 机器学习:深入理解决策树的构建与优化
机器学习:深入理解决策树的构建与优化





 本文详细介绍了决策树的构建原理,包括香浓熵、信息增益、信息增益率和基尼指数等关键概念,并探讨了预剪枝和后剪枝两种优化策略。通过构建ID3、C4.5和CART三种决策树,对比了它们的性能和适用场景。实验证明,不同的决策树构造方法对准确度和决策树结构有显著影响。
本文详细介绍了决策树的构建原理,包括香浓熵、信息增益、信息增益率和基尼指数等关键概念,并探讨了预剪枝和后剪枝两种优化策略。通过构建ID3、C4.5和CART三种决策树,对比了它们的性能和适用场景。实验证明,不同的决策树构造方法对准确度和决策树结构有显著影响。
文章目录
实验背景
在之前的实验:
机器学习_1:K-近领算法
机器学习_2:K-近领算法
我们了解到了K-近邻算法是一种无需训练就可以拿来进行分类的算法,但缺点也很多,最大的缺点就是无法给出数据的内在含义,今天我就来介绍一种容易理解数据形式的分类算法——决策树算法。
1.决策树算法原理
1.1.什么是决策树
严格定义上来说,分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶节点。内部结点表示一个特征或属性,叶节点表示一个类。
通俗来说决策树只有一个功能——判断,通过不断的判断最终得出一个结果,以相亲为例
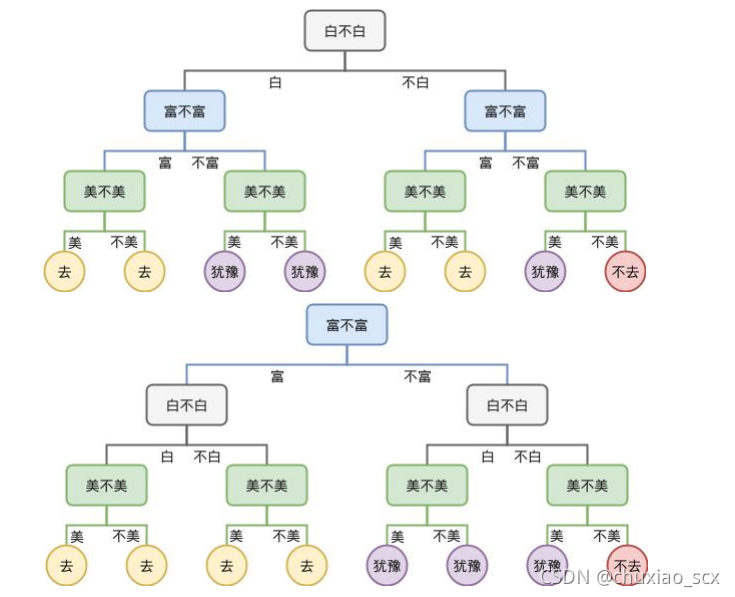
我们将相亲简单的化为三个属性的思考(对象白不白,富不富,美不美),实际上的相亲远比这复杂,很显然,白富美的对象几乎没有人会拒绝。而一个新的对象放进决策树里判断,这个对象是白,富,不美,经过3次判断之后,得出的结论是去。这就是决策树,当然,这种’海王’决策树不是我们特别需要的。
决策树的使用更多倾向于专家系统中,以病情诊断为例,将以前人们记录的各种疾病以及这些疾病发生时的症状记录下来,用于构建决策树,经过这些疾病的训练后,当病人根据提示输入体温等各种信息后,这个病情决策树就能判断出患者得了哪种病。
那么问题就来了,哪种属性作为判断的依据呢,或者说,哪种属性作为判断依据可以有最好的效果呢?
