# -*- coding: utf-8 -*-
import os
import cx_Oracle as cx
import pandas as pd
import datetime as dt
import schedule
import time
import requests
from threading import Thread
import dataframe_image as dfi
# 企业微信类
class Wechat:
def __init__(self, secret):
self.secret = secret
def access_token(self):
"""获取企业微信access_token"""
url = f'https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=wwed5e7f3fd1a3a553&corpsecret={self.secret}'
response = requests.get(url).json()
return response['access_token']
# Oracle数据库连接查询
def oracle_connect(sql):
con = cx.connect("admin/xxb20140415@192.168.3.16:1521/zzjdata")
cursor = con.cursor()
cursor.execute(sql)
column_s = [col[0] for col in cursor.description]
data = cursor.fetchall()
cursor.close()
con.close()
return data, column_s
# 生成销售数据报表SQL
def generate_sales_data_sql():
sql = """
with ls_sj as (
select * from subfhd a
where a.kdrq between trunc(sysdate-1,'mm') and trunc(sysdate-1)
and nvl(a.bz,' ')<>'会员礼品成本调整单'
and nvl(a.bz,' ')<>'¥'
and nvl(a.bm,' ')<>'积分兑换'
and nvl(a.posguid,' ')<>'10000'
),
sy as (
select * from subfhd a
where a.kdrq between add_months(trunc(sysdate-1,'month'),-1) and trunc(add_months(sysdate-1,-1))
and nvl(a.bz,' ')<>'会员礼品成本调整单'
and nvl(a.bz,' ')<>'¥'
and nvl(a.bm,' ')<>'积分兑换'
and nvl(a.posguid,' ')<>'10000'
),
dq as (
select c_mdfq,c_dq,
case when b.name='郑州地区' then to_char(a.c_dq) else to_char(b.name) end ds,
a.c_mdfq1,a.tjbh,a.mc
from gl_custom a
left join organization b on substr(a.tjbh,1,4)=b.code
where a.c_mdfq in ('豫南大区','豫北大区','郑州西区','郑州东区')
and (a.tj_tag='14' or a.tj_tag='40')
),
current_data as (
select
a.subbh,
nvl(a.jshj,0) zxs,
nvl(a.jshj,0)-nvl(a.dtp,0) jshj,
nvl(a.kds,0)-nvl(a.dskds,0) xxkds,
nvl(gl.zkd,0) zkds,
nvl(gl.glkd,0) glkd,
gl.zdglkd,
nvl(dp.kds,0) dpkd,
glrw.rw1,
glrw.rw2,
zdrw.zdrw1,
zdrw.zdrw2,
mz.pzs,
mz.ts,
mz.dhpzs,
mz.kcpzs,
mz.dxpzs,
mz.cbe,
mz.xqje,
mz.yjxqje
from (
select
a.subbh,
sum(a.jshj) jshj,
sum(a.kds) kds,
sum(a.ml) ml,
sum(a.zhml) zhml,
sum(a.dskds) dskds,
sum(a.dtp) dtp
from c_zkmdxshzb a
where a.kdrq between trunc(sysdate-1,'mm') and trunc(sysdate-1)
group by a.subbh
) a
left join (
select
subbh,
count(distinct lsh) kds
from (
select
a.subbh,
a.lsh,
count(distinct a.hedgehh) pzs
from ls_sj a
left join yw_kck b on a.hedgehh=b.hh
where b.fzflsx1<>'14' and b.fzflsx2 not in ('08031','08032','08034','08035','08038','08039','08040','08041')
group by a.subbh,a.lsh
)
where pzs=1
