



 本文详细介绍sed与awk工具在Linux环境下进行文本处理的方法,包括行打印、字符替换、匹配模式、字段操作等核心功能,适合初学者快速掌握。
本文详细介绍sed与awk工具在Linux环境下进行文本处理的方法,包括行打印、字符替换、匹配模式、字段操作等核心功能,适合初学者快速掌握。
0411正则之sed、awk
一、sed工具的使用
sed及awk工具,能够把替换的文本输出到屏幕,sed与awk都是流式编辑器,是针对文本的行来操作的。
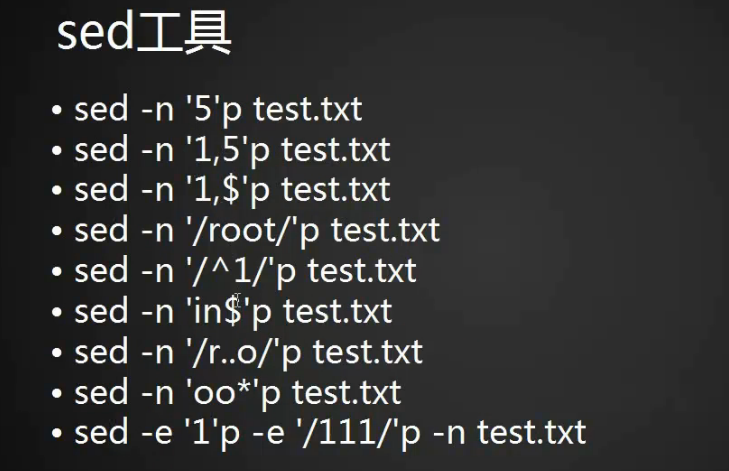
1、打印某行或指定某几行或全部 命令格式为:sed -n ‘n’p filename
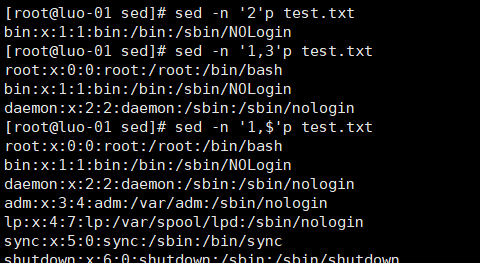
2、打印某一行并匹配带root字符的行(其余用法均与grep类似)
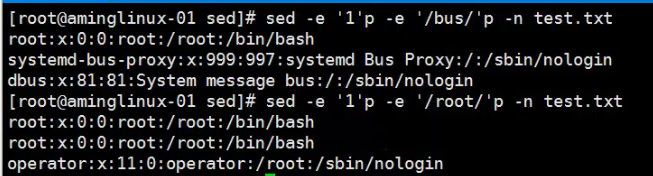
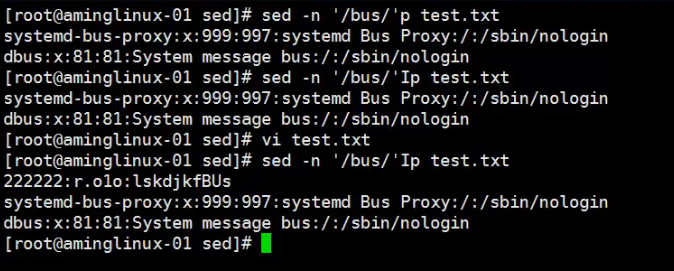
3、匹配大写字母的字符使用字母“I”
4、删除某些行
将删除1-25行后的内容在屏幕显示,原文件内容不影响
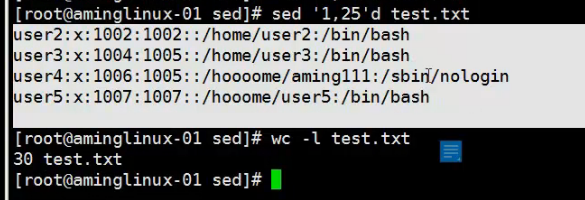
删除原文件1-25行并在屏幕显示