1.2.如何构建好的决策树
想要构造好的决策树,就得找到合适的属性作为判断依据,如何选择合适的属性呢,这里引入四个概念,香浓熵,信息增益,信息增益率,基尼指数。
1.2.1.香浓熵
熵,本质是指一个系统的“内在混乱程度”,香浓熵也一样,这个词用来形容一个事物的确定程度,香浓熵越大,事物的就越不确定,香浓熵越小,事物越确定。
公式为:
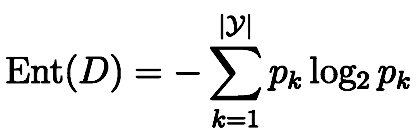
Ent(D)表示熵,pk表示k事件出现的概率,k=1~y表示共有y种事件
以硬币为例,一枚硬币抛出,正面或反面朝上的概率均为50%,此时熵为:-(1/2(log2(1/2))+1/2(log2(1/2)))=1。很显然,此时就是这个硬币最不确定的时候,如果我们对硬币作手脚,让其概率发生变化,香浓熵也会随之变化。
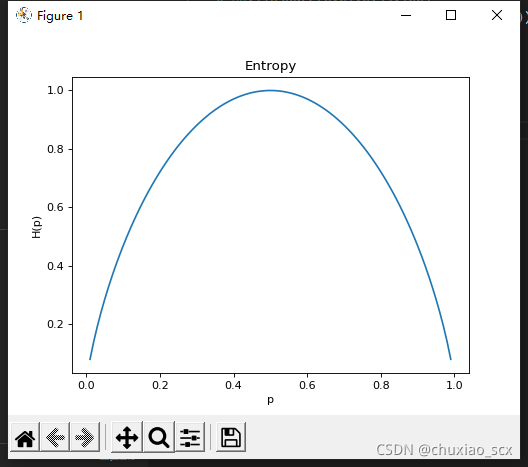
这就是硬币概率变化导致熵的变化,当然,这里硬币只有两种结果,当这两种概率相等的时候熵最大。当事件越多,熵值就会越大。
1.2.2.信息增益
在划分数据集之前之后信息发生的变化称为信息增益,计算公式为:
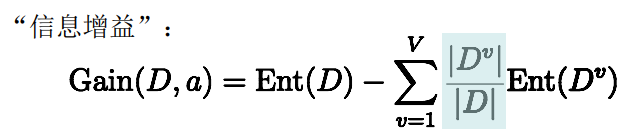
Gain(D,a)表示集合D中属性a的信息增益,Dv表示属性a有V种分支,第v个节点包含了D在a属性上取值为av的所有样本。Gain(D,a)越大,代表根据属性a划分获得的“纯度提升”越大。
1.2.3.信息增益率
虽然信息增益可以帮助我们选择合适的划分属性,但他也有一个很明显的问题,那就是明显偏好可取数目比较多的属性,以硬币为例,如果抛10次硬币,5次朝上,5次朝下,如果以次数为属性,可以发现,每次都只有一个值即属性是确定的,这样信息增益就会变成1-0=1。所以我们引入信息增益率
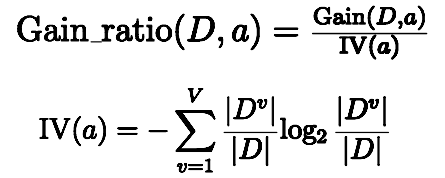
IV(a)称为属性a的固有值,属性a的可能取值越多,IV(a)的值通常就越大,显然,这种方法也有一个缺点,那就是偏好可取数目比较少的属性,所以我们先挑选信息增益高于平均水平的属性,再对其求信息增益率,这样就能得到合适的属性。
1.2.4.基尼指数
基尼指数是不同于信息增益和信息增益率的另一套属性,他用来描述数据集的纯度,反应了随机抽取两个样本,其类别标记不一致的概率,也就是基尼指数越小,这个数据集的标记越统一
公式为:
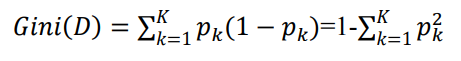
给定数据集D,属性a的基尼指数定义为:
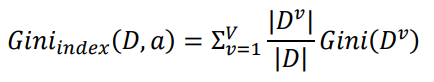
在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最有划分属性。
1.3.如何优化构建完的决策树