group by subbh
) dp on a.subbh=dp.subbh
left join c_mdglv gl on a.subbh=gl.subbh
left join c_zkmdspgczb mz on a.subbh=mz.subbh
left join (
select distinct
subbh,
nvl(rwsl,0) rw1,
nvl(rwje,0) rw2
from c_zbjlrwzk
where pzlb='解决方案关联率'
and nd=to_char(sysdate-1,'yyyy')
and LPAD(yf, 2, '0')=to_char(sysdate-1,'mm')
) glrw on a.subbh=glrw.subbh
left join (
select distinct
subbh,
nvl(rwsl,0) zdrw1,
nvl(rwje,0) zdrw2
from c_zbjlrwzk
where pzlb='重点品种关联率'
and nd=to_char(sysdate-1,'yyyy')
and LPAD(yf, 2, '0')=to_char(sysdate-1,'mm')
) zdrw on a.subbh=zdrw.subbh
),
previous_data as (
select
a.subbh,
nvl(a.jshj,0) zxs,
nvl(a.jshj,0)-nvl(a.dtp,0) jshj,
nvl(a.kds,0)-nvl(a.dskds,0) xxkds,
nvl(a.abc,0) abc,
nvl(gl.syzkd,0) zkds,
nvl(gl.syglkd,0) glkd,
nvl(dp.kds,0) dpkd
from (
select
a.subbh,
sum(a.jshj) jshj,
sum(a.kds) kds,
sum(a.ml) ml,
sum(a.dskds) dskds,
sum(a.zdpzxs) abc,
sum(a.dtp) dtp
from c_zkmdxshzb a
where a.kdrq between add_months(trunc(sysdate-1,'month'),-1) and trunc(add_months(sysdate-1,-1))
group by a.subbh
) a
left join (
select
subbh,
count(distinct lsh) kds
from (
select
a.subbh,
a.lsh,
count(distinct a.hedgehh) pzs
from sy a
left join yw_kck b on a.hedgehh=b.hh
where b.fzflsx1<>'14'
and b.fzflsx2 not in ('08031','08032','08034','08035','08038','08039','08040','08041')
group by a.subbh,a.lsh
)
where pzs=1
group by subbh
) dp on a.subbh=dp.subbh
left join c_mdglv gl on a.subbh=gl.subbh
)
select
'四大区' as LEVEL_NAME,
NULL as REGION_NAME,
NULL as CITY_NAME,
NULL as DISTRICT_NAME,
round(sum(a.rw2)/nullif(sum(a.rw1),0),4) as 关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end as 关联率,
(case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end)-
(case when nvl(sum(b.zkds),0)=0 then 0 else round(sum(b.glkd)/sum(b.zkds),4) end) as 关联率环比,
round(sum(a.zdrw2)/nullif(sum(a.zdrw1),0),4) as 重点品种关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.zdglkd)/sum(a.zkds),4) end as 重点品种关联率,
(case when nvl(sum(a.xxkds),0)=0 then 0 else round(sum(a.dpkd)/sum(a.xxkds),4) end)-
(case when nvl(sum(b.xxkds),0)=0 then 0 else round(sum(b.dpkd)/sum(b.xxkds),4) end) as 一单一品率环比,
round((nvl(sum(a.pzs*a.ts),0)-nvl(sum(a.dhpzs),0))/nullif(sum(a.pzs*a.ts),0),6) as 商品满足率,
case when nvl(sum(a.kcpzs),0)<>0 then round(sum(a.dxpzs)/sum(a.kcpzs),6) else 0 end as 动销率,
case when nvl(sum(a.cbe)/30,0)<>0 then round((sum(a.xqje)+sum(a.yjxqje)*0.5)/sum(a.cbe)/30,2) else 0 end as 效期存销比
from dq i
