



 本文介绍了如何在腾讯云环境中集成Flink与Hive,利用HiveMetastore作为Catalog进行数据管理和查询。通过创建Oceanus和EMR集群,设置相关依赖,实现数据源和数据接收器的创建,并展示了如何读写Hive表以及Hive作为维表进行实时数据处理的示例。
本文介绍了如何在腾讯云环境中集成Flink与Hive,利用HiveMetastore作为Catalog进行数据管理和查询。通过创建Oceanus和EMR集群,设置相关依赖,实现数据源和数据接收器的创建,并展示了如何读写Hive表以及Hive作为维表进行实时数据处理的示例。

作者:苏文鹏,腾讯 CSIG 工程师
一、背景
Apache Hive 已经成为了数据仓库生态系统中的核心。它不仅仅是一个用于大数据分析和 ETL 场景的 SQL 引擎,同样它也是一个数据管理平台,可用于发现、定义和演化数据。Flink 与 Hive 的集成包含两个层面:
-
一是利用了 Hive 的 Metastore 作为持久化的 Catalog,用户可通过 HiveCatalog 将不同会话中的 Flink 元数据存储到 Hive Metastore 中。例如,用户可以使用 HiveCatalog 将其 Kafka 表或 Elasticsearch 表存储在 Hive Metastore 中,并后续在 SQL 查询中重新使用它们。
-
二是利用 Flink 来读写 Hive 的表。
HiveCatalog 的设计提供了与 Hive 良好的兼容性,用户可以"开箱即用"的访问其已有的 Hive 数仓。您不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
二、前置准备
创建私有网络 VPC
私有网络(VPC)是一块在腾讯云上自定义的逻辑隔离网络空间,在构建 Oceanus 集群、Hive 组件等服务时选择的网络建议选择同一个 VPC,网络才能互通。否则需要使用对等连接、NAT 网关、VPN 等方式打通网络。私有网络创建步骤请参考 帮助文档 [1]。
创建流计算 Oceanus 集群
流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发、无缝连接、亚秒延时、低廉成本、安全稳定等特点的企业级实时大数据分析平台。流计算 Oceanus 以实现企业数据价值最大化为目标,加速企业实时化数字化的建设进程。
在 Oceanus 控制台的【集群管理】->【新建集群】页面创建集群,选择地域、可用区、VPC、日志、存储,设置初始密码等。VPC 及子网使用刚刚创建好的网络。创建完后 Oceanus 的集群如下:

创建 EMR 集群
EMR 是云端托管的弹性开源泛 Hadoop 服务,支持 Hive、Kudu、HDFS、Presto、Flink、Druid 等大数据框架,本次示例主要需要使用 Hive、Zookeeper、HDFS、Yarn、Knox 组件。
进入 EMR 控制台 [2],单击左上角【创建集群】进行集群的创建,创建过程中注意选择【产品版本】,不同的版本包含的组件不同,笔者这里选择EMR-V2.2.0版本,另外【集群网络】需选择之前创建好的 VPC 及对应的子网。具体过程可参考 创建 EMR 集群 [3]。

