




背景
如果是用 point-wise 的方法, 根据ctr做倒排, 会出现 high similar items were clustered together 的现象. 相似的item扎堆, 这种体验并不友好.
MMR
Maximal Marginal Relevance .
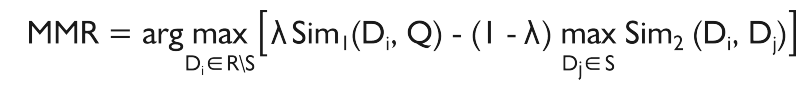
详见参考[2].
大致思想: 给定一个Query, 召回了一些文档A. 要从集合A中选一个大小为k的子集
A
k
A_k
Ak 呈现给用户. 每挑选一个元素i时, 综合考虑
A
k
A_k
Ak 的多样性和与Query相关性.
submodular diversification
思想
对
A
k
A_k
Ak的评分函数为:
(1)
ρ
(
A
k
)
=
α
×
d
(
A
k
)
+
(
1
−
α
)
∑
a
i
∈
A
k
s
(
a
i
)
\rho(A_k)=\alpha \times d(A_k)+(1-\alpha)\sum_{a_i\in A_k} s(a_i) \tag 1
ρ(Ak)=α×d(Ak)+(1−α)ai∈Ak∑s(ai)(1)
where
A
k
A_k
Ak is a subset of
A
A
A of size k.
s
(
a
)
s(a)
s(a) means the relevance between item
a
a
a and the current customer.
d
(
A
k
)
d(A_k)
d(Ak) is the measure of the diversity of
A
k
A_k
Ak.
the optimal subset is given by:
(2)
A
k
∗
:
=
arg
max
A
k
∈
A
,
∣
A
k
∣
=
k
ρ
(
A
k
)
A_k^*:= \underset{{A_k\in A, |A_k|=k}}{\arg \max} \rho(A_k) \tag 2
Ak∗:=Ak∈A,∣Ak∣=kargmaxρ(Ak)(2)
落地
给出多样性的具体描述:
(2)
d
(
A
k
)
=
∑
i
k
∑
j
i
d
i
s
t
a
n
c
e
(
a
i
,
a
j
)
d(A_k)=\sum_i^k \sum_j^i distance(a_i,a_j) \tag 2
d(Ak)=i∑kj∑idistance(ai,aj)(2)
(3)
d
i
s
t
a
n
c
e
(
a
i
,
a
j
)
=
v
i
r
t
u
a
l
C
a
t
e
D
i
s
t
a
n
c
e
(
a
i
,
a
j
)
∗
s
p
a
n
W
e
i
g
h
t
(
∣
i
−
j
∣
)
distance(a_i,a_j)=virtualCateDistance(a_i,a_j)*spanWeight(|i-j|) \tag 3
distance(ai,aj)=virtualCateDistance(ai,aj)∗spanWeight(∣i−j∣)(3)
虚拟类目相似度与item间距综合考虑.
Eq(2) is a special case of the NP-hard (Non-deterministic Polynomial time problem) maximum set cover problem.
We have to use an iterative greedy procedure to obtain a near-optimal solution.
(5) A i + 1 = A i ∪ { arg max a ∈ A − A i ρ ( A i ∪ { a } ) } A_{i+1}=A_i \cup \{\underset{a\in A-A_i}{\arg\max} \rho(A_i\cup \{a\})\} \tag 5 Ai+1=Ai∪{a∈A−Aiargmaxρ(Ai∪{a})}(5)
simple wide used solution
分享一种很简单, 应用也很广泛的做法.
定义两个元素之间的相似度
d
i
s
t
a
n
c
e
(
i
,
j
)
∈
{
0
,
1
}
distance(i,j) \in \{0,1\}
distance(i,j)∈{0,1}, 电商推荐中可以认为两个商品同类目,同店铺, 同品牌 等, 命中其一就是相似.
d
i
s
t
a
n
c
e
(
a
i
,
a
j
)
=
{
0
,
a
i
与
a
j
类
目
相
等
,
作
者
相
等
.
.
.
1
,
o
t
h
e
r
s
distance(a_i,a_j) = \begin{cases} 0 & , a_i 与 a_j 类目相等,作者相等... \\ 1 &, others \end{cases}
distance(ai,aj)={01,ai与aj类目相等,作者相等...,others
定义元素和集合之间的相似度
d
i
s
t
a
n
c
e
(
S
,
a
)
=
∑
b
∈
S
d
i
s
t
a
n
c
e
(
a
,
b
)
distance(S,a)=\underset{b\in S} {\sum} distance(a,b)
distance(S,a)=b∈S∑distance(a,b)
那么迭代过程就是:
(10)
A
i
+
1
=
A
i
∪
{
arg
max
a
∈
A
−
A
i
,
d
i
s
t
a
n
c
e
(
A
i
,
a
)
=
0
s
(
a
)
}
A_{i+1}=A_i \cup \{ \underset{a\in A-A_i, distance(A_i,a)=0} {\arg\max} s(a) \} \tag {10}
Ai+1=Ai∪{a∈A−Ai,distance(Ai,a)=0argmaxs(a)}(10)
即在所有满足打散的结果中选取最相关的那个.
mmr&rule mix rerank

伪代码.
参考
- Adaptive, Personalized Diversity for Visual Discovery
- min-presentation, MMR

















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