left join current_data a on i.tjbh=a.subbh
left join previous_data b on i.tjbh=b.subbh
group by '四大区'
union all
select
'大区' as LEVEL_NAME,
i.c_mdfq as REGION_NAME,
NULL as CITY_NAME,
NULL as DISTRICT_NAME,
round(sum(a.rw2)/nullif(sum(a.rw1),0),4) as 关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end as 关联率,
(case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end)-
(case when nvl(sum(b.zkds),0)=0 then 0 else round(sum(b.glkd)/sum(b.zkds),4) end) as 关联率环比,
round(sum(a.zdrw2)/nullif(sum(a.zdrw1),0),4) as 重点品种关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.zdglkd)/sum(a.zkds),4) end as 重点品种关联率,
(case when nvl(sum(a.xxkds),0)=0 then 0 else round(sum(a.dpkd)/sum(a.xxkds),4) end)-
(case when nvl(sum(b.xxkds),0)=0 then 0 else round(sum(b.dpkd)/sum(b.xxkds),4) end) as 一单一品率环比,
round((nvl(sum(a.pzs*a.ts),0)-nvl(sum(a.dhpzs),0))/nullif(sum(a.pzs*a.ts),0),6) as 商品满足率,
case when nvl(sum(a.kcpzs),0)<>0 then round(sum(a.dxpzs)/sum(a.kcpzs),6) else 0 end as 动销率,
case when nvl(sum(a.cbe)/30,0)<>0 then round((sum(a.xqje)+sum(a.yjxqje)*0.5)/sum(a.cbe)/30,2) else 0 end as 效期存销比
from dq i
left join current_data a on i.tjbh=a.subbh
left join previous_data b on i.tjbh=b.subbh
group by i.c_mdfq
union all
select
'地市' as LEVEL_NAME,
i.c_mdfq as REGION_NAME,
i.ds as CITY_NAME,
NULL as DISTRICT_NAME,
round(sum(a.rw2)/nullif(sum(a.rw1),0),4) as 关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end as 关联率,
(case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end)-
(case when nvl(sum(b.zkds),0)=0 then 0 else round(sum(b.glkd)/sum(b.zkds),4) end) as 关联率环比,
round(sum(a.zdrw2)/nullif(sum(a.zdrw1),0),4) as 重点品种关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.zdglkd)/sum(a.zkds),4) end as 重点品种关联率,
(case when nvl(sum(a.xxkds),0)=0 then 0 else round(sum(a.dpkd)/sum(a.xxkds),4) end)-
(case when nvl(sum(b.xxkds),0)=0 then 0 else round(sum(b.dpkd)/sum(b.xxkds),4) end) as 一单一品率环比,
round((nvl(sum(a.pzs*a.ts),0)-nvl(sum(a.dhpzs),0))/nullif(sum(a.pzs*a.ts),0),6) as 商品满足率,
case when nvl(sum(a.kcpzs),0)<>0 then round(sum(a.dxpzs)/sum(a.kcpzs),6) else 0 end as 动销率,
case when nvl(sum(a.cbe)/30,0)<>0 then round((sum(a.xqje)+sum(a.yjxqje)*0.5)/sum(a.cbe)/30,2) else 0 end as 效期存销比
from dq i
left join current_data a on i.tjbh=a.subbh
left join previous_data b on i.tjbh=b.subbh
group by i.c_mdfq, i.ds
union all
select
'地区' as LEVEL_NAME,
i.c_mdfq as REGION_NAME,
i.ds as CITY_NAME,
i.c_mdfq1 as DISTRICT_NAME,