创建 Oceanus SQL 作业
上传依赖
在 Oceanus 控制台,点击左侧【依赖管理】,点击左上角【新建】新建依赖,上传 Hive 有关的配置文件。
hdfs-site.xml
hive-site.xml
hivemetastore-site.xml
hiveserver2-site.xml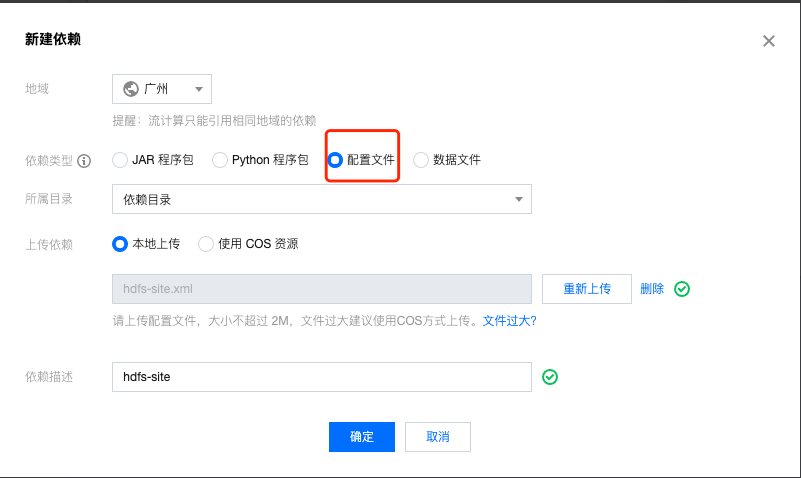
创建 SQL 作业
在 流计算 Oceanus 控制台 的 作业管理 > 新建作业 中新建 SQL 作业,选择在新建的集群中新建作业。
创建 HiveCatalog
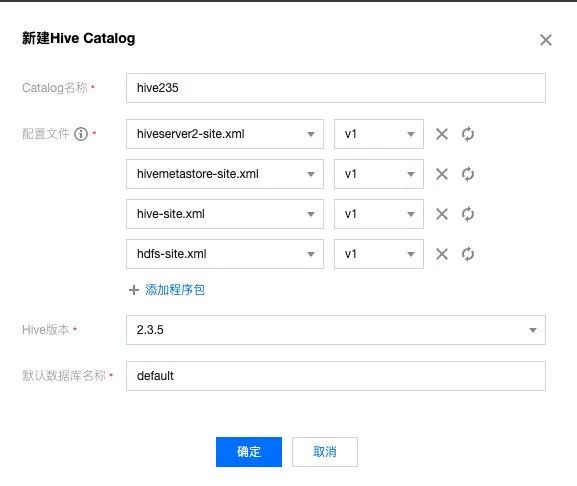
三、Hive Metastore 的用途
1. 利用 Hive Metastore 作为持久化的 Catalog
创建 Source
CREATE TABLE datagen_source_table (
id INT,
name STRING ,
dt STRING,
hr STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='1' -- 每秒产生的数据条数
);
创建 Sink
CREATE TABLE IF NOT EXISTS `_hive235`.`tinatest1`.`jdbc_upsert_sink_table` (
id INT,
name STRING ,
dt STRING,
hr STRING
) WITH (
-- 指定数据库连接参数
'connector' = 'jdbc',
'url' = 'jdbc:mysql://xx.xx.xx.xx:3306/tina?rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai', -- 请替换为您的实际 MySQL 连接参数
'table-name' = 'testhive', -- 需要写入的数据表
'username' = 'root', -- 数据库访问的用户名(需要提供 INSERT 权限)
'password' = 'xxxxxxxxx', -- 数据库访问的密码
'sink.buffer-flush.max-rows' = '70000', -- 批量输出的条数
'sink.buffer-flush.interval' = '1s' -- 批量输出的间隔
);
算子操作
insert into `_hive235`.`tinatest1`.`jdbc_upsert_sink_table`
select * from datagen_source_table;
结果验证
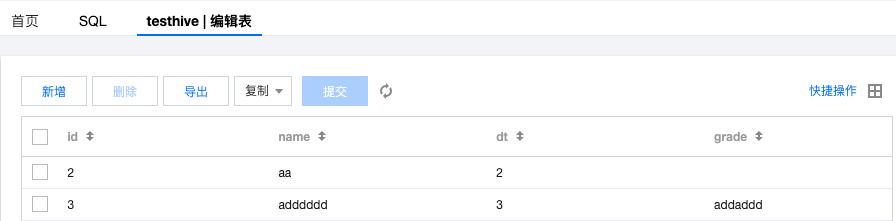
2. 读写 Hive 表的数据
创建 Hive 实体表
CREATE TABLE `record`(
`id` int,
`name` string)
PARTITIONED BY (
`dt` string,
`hr` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'cosn://tinametatest-xxxxxxxx/xxxxx/xxxxx'
TBLPROPERTIES (
'hive-version'='2.3.5',
'streaming-source.consume-order'='create-time',
'streaming-source.enable'='true',
'streaming-source.monitor-interval'='10s',
'streaming-source.partition.include'='all',
);
CREATE TABLE `record_target`(
`id` int,
`name` string,
`dt` string,
`hr` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
TBLPROPERTIES (
'hive-version'='2.3.5');算子操作
insert into `_hive235`.`tinatest1`.`record_target` select * from `_hive235`.`tinatest1`.`record`;结果验证
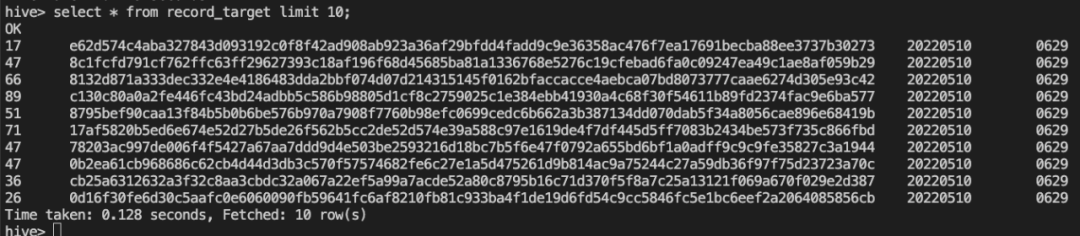
3. Hive 用做维表
基于 processing time join 最新 Hive 分区中的数据
创建 Hive 实体表
CREATE TABLE `record2`(
`id` int ,
`name` string)
PARTITIONED BY (
`dt` string,
`hr` string)
LOCATION
'cosn://tinametatest-xxxxxxxxx/xxxxx/xxxxx'
TBLPROPERTIES (
'hive-version'='2.3.5',
'streaming-source.consume-order'='partition-name',
'streaming-source.enable'='true',
'streaming-source.monitor-interval'='10s',
'streaming-source.partition.include'='latest');
创建 Source
CREATE TABLE `mysql_cdc_source_table` (
`id` INT,
`name` STRING,
proctime as proctime(),
PRIMARY KEY (`id`) NOT ENFORCED -- 如果要同步的数据库表定义了主键, 则这里也需要定义
) WITH (
'connector' = 'mysql-cdc', -- 固定值 'mysql-cdc'
'hostname' = 'xx.xx.xx.xx', -- 数据库的 IP
'port' = '3306', -- 数据库的访问端口
'username' = 'root', -- 数据库访问的用户名(需要提供 SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENT、SELECT 和 RELOAD 权限)
'password' = 'xxxxxxxx', -- 数据库访问的密码
'database-name' = 'tina', -- 需要同步的数据库
'table-name' = 'my_table' , -- 需要同步的数据表名