尽管有多种方法可以选择合适的属性来划分数据集,构造决策树,但根据训练数据集训练出来的决策树也有很明显的问题,那就是过度拟合训练数据,导致泛用性下降。实际上,训练数据集不可能包含了世界上的所有情况,这就导致一个新的样例丢入决策树进行判断,得出的结果有很大可能不是我们想要的,因为这种样例决策树没有接触过。这就需要我们对决策树进行“剪枝”。
1.3.1.预剪枝
顾名思义,预剪枝通过提前停止树的构建而对树剪枝,主要方法有4种:
1.当决策树达到预设的高度时就停止决策树的生长。
2.达到某个节点的实例具有相同的特征向量,即使这些实例不属于同一类,也可以停止决策树的生长。
(比如同样是头疼,发热,大部分是感冒,小部分是中暑,我们就认为头疼,发热都是感冒)
3.定义一个阈值,当达到某个节点的实例个数小于阈值时就可以停止决策树的生长。
(这是为了防止过度拟合训练数据,比如头疼的样例有10个,头疼发热的样例只有1个,那就无需再用发热进行划分)
4.通过计算每次扩张对系统性能的增益,决定是否停止决策树的
(提升系统性能就扩张,降低就砍掉这个属性)
方法3中有个很明显的问题,这个阈值是我们事先规定的,但是如何确定这个阈值是值得讨论的,如何控制好欠拟合-过拟合的平衡是这个地方的难点。
尽管预剪枝能降低过拟合风险并且显著减少训练时间和测试时间开销。但因为他的“贪心”导致可能会陷入局部最优,也就是无法解决高-低-更高的情况,会困死在小山包上。同时因为限制分枝的展开,使得欠拟合风险大大提高(毕竟头疼发热的样例哪怕只有一例,如果是病毒的情况,这种也是需要注意的,预剪枝就可能会导致忽视这种问题)
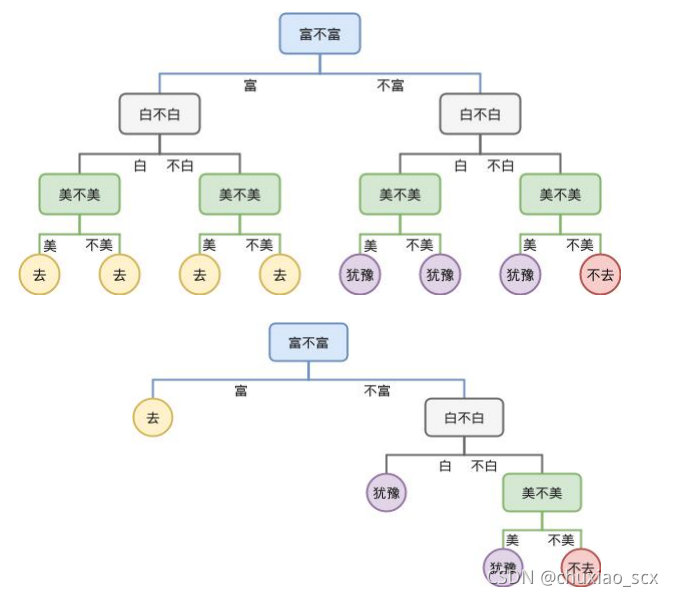
如图所示,预剪枝情况下是没有上面那棵完整的决策树的,直接画出下面那棵剪枝后的决策树。
1.3.2.后剪枝
后剪枝先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行分析计算,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。如果没有提升,保持不便的话,我们就保留。
优缺点都很明显,保留更多的分支使得欠拟合的风险减小,有足够分支的情况下一般也比分支过少的预剪枝泛化性更好;更优秀的表现往往需要更多的付出,因为这种方法是生成完整的决策树后,自底向上进行剪枝,导致训练时间很长,开销大。
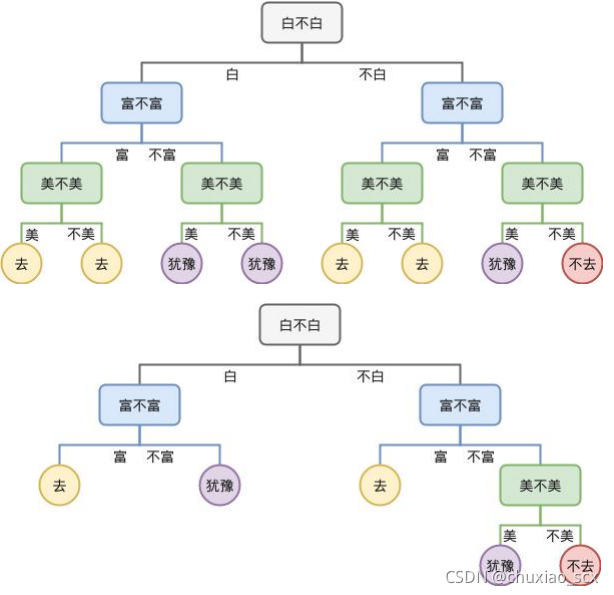
后剪枝先生成上面那棵完整的决策树,再对那棵决策树进行剪枝。
2.三种决策树构造
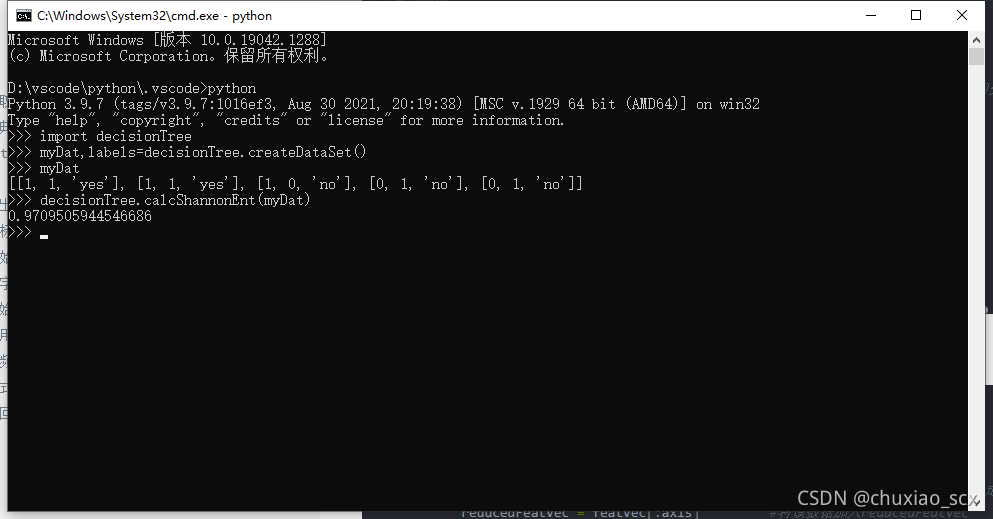
原理解释完后,我们来分别构建基于信息增益,信息增益率,基尼指数的决策树,首先,我们需要计算香浓熵,代码如下:
#计算香浓熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet) #获取数据集总数