round(sum(a.rw2)/nullif(sum(a.rw1),0),4) as 关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end as 关联率,
(case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.glkd)/sum(a.zkds),4) end)-
(case when nvl(sum(b.zkds),0)=0 then 0 else round(sum(b.glkd)/sum(b.zkds),4) end) as 关联率环比,
round(sum(a.zdrw2)/nullif(sum(a.zdrw1),0),4) as 重点品种关联率目标,
case when nvl(sum(a.zkds),0)=0 then 0 else round(sum(a.zdglkd)/sum(a.zkds),4) end as 重点品种关联率,
(case when nvl(sum(a.xxkds),0)=0 then 0 else round(sum(a.dpkd)/sum(a.xxkds),4) end)-
(case when nvl(sum(b.xxkds),0)=0 then 0 else round(sum(b.dpkd)/sum(b.xxkds),4) end) as 一单一品率环比,
round((nvl(sum(a.pzs*a.ts),0)-nvl(sum(a.dhpzs),0))/nullif(sum(a.pzs*a.ts),0),6) as 商品满足率,
case when nvl(sum(a.kcpzs),0)<>0 then round(sum(a.dxpzs)/sum(a.kcpzs),6) else 0 end as 动销率,
case when nvl(sum(a.cbe)/30,0)<>0 then round((sum(a.xqje)+sum(a.yjxqje)*0.5)/sum(a.cbe)/30,2) else 0 end as 效期存销比
from dq i
left join current_data a on i.tjbh=a.subbh
left join previous_data b on i.tjbh=b.subbh
group by i.c_mdfq, i.ds, i.c_mdfq1
"""
return sql
def add_summary_row(df):
"""
添加汇总行(最后一行)
"""
summary = {
'地区': '汇总',
'关联率目标': df['关联率目标'].mean(),
'关联率': df['关联率'].mean(),
'关联率达成率': df['关联率达成率'].mean(),
'关联率环比': df['关联率环比'].mean(),
'重点品种关联率目标': df['重点品种关联率目标'].mean(),
'重点品种关联率': df['重点品种关联率'].mean(),
'重点品种关联率达成率': df['重点品种关联率达成率'].mean(),
'一单一品率环比': df['一单一品率环比'].mean(),
'商品满足率': df['商品满足率'].mean(),
'动销率': df['动销率'].mean(),
'效期存销比': df['效期存销比'].mean()
}
# 转换为 DataFrame 并追加
summary_df = pd.DataFrame([summary])
return pd.concat([df, summary_df], ignore_index=True)
# 生成并保存图表
def create_sales_report_by_region(path, df):
try:
if df.empty:
raise ValueError("查询结果为空,无法生成报表")
# 添加达成率列
df['关联率达成率'] = df['关联率'] / df['关联率目标'].replace(0, pd.NA)
df['重点品种关联率达成率'] = df['重点品种关联率'] / df['重点品种关联率目标'].replace(0, pd.NA)
df['关联率达成率'] = df['关联率达成率'].fillna(0)
df['重点品种关联率达成率'] = df['重点品种关联率达成率'].fillna(0)
report_cols = [
'地区', '关联率目标', '关联率', '关联率达成率', '关联率环比',
'重点品种关联率目标', '重点品种关联率', '重点品种关联率达成率',
'一单一品率环比', '商品满足率', '动销率', '效期存销比'
]
format_dict = {
'关联率目标': '{:.2%}',
'关联率': '{:.2%}',
'关联率达成率': '{:.2%}',
'关联率环比': '{:+.2%}',
'重点品种关联率目标': '{:.2%}',
'重点品种关联率': '{:.2%}',
'重点品种关联率达成率': '{:.2%}',
'一单一品率环比': '{:+.2%}',
'商品满足率': '{:.2%}',
'动销率': '{:.2%}',
'效期存销比': '{:.2f}'
}
image_paths = []
current_date = dt.datetime.now()
date_str = current_date.strftime('%m月%d号')
file_date_str = current_date.strftime('%Y%m%d')