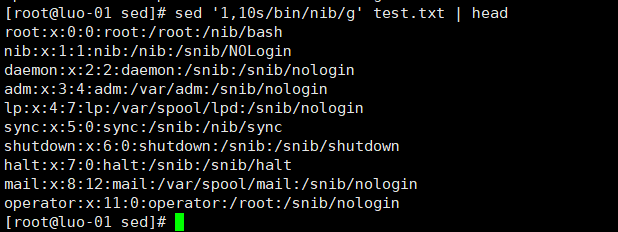
5、替换字符或字符串
将前10行中bin替换为nib,s为执行替换串操作,g为全局替换
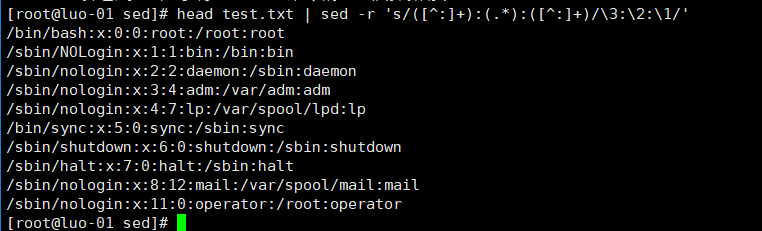
6、调换位置
将第一段与最后一段替换位置,以:分隔,作为参考对象
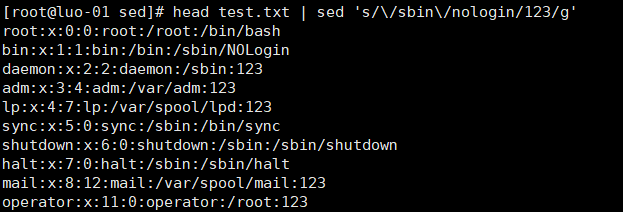
7、将/sbin/nologin替换为123
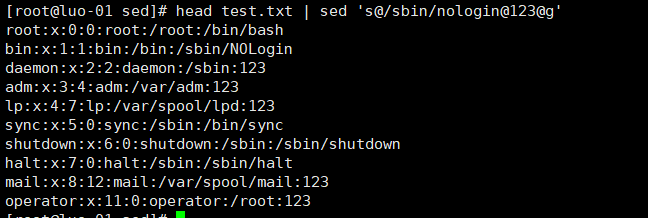
或者
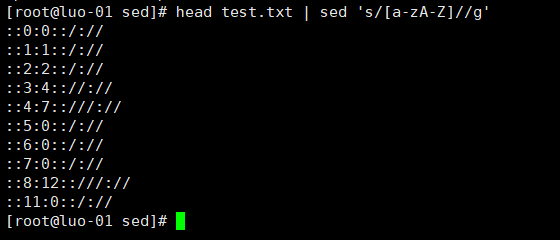
8、把文档中所有英文字母全部删除(即用空格代替)
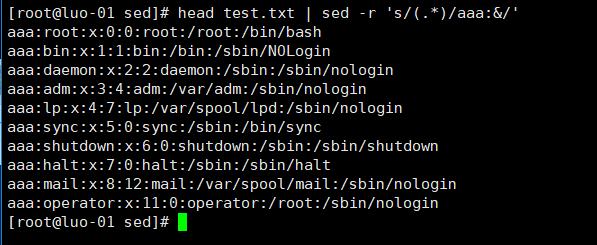