'server-id'='7400-7412'
);
创建 Sink
CREATE TABLE `jdbc_sink_table` (
`id` INT PRIMARY key,
`name` STRING
) WITH (
-- 指定数据库连接参数
'connector' = 'jdbc',
'url' = 'jdbc:mysql://xx.xx.xx.xx:3306/tina?rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai', -- 请替换为您的实际 MySQL 连接参数
'table-name' = 'hivecdc', -- 需要写入的数据表
'username' = 'root', -- 数据库访问的用户名(需要提供 SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENT、SELECT 和 RELOAD 权限)
'password' = 'xxxxxxxx', -- 数据库访问的密码
'sink.buffer-flush.max-rows' = '200', -- 批量输出的条数
'sink.buffer-flush.interval' = '2s' -- 批量输出的间隔
);
算子操作
INSERT INTO jdbc_sink_table
SELECT o.id,o.name FROM mysql_cdc_source_table AS o
JOIN `_hive235`.`tinatest1`.`record2` FOR SYSTEM_TIME AS OF o.proctime AS dim
ON o.id = dim.id;
基于 processing time join 最新 Hive 表中的数据
创建 Hive 实体表
CREATE TABLE `record_batch`(
`id` int ,
`name` string)
PARTITIONED BY (
`dt` string,
`hr` string)
LOCATION
'cosn://tinametatest-xxxxxxxx/xxxxx/xxxxx'
TBLPROPERTIES (
'hive-version'='2.3.5',
'lookup.join.cache.ttl'='10s');
创建 Source
CREATE TABLE `mysql_cdc_source_table` (
`id` INT,
`name` STRING,
proctime as proctime(),
PRIMARY KEY (`id`) NOT ENFORCED -- 如果要同步的数据库表定义了主键, 则这里也需要定义
) WITH (
'connector' = 'mysql-cdc', -- 固定值 'mysql-cdc'
'hostname' = 'xx.xx.xx.xx', -- 数据库的 IP
'port' = '3306', -- 数据库的访问端口
'username' = 'root', -- 数据库访问的用户名(需要提供 SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENT、SELECT 和 RELOAD 权限)
'password' = 'xxxxxxxx', -- 数据库访问的密码
'database-name' = 'tina', -- 需要同步的数据库
'table-name' = 'my_table' , -- 需要同步的数据表名
'server-id'='7400-7412'
);
创建 Sink
CREATE TABLE `jdbc_sink_table` (
`id` INT PRIMARY key,
`name` STRING
) WITH (
-- 指定数据库连接参数
'connector' = 'jdbc',
'url' = 'jdbc:mysql://xx.xx.xx.xx:3306/tina?rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai', -- 请替换为您的实际 MySQL 连接参数
'table-name' = 'hivecdc', -- 需要写入的数据表
'username' = 'root', -- 数据库访问的用户名(需要提供 SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENT、SELECT 和 RELOAD 权限)
'password' = 'xxxxxxxx', -- 数据库访问的密码
'sink.buffer-flush.max-rows' = '200', -- 批量输出的条数
'sink.buffer-flush.interval' = '2s' -- 批量输出的间隔
);
算子操作
insert into jdbc_sink_table
SELECT o.id,o.name FROM mysql_cdc_source_table AS o
JOIN `_hive235`.`tinatest1`.`record_batch` FOR SYSTEM_TIME AS OF o.proctime AS dim
ON o.id = dim.id;
四、注意事项
-
配置文件 hive-site.xml 文件中需要配置 Metastore 的路径;
-
同一个 SQL 作业中只能使用一个 HiveCatalog;
-
读取 Hive 数仓中的表时需要在配置表的 Properties 属性;
五、参考链接
[1] VPC 帮助文档:https://cloud.tencent.com/document/product/215/36515
[2] EMR 控制台:https://console.cloud.tencent.com/emr/
[3] 创建 EMR 集群:https://cloud.tencent.com/document/product/589/10981
[4] Flink 官网:https://nightlies.apache.org/flink/flink-docs-master/docs/connectors/table/hive/overview/
[5] 使用 HiveCatalog:https://cloud.tencent.com/document/product/849/71854



















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