# 第一张图:四大区汇总 + 各大区数据
four_regions_summary = df[df['LEVEL_NAME'] == '四大区'].copy()
region_summary = df[df['LEVEL_NAME'] == '大区'].copy()
if not four_regions_summary.empty or not region_summary.empty:
combined_data = pd.concat([region_summary, four_regions_summary])
combined_data = combined_data.sort_values('关联率环比', ascending=False)
combined_data['地区'] = combined_data.apply(lambda x: x['REGION_NAME'], axis=1)
combined_data = combined_data[report_cols]
# ✅ 添加汇总行
combined_data = add_summary_row(combined_data)
img_create(
data=combined_data,
title=f"截止到{date_str}本月",
dq="四大区汇总",
last_row=len(combined_data) - 1, # ✅ 指定为最后一行
format_dict=format_dict,
subset=['关联率环比'],
path=path,
file_mc=f'四大区汇总各项过程指标_{file_date_str}'
)
image_paths.append(os.path.join(path, f'四大区汇总各项过程指标_{file_date_str}.png'))
# 第二张图:各地市数据 + 四大区汇总
city_summary = df[df['LEVEL_NAME'] == '地市'].copy()
if not city_summary.empty:
combined_data = pd.concat([city_summary, four_regions_summary])
combined_data = combined_data.sort_values('关联率环比', ascending=False)
combined_data['地区'] = combined_data['CITY_NAME']
combined_data = combined_data[report_cols]
# ✅ 添加汇总行
combined_data = add_summary_row(combined_data)
img_create(
data=combined_data,
title=f"截止到{date_str}本月",
dq="各地市汇总",
last_row=len(combined_data) - 1,
format_dict=format_dict,
subset=['关联率环比'],
path=path,
file_mc=f'各地市汇总各项过程指标_{file_date_str}'
)
image_paths.append(os.path.join(path, f'各地市汇总各项过程指标_{file_date_str}.png'))
# 第三至第六张图:每个大区的地区数据 + 该大区汇总
four_regions = ['豫南大区', '豫北大区', '郑州西区', '郑州东区']
for region in four_regions:
region_data = df[(df['LEVEL_NAME'] == '地区') & (df['REGION_NAME'] == region)].copy()
region_summary = df[(df['LEVEL_NAME'] == '大区') & (df['REGION_NAME'] == region)].copy()
if not region_data.empty or not region_summary.empty:
combined_data = pd.concat([region_data, region_summary])
combined_data = combined_data.sort_values('关联率环比', ascending=False)
combined_data['地区'] = combined_data.apply(lambda x: x['DISTRICT_NAME'] if pd.notna(x['DISTRICT_NAME']) else region, axis=1)
combined_data = combined_data[report_cols]
combined_data = add_summary_row(combined_data)
img_create(
data=combined_data,
title=f"截止到{date_str}本月",
dq=f"{region}各地区明细",
last_row=len(combined_data) - 1,
format_dict=format_dict,
subset=['关联率环比'],
path=path,
file_mc=f'{region}各地区明细_{file_date_str}'
)
image_paths.append(os.path.join(path, f'{region}各地区明细_{file_date_str}.png'))
return image_paths