9、将所有行行首加上固定字符串aaa:
二、awk工具的使用
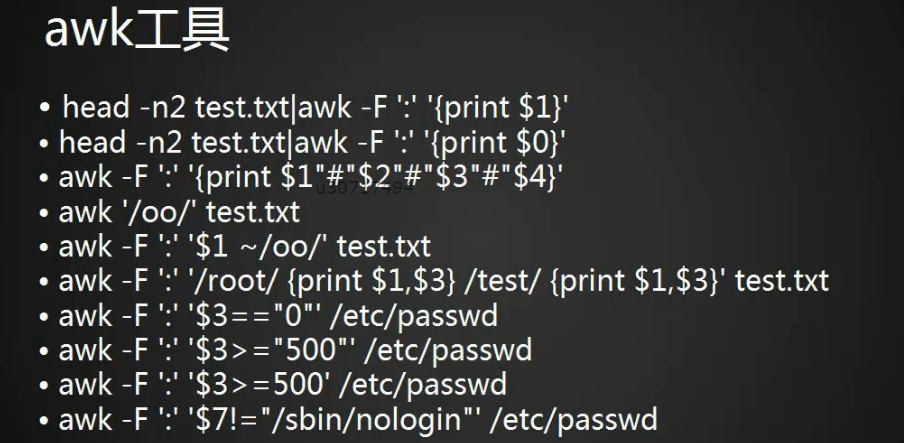
1、-F指定分隔符‘:’将第一段打印出来,$1为第一段以此类推,不加-F默认以空格为分隔符。
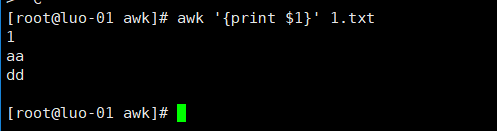
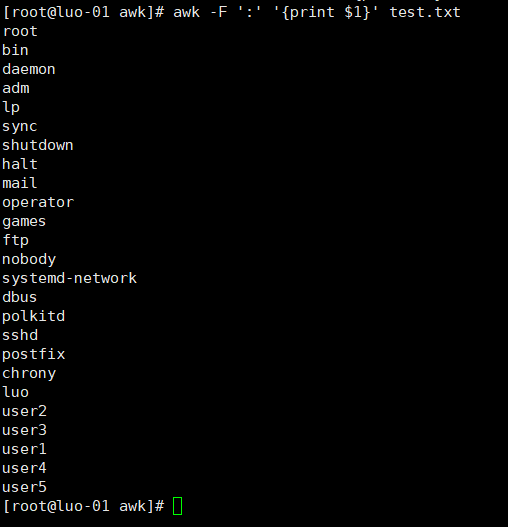
打印多行
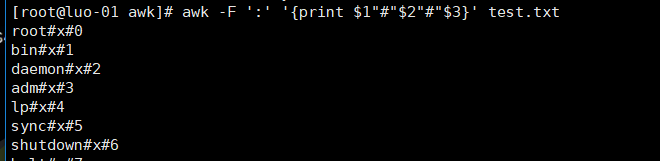
2、指定以#打印出分隔的内容
3、匹配功能
把包含oo的行打印出来
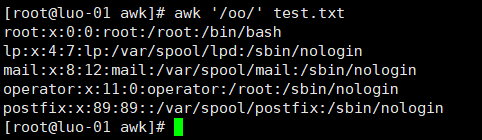
只打印第一段包含oo的行(~即为匹配的意思)