labelCounts = {
} #字典,存储类别及个数
for featVec in dataSet: #dataSet进入后为list形式,使用变量featVec进行列表遍历
currentLabel = featVec[-1] #取出列表最后一个标签
if currentLabel not in labelCounts.keys(): #若标签不在字典中
labelCounts[currentLabel] = 0 #初始化标签数量
labelCounts[currentLabel] += 1 #在字典中就数量+1
shannonEnt = 0.0 #初始化香浓熵
for key in labelCounts: #使用关键字循环遍历
prob = float(labelCounts[key])/numEntries #将频数转换成概率
shannonEnt -= prob * log(prob,2) #公式求熵
return shannonEnt #返回香浓熵
#测试用数据
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels
2.1.基于信息增益构造的决策树(ID 3)
#按照给定的特征划分数据集
def splitDataSet(dataSet, axis, value):
retDataSet = [] #存储分割数据
for featVec in dataSet: #list遍历
if featVec[axis] == value: #如果数据集里的value符合我们给定的axis
reducedFeatVec = featVec[:axis] #将该数据加入reducedFeatVec
reducedFeatVec.extend(featVec[axis+1:]) #用extend追加多个值
retDataSet.append(reducedFeatVec) #将reducedFeatVec通过append添加给retDataSet
return retDataSet #返回划分数据
#选择最好的数据集划分方式(信息增益)
def chooseBestFeatureToSplit1(dataSet):
numFeatures = len(dataSet[0]) - 1 #去除标签的特征数量
baseEntropy = calcShannonEnt(dataSet) #得到香浓熵
#初始化参数
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures): #迭代所有特征
featList = [example[i] for example  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