except Exception as e:
print(f"生成报表图片失败: {str(e)}")
return []
# 生成图片
def img_create(data, title, dq, last_row, format_dict, subset, path, file_mc):
"""
生成带样式的表格图片
:param data: 传入的数据体
:param title: 表头前缀(如日期)
:param dq: 表头地区数据
:param last_row: 最后一行是否染色(填len(df)-1或None)
:param format_dict: 数据格式字典
:param subset: 需要渐变染色的列名列表
:param path: 文件保存路径
:param file_mc: 文件名
"""
try:
# 定义函数:设置最后一行样式
def highlight_last_row(s):
if s.name == last_row:
return ['background-color: #FFFF00; color: #FF0000; font-weight: bold'] * len(s)
else:
return [''] * len(s)
# 添加样式
styler = data.style.hide(axis='index').set_caption(
f'{title}{dq}各项过程指标'
).set_table_styles([
# 标题样式
{'selector': 'caption',
'props': [('font-weight', 'bold'),
('font-family', 'Microsoft Yahei'),
('color', '#000000'),
('background-color', '#F4B084'),
('font-size', '24px'),
('border-top', '2px solid #000000'),
('border-left', '2px solid #000000'),
('border-right', '2px solid #000000')]},
# 表头样式
{'selector': 'th',
'props': [('font-family', 'Microsoft Yahei'),
('border', '1px solid #000000'),
('color', '#000000'),
('background-color', '#F4B084'),
('font-size', '18px'),
('vertical-align', 'center'),
('text-align', 'center'),
('white-space', 'nowrap')]},
# 数据单元格样式
{'selector': 'td',
'props': [('font-family', 'Microsoft Yahei'),
('border', '1px solid #000000'),
('font-size', '16px'),
('vertical-align', 'center'),
('text-align', 'center'),
('white-space', 'nowrap')]}
]).format(format_dict, na_rep='-').background_gradient(subset=subset, cmap='RdYlGn')
# ✅ 应用最后一行样式
styler = styler.apply(highlight_last_row, axis=1)
# 设置表格宽度为自动调整
styler.set_table_styles([
{'selector': 'table',
'props': [('width', 'auto'),
('margin-left', 'auto'),
('margin-right', 'auto')]},
], overwrite=False)
# 保存图片
dfi.export(styler, os.path.join(path, f'{file_mc}.png'), dpi=100)
print(f"✅ 图表 {file_mc} 已生成")
except Exception as e:
print(f"❌ 图表生成失败: {e}")
# 推送图片到企业微信
def application_push_image(access_token, image_path, user_id="037565", agent_id="1000077"):
try:
if not os.path.exists(image_path):
print(f"图片文件不存在: {image_path}")
return None
with open(image_path, 'rb') as f:
files = {'media': f}
upload_url = f'https://qyapi.weixin.qq.com/cgi-bin/media/upload?access_token={access_token}&type=image'
upload_response = requests.post(upload_url, files=files).json()
if 'media_id' not in upload_response:
print(f"图片上传失败: {upload_response}")
return None
media_id = upload_response['media_id']