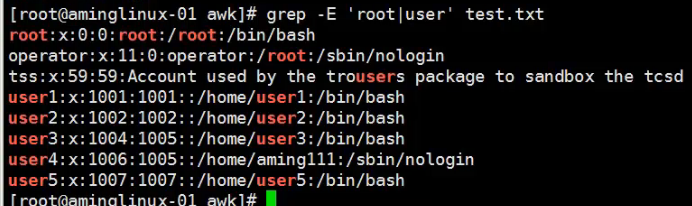
4、匹配包含root的第一段和第三段的内容,同时匹配包含user的第一段、第三段、第四段的内容,


检查
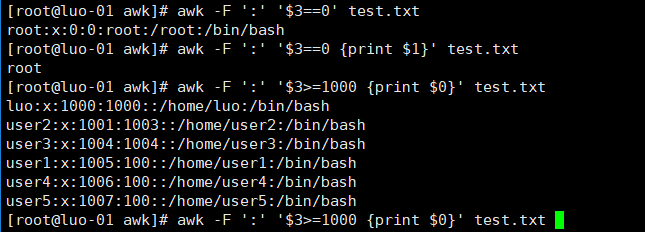
5、打印第三段等于0的行,输出第一段的内容,或者打印第三段大于等于1000,输出全部行内容
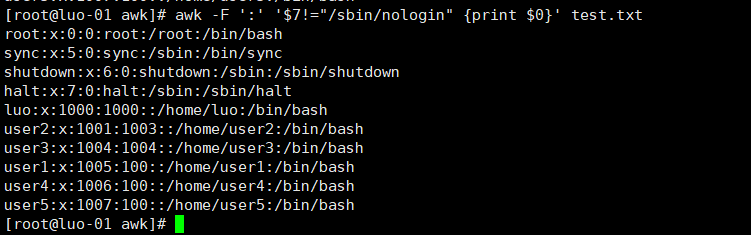
6、打印第七段不等于/sbin/nologin的行
7、两个字段相互比较的需求

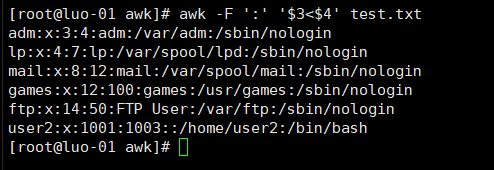
打印第三段小于第四段的行
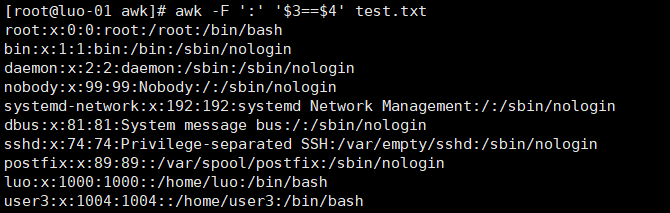
打印第三段等于第四段的行
8、打印第三段大于5,并且第三段小于7的行(&&为并且的意思)

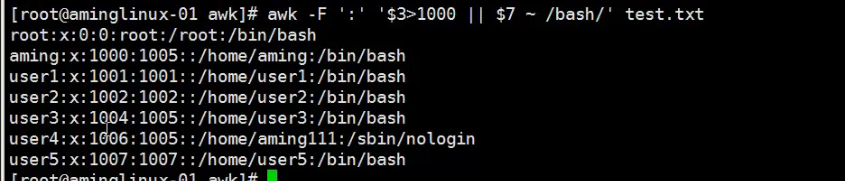
9、打印第三段大于1000或者第七段等于/sbin/nologin的行

或者匹配第七段为bash的行
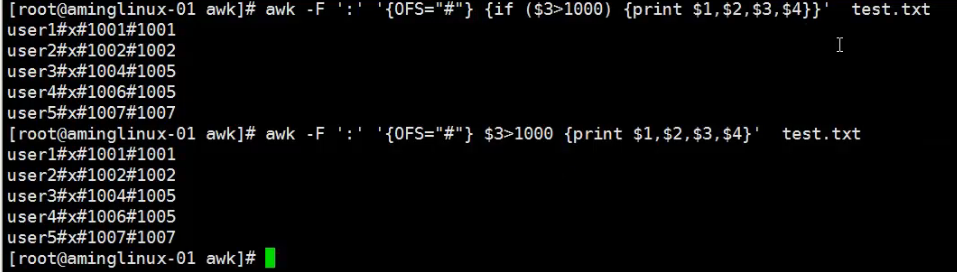
10、OFS用来指定print时用到的分隔符
打印出以#分隔符分隔的第三段大于1000或者第七段匹配为bash的行中的第一段、第三段、第七段的内容

