






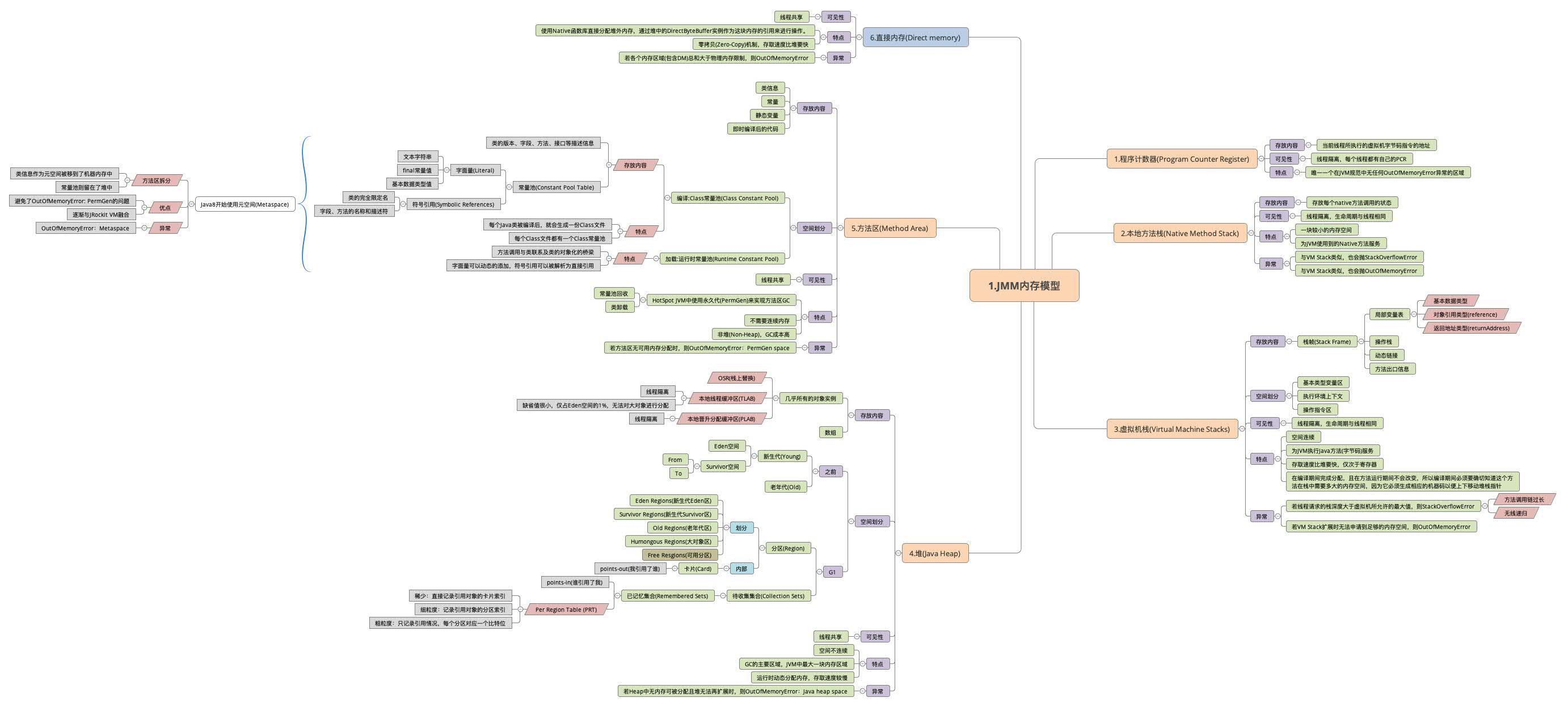
一、JMM内存模型
主要分为六块:程序计数器、本地方法栈、虚拟机栈、堆、方法区以及堆外内存。
- 程序计数器:存储当前线程所执行的字节码指令地址;
- 本地方法栈:存储本地native方法状态;
- 虚拟机栈:主要是栈帧,局部变量表、方法出口顺序出栈压栈这些,其实就是JVM给每一个线程开辟的工作内存,默认1M;
- 堆:作为JVM管理的最大一块内存,主要存储几乎所有的对象示例,但并非绝对,因为可以OSR栈上替换,比如简单的VO拆解成标量栈上分配;
- 方法区:主要是常量池、类信息,比如编译期的Class常量池、加载后的运行时常量池。方法区在Java8之后被拆分,类信息作为元数据空间被移到了机器内存中,常量池则留在了堆中,主要是为了避免触碰VM内存上限;
- 堆外内存:比如内存映射,通过Native函数直接分配堆外内存,作零拷贝;
线程安全的就是计数器、本地方法栈、虚拟机栈,线程隔离、同生共死,而堆和方法区是线程共享的,比如我在堆里分配一块内存要加锁要线程同步。所以就有TLAB这种线程专用的内存区域来提高分配效率,也有PLAB作为线程专用的对象晋升的内存区域。
这里解释两个概念:
本地线程缓冲区(TLAB):因为堆是线程共享的,每次对象分配都需要进行线程同步,拉低了分配效率。JVM利用一个线程专用的内存分配区域来避免这种冲突,以提升效率。每个线程使用自己的TLAB,并内部维护一个动态阈值(refill_waste值,表示TLAB的使用度,默认为64)。TLAB缺省值很小,仅占Eden空间的1%,所以无法对大对象进行担保分配。
栈上替换(OSR):即栈上分配和标量替换,是指经过JIT实时编译后对象被拆散为标量类型分配在栈上,或将对象的属性视为独立局部变量在栈上分配
关于方法区中的字符串常量池(String Constant Pool),它在HotSpot VM里的实现是一个StringTable类,一个Hash表,默认长度是1009,在每个HotSpot VM的实例中只有一份,被所有的类共享。
字符串构建,都会使用到String.intern()这个Native方法:
1、在Java7之前,若常量池中已经存在这个String,则返回该字符串的引用;若没有,则将其加入常量池中,并返回该字符串的引用;
2、在Java7之后,若常量池中没有该字符串时,则将其加入堆中并在常量池中存储该字符串的引用,然后返回该引用;
1. JVM的GC
在Java7之前,Heap是这样的:新生代(Young)和老年代(Old),新生代可分为Eden空间和Survivor空间,Survivor又分为两个独立的From Survivor和To Survivor。

JVM中,怎样为一个普通对象分配内存呢?
1、JVM首先为新生对象在Eden区中申请一块内存区域;
2、当Eden区空间不够时,触发一次 Young GC,在此期间JVM将Eden区所有存活的对象移动到其中一块Survivor区;
3、如果Survivor区放不下,那么将剩下的存活了一定GC次数的对象提升到老年代;
4、当老年代空间不够时,触发一次Full GC;
5、Full GC后,如果Survivor区及老年代仍然无法存放从Eden区复制过来的对象,则意味着JVM无法为新生对象分配内存,即OOM;
