



 本文详细介绍了SQL优化的方法,包括使用执行计划定位性能问题、SQL的生命周期、大数据查询优化策略以及超大分页处理技巧。通过语法优化、建立索引、增加过滤条件、使用缓存和读写分离等手段,提升数据库查询效率。
本文详细介绍了SQL优化的方法,包括使用执行计划定位性能问题、SQL的生命周期、大数据查询优化策略以及超大分页处理技巧。通过语法优化、建立索引、增加过滤条件、使用缓存和读写分离等手段,提升数据库查询效率。
1.SQL优化
1.1如何定位及优化SQL语句的性能问题
对于低性能的SQL语句的定位,最重要也是最有效的办法就是使用执行计划,MySQL提供了explain命令来查看语句的执行计划

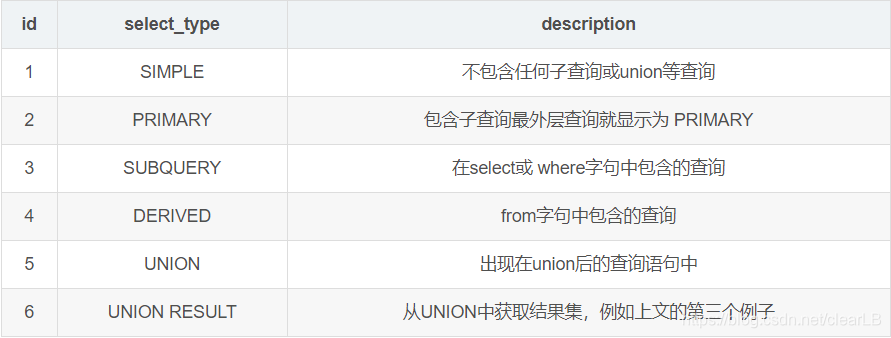
执行计划一般包含下面几个字段的信息:
- id:表示一个查询中各个子查询的执行顺序,id相同则执行顺序由上至下,id不同,id值越大优先级越高,越先被执行,id为null时表示一个结果集,不需要使用它查询,常出现在union等查询语句中
- select_type:每个子查询的查询类型,一些常见的查询类型为:
- table:查询的数据表
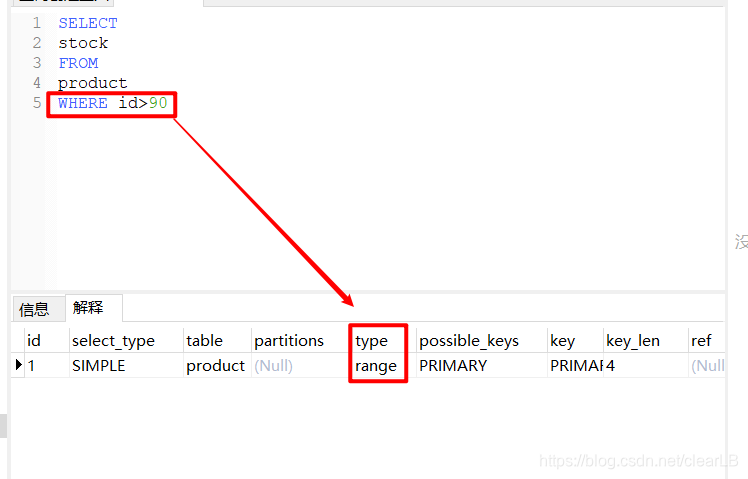
- type:访问类型
- ALL:扫描全表数据
- index:按索引次序扫描,先读索引,再读实际的行,结果还是全表扫描,主要优点是避免了排序,因为索引是排序好的
- range:索引范围查找,当索引使用<,>,is null,between,in,like时出现
- ref:按照普通索引查询
- eq_ref:使用唯一索引查找(主键或唯一索引)
- const:常量查询,在整个查询过程中这个表最多只会有一条匹配的行
- possible_key:可能使用的索引,注意不一定会使用。查询涉及到的字段若存在索引,则该索引将被列出来。当该列为NULL时就要考虑当前的SQL是否需要优化了
- key:显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
1.2 SQL的生命周期
- 应用服务器与数据库建立一个连接
- 数据库进程拿到请求SQL
- 解析并生成执行计划,执行
- 读取数据到内存中并进行逻辑处理
- 通过步骤一的连接,发送结果到客户端
- 关掉连接,释放资源
1.3 SQL大数据查询如何进行优化
- 语法优化:
- 首先查看有没有致索引失效,导致进行全表查询的地方,比如>,<,is null,!=等,看可不可以去除,如果不行,就在这类操作之前先进行其它条件的过滤
- 建索引:对常用且重复率低的字段,建索引
- 增加过滤条件
- 使用缓存
- 对数据库进行读写分离
1.4超大分页怎么处理
主要的优化思路就是:在索引上完成排序分页的操作,最后根据主键关联回表查询所需要的其他列内容,通过索引覆盖在索引上完成扫描和排序,最后通过主键回表查询,最大限度减少回表查询的I/O次数
















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