加if与不加if的区别
11、NR表示行,NF表示段,打印并显示行号
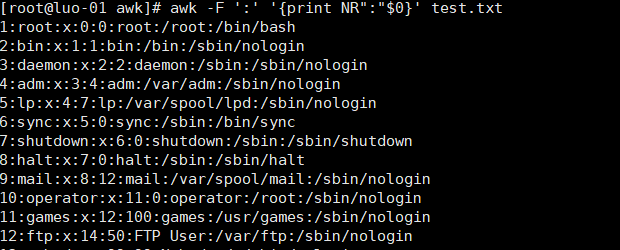
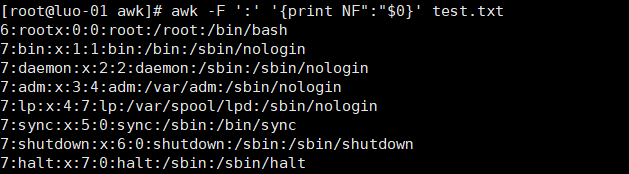
12、打印并显示段数
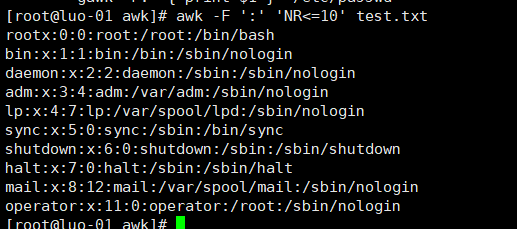
13、打印行数小于等于10的行
14、打印行数小于等于10并且第一段包含/root或者snyc/的行

15、赋值前三行第一段值为root并打印

16、打印前三行第一段字符串等于root的行

17、tot值从0开始循环将第三段的值相加,即第一行的第三段加第二行的第三段,依次叠加求和第三段的和。

0411正则之sed、awk 课堂笔记







awk语法结构:
awk -F ':' 'BEGIN{语句} {if(条件){语句1;语句2;语句3} } END{语句}' filename
打印某行到某行之间的内容
sed -n '/tss/,/sas/p' /etc/passwd
sed转换大小写
1. 把每个单词的第一个小写字母变大写:
sed 's/\b[a-z]/\u&/g' filename
2. 把所有小写变大写:
sed 's/[a-z]/\u&/g' filename
3. 大写变小写:
sed 's/[A-Z]/\l&/g' filename
sed在某一行最后添加一个数字
sed -r 's/(^a.*)/\1 12/' test
sed -r 's/^a.*/& 12/' test
打印1到100行含某个字符串的行
sed -n '1,100{/abc/p}' 1.txt
awk 中使用外部shell变量
a=2; echo "a:b:c:d"|awk -F ":" -v get_a=$a '{print $get_a}'
awk 合并一个文件
awk 'NR==FNR {a[$1]=$2} NR>FNR {print $0,a[$1]}' 1.txt 2.txt
说明:
awk '{print NR,FNR}' 1.txt 2.txt //首先理解NR和FNR的不同(awk支持同时操作多个文件内容)
当NR==FNR其实就是第一个文件的内容
当NR>FNR,其实就是第二个文件的内容
把一个文件多行连接成一行
方法一:
a=`cat file`;echo $a
方法二:
awk '{printf("%s ",$0)}' file
方法三:
cat file |xargs
awk中gsub函数的使用
awk 'gsub(/www/,"abc")' /etc/passwd // passwd文件中把所有www替换为abc
awk -F ':' 'gsub(/www/,"abc",$1) {print $0}' /etc/passwd // 替换$1中的www为abc
awk 截取指定多个域为一行
用awk指定分隔符把文本分为若干段。如何把相同段的内容弄到一行?
以/etc/passwd为例,该文件以":"作为分隔符,分为了7段。
for i in `seq 1 7`
do
awk -F ':' -v a=$i '{printf $a " "}' /etc/passwd
echo
done
过滤两个或多个关键词
grep -E '123|abc' filename // 找出文件(filename)中包含123或者包含abc的行
egrep '123|abc' filename //用egrep同样可以实现
awk '/123|abc/' filename // awk 的实现方式
awk用print打印单引号
awk 'BEGIN{print "a'"'"'s"}'
awk 'BEGIN{print "a'\''s"}'
awk 'BEGIN{print "a\"s"}'

















 3162
3162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