send_url = f'https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={access_token}'
payload = {
"touser": user_id,
"msgtype": "image",
"agentid": agent_id,
"image": {"media_id": media_id},
"safe": 0
}
response = requests.post(send_url, json=payload).json()
return response
except Exception as e:
print(f"图片发送失败: {str(e)}")
return None
# 发送销售数据报表截图给指定用户
def send_sales_report(path, user_id="037565"):
try:
wechat = Wechat('tXNMrgcTgeV3IAqJhWB7mOe_bcKe9EtdCDze_75mGeY')
access_token = wechat.access_token()
if not access_token:
raise Exception("获取企业微信access_token失败")
sql = generate_sales_data_sql()
data, columns = oracle_connect(sql)
df = pd.DataFrame(data, columns=columns)
print("查询结果前5行:")
print(df.head())
image_paths = create_sales_report_by_region(path, df)
if not image_paths:
raise Exception("报表图片生成失败")
for image_path in image_paths:
if os.path.exists(image_path):
result = application_push_image(access_token, image_path, user_id)
if result and result.get('errcode') == 0:
print(f"{dt.datetime.now()} - {os.path.basename(image_path)} 推送成功")
os.remove(image_path)
else:
print(f"{dt.datetime.now()} - {os.path.basename(image_path)} 推送失败: {result}")
return True
except Exception as e:
print(f"{dt.datetime.now()} - 销售数据报表推送失败: {str(e)}")
return False
# 定时任务
def run_scheduler(path):
schedule.every().day.at("16:00").do(send_sales_report, path=path)
print(f"{dt.datetime.now()} - 正在执行首次测试...")
send_sales_report(path)
while True:
schedule.run_pending()
time.sleep(60)
# 主程序入口
if __name__ == '__main__':
print(f'程序启动时间: {dt.datetime.now()}')
output_path = r'D:\销售数据报表'
if not os.path.exists(output_path):
os.makedirs(output_path)
scheduler_thread = Thread(target=run_scheduler, args=(output_path,))
scheduler_thread.daemon = True
scheduler_thread.start()
try:
while True:
time.sleep(60)
except KeyboardInterrupt:
print("程序已停止")
把上述代码,也修改为推送至个人037565和利用群机器人推送至企微群
最新发布




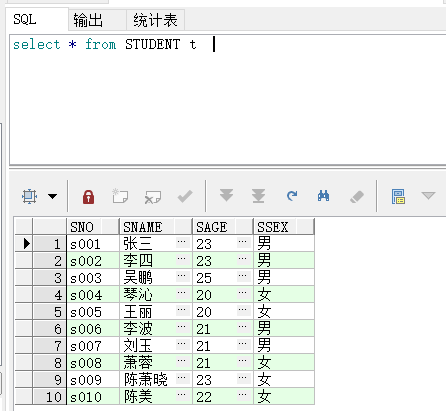
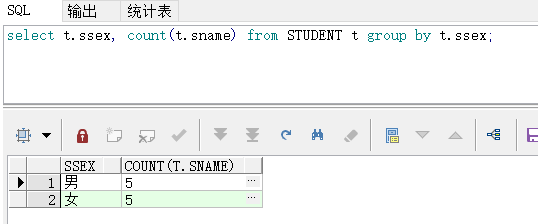
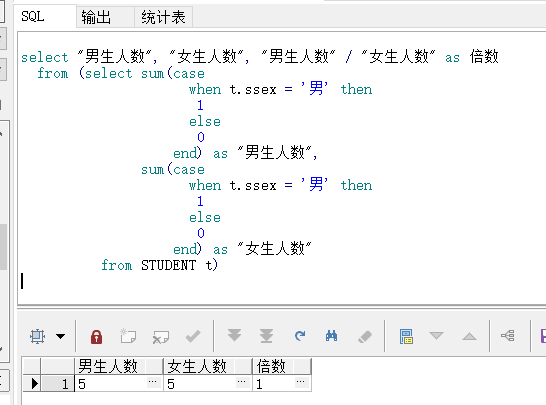
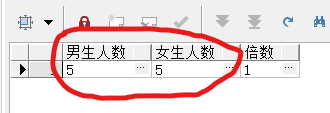
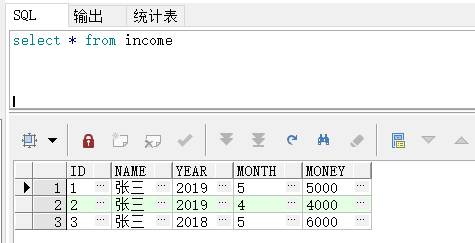
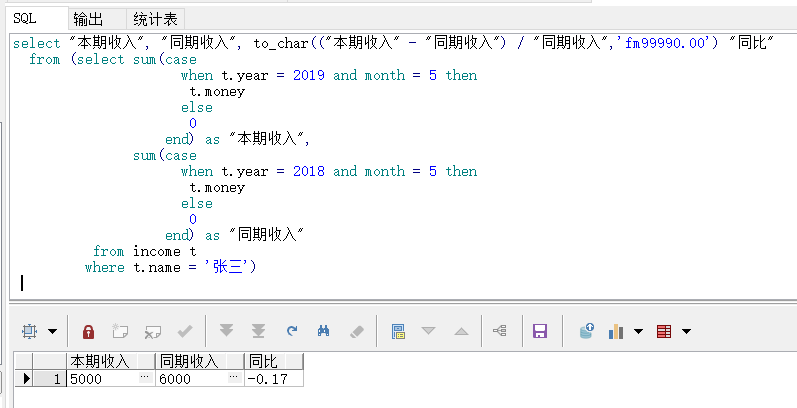
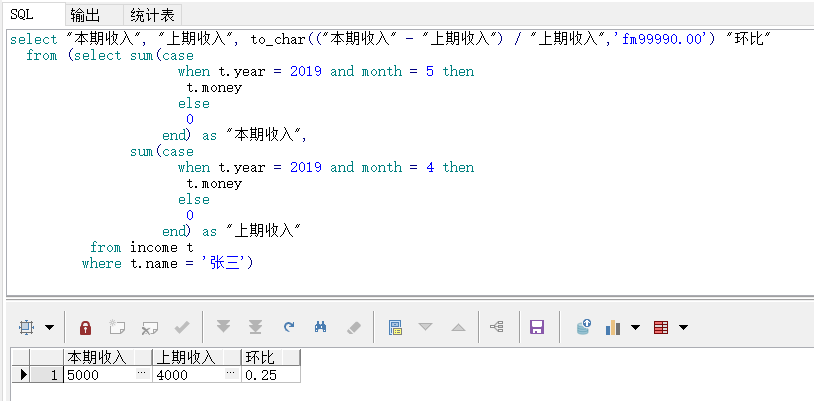
 本文深入讲解了SQL中sum和case when结合使用的技巧,包括按性别区分学生人数、计算男生人数是女生的倍数,以及如何求同比和环比增长率的具体实现方法。
本文深入讲解了SQL中sum和case when结合使用的技巧,包括按性别区分学生人数、计算男生人数是女生的倍数,以及如何求同比和环比增长率的具体实现方法。


















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









