taobao.com数据清洗
| 函数 | 说明 |
| df.dropna() | 删除包含缺失值的行或列; |
| df.fillna(value) | 将缺失值替换为指定的值; |
| df.replace(old_value, new_value) | 将指定值替换为新值; |
| df.duplicated() | 检查是否有重复的数据; |
| df.drop_duplicates() | 删除重复的数据。 |
数据的选择和切片
| 函数 | 说明 |
| df[column_name] | 选择指定的列; |
| df.loc[row_index, column_name] | 通过标签选择数据; |
| df.iloc[row_index, column_index] | 通过位置选择数据; |
| df.ix[row_index, column_name] | 通过标签或位置选择数据; |
| df.filter(items=[column_name1, column_name2]) | 选择指定的列; |
| df.filter(regex='regex') | 选择列名匹配正则表达式的列; |
| df.sample(n) | 随机选择 n 行数据。 |
df.filter 用于提取特定列名的子集非常方便
数据排序
| 函数 | 说明 |
| df.sort_values(column_name) | 按照指定列的值排序 |
| df.sort_values([column_name1, column_name2], ascending=[True, False]) | 按照多个列的值排序; |
| df.sort_index() | 按照索引排序。 |
df.sort_values([column_name1, column_name2], ascending=[True, False]),
[column_name1, column_name2]:这是一个列名列表,表示需要排序的列。在这个示例中,我们指定了两列:column_name1和column_name2。ascending=[True, False]:这是一个布尔值列表,True表示对column_name1列进行升序(从小到大)排序,False表示对column_name2列进行降序(从大到小)排序。数据的分组和聚合
| 函数 | 说明 |
| df.groupby(column_name) | 按照指定列进行分组; |
| df.aggregate(function_name) | 对分组后的数据进行聚合操作; |
| df.pivot_table(values, index, columns, aggfunc) | 生成透视表。 |
数据透视表是一种处理和分析数据的工具,它可以汇总、分组和对原始数据进行聚合,以便更好地理解数据的结构和模式。
values:这是要在数据透视表中聚合的列的名称,index:这是一个列名,用作数据透视表的行索引(或行层次),columns:这是一个列名或列名列表,用作数据透视表的列索引(或列层次),aggfunc:这是一个函数或函数列表,用于定义聚合操作。aggfunc可以是:内置的聚合函数(如'mean'、'sum'、'max'等)、自定义的聚合函数,或者列表形式的组合。默认为mean,即计算平均值。
数据合并
| 函数 | 说明 |
| pd.concat([df1, df2]) | 将多个数据框按照行或列进行合并; |
| pd.merge(df1, df2, on=column_name) | 按照指定列将两个数据框进行合并。 |
concat不考虑列之间的关系,根据列名或行索引直接合并数据,在列方向合并,设置axis为1
merge根据一个或多个共享列的值来组合数据
数据选择和过滤
| 函数 | 说明 |
| df.loc[row_indexer, column_indexer] | 按标签选择行和列。 |
| df.iloc[row_indexer, column_indexer] | 按位置选择行和列。 |
| df[df['column_name'] > value] | 选择列中满足条件的行。 |
| df.query('column_name > value') | 使用字符串表达式选择列中满足条件的行。 |
数据的统计和描述
| 函数 | 说明 |
| df.describe() | 计算基本统计信息,如均值、标准差、最小值、最大值等。 |
| df.mean() | 计算每列的平均值。 |
| df.median() | 计算每列的中位数。 |
| df.mode() | 计算每列的众数。 |
| df.count() | 计算每列非缺失值的数量。 |
json和可视化分析详情可见 https://www.runoob.com/pandas/pan
数据清洗见python数据分析和处理(后续更新)

















 2359
2359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