JVM一般,频繁收集生命周期短的Young,较少收集生命周期较长的Old,很少或基本不收集的PermGen。JVM在进行内存分配时有三个原则:
- 对象优先在Eden区分配;
- 大对象通过老年代担保,直接进入老年代,所以要避免临时大对象产生;
- 长期存活的对象进入老年代;
常见的Full GC原因:
显式的System.gc()方法调用;
Allocation Failure引起的Full GC;
ClassLoader很多而永久代/元数据空间很小引发的Full GC;
对象晋升失败,比如新生代提升速度过快而Survivor和老年代空间不够,触发Full GC;
并发模式失败,比如CMS由于浮动垃圾需要预留空间进行内存分配但内存碎片严重,放不下晋升过来的大对象,从而引发Full GC;
二、垃圾收集器
大体上是这样的:
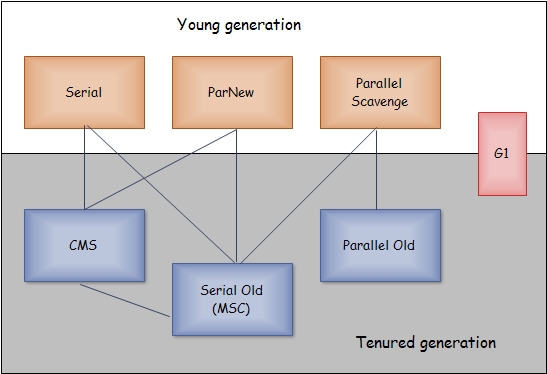
下面,我们来说说我们最常用到的是CMS和G1。
1. CMS收集器
CMS的回收算法分为这么几个阶段:
- 初始标记(STW)
- 并发标记
- 重新标记(STW)
- 并发清除
CMS通过三色标记法,进行垃圾收集:
白:该对象未被标记;
灰:该对象被标记了,但其引用的对象还没有被标记完;
黑:该对象被标记了,并且其引用的对象也都被标记完成;三色标记法的基本逻辑是:
- 起初所有的对象都是白色;
- 扫描出所有可达对象标记为灰色,放入待处理队列;
- 拿出待处理队列中的灰色对象,将其引用的对象标记为灰色放入队列,并将其自身标记为黑色;
- 通过写屏障事件捕获所有白色对象的内存修改,重新标色并放回队列。
CMS的缺点:
- 对CPU资源敏感:
默认启动的垃圾收集线程数 =(CPU核数+3)/ 4,也就是当CPU在4个以上时,垃圾收集线程占用不少于25%的CPU资源,且随着CPU数量的增加而下降。但当CPU不足4个时,CMS对应用程序的影响就变得非常大。如果本来CPU负载就比较大,还分出一半的资源去执行GC,很可能导致应用程序的执行速度忽然降低了50%,这让人无法接受; - 浮动垃圾问题:因为清理阶段与应用程序是并发运行的,这段时间产生的新的垃圾只能在下个GC周期才能清除;
- 内存碎片问题:CMS因为使用标记-清除算法,产生大量不连续的内存碎片,遇大对象分配时不得不提前触发Young GC;
2. G1收集器
G1是Java8之后的主流垃圾收集器,主要是因为它提供了GC的并发性(部分GC过程与应用程序交替执行)和并行性(回收期间,多个GC线程同时工作,有效利用多核CPU)。而且会基于GC停顿时间来自适应性调整新生代和老年代比例,以及对象晋升年龄。
Java7之后,Heap空间被整合为一个个可以不连续的Region,同时在Region内部,同样支持使用分代收集的方法,回收粒度更细了。Region在用途上也分为Eden Regions(新生代Eden区)、Survivor Regions(新生代Survivor区)、Old Regions(老年代区)、Humongous Regions(大对象区),而每个Region内部都由一个个Card组成。
Card标识Region最小可用粒度,所有Region的Card都会记录在全局Card Table表中:
1、分配的对象会占用物理上连续的若干个Card,被称为这个Card脏化了(dirty card)。当查找分区内对象的引用时便可通过记录Card来查找该引用对象,即points-out,我引用了谁的关系。每次对内存的回收,也是对指定Region的Card进行处理。
2、Card Table数据结构是一个字节数组,用单字节映射着每一个Card。
除此之外,还存在全局的待收集集合(CSet),CSet内部存在着已记忆集合(RSet),记录引用老年代对象的引用对象,即points-in,谁引用了我的关系。G1 GC时每次都会对新生代进行收集,因此引用新生代的对象,就不需要在RSet中记录。实际上,在GC时,只需对old->young和old->old的跨对象引用,才需要扫描对应的CSet中的RSet。
RSet在内部使用per_region_table(PRT)变量来记录Region的引用情况。由于RSet的记录要占用Region的空间,如果一个Region非常Hot,那么RSet占用的空间上升、分区的可用空间下降。所以,G1通过改变RSet的密度的方式来解决这个问题:
- 稀少:直接记录引用对象的Card索引;
- 细粒度:记录引用对象的Region索引;
- 粗粒度:只记录引用情况,每个Region对应一个比特位;
G1在整体上使用标记-整理算法,局部上(两个Region之间)则复制算法。那么JVM是如何进行GC的呢?分为这么几个阶段:
- 初始标记(STW)
- 根分区扫描
- 并发标记
- 重新标记(STW)
- 并发清除(Java10之后,是并行清除)
G1通过SATB(Snapshot at the beginning 起始快照)算法,进行垃圾收集。简单而言,就是在Region内比较一前一后两个PTAMS和NTAMS来找到变更的老年代引用关系,这可能会触发几次Young GC。基本的收集流程是:
1.根扫描:静态和本地对象被扫描;
2.更新RSet:处理dirty card队列;
3.处理RSet:检测从年轻代指向老年代的对象;
4.对象拷贝:拷贝存活的对象到survivor/old区域;
5.处理引用队列:软引用、弱引用、虚引用处理;
3. GC收集器失败情况
一般有两种:晋升失败,或并发模式失败。
- 晋升失败(Promotion Failed):
a、新生代提升过快,可能是新生代晋升阈值可能过小、Eden/Survivor空间过小,导致晋升速率提高;
b、Survivor或老年代空间不够,可能是内存回收周期过长、老年代回收阈值过大或者总的堆容量过小,导致老年代中短期存活对象的变多,在GC之前老年代被填满,从而触发Full GC;
c、老年代内存碎片严重,放不下大对象晋升 - 并发模式失败(Concurrent Mode Failure):
e、若CMS在运行期间预留的内存无法满足内存分配,则会出现“并发模式失败”,导致JVM启动后备预案:临时启用Serial Old串行收集器来重新进行老年代收集,使得停顿时间更长;
f、JVM参数 -XX:CMSInitiatingOccupancyFraction老年代回收阈值设置得太高,CMS触发的太晚,很容易导致大量的“并发模式失败”失败,性能反而降低。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









