




消费
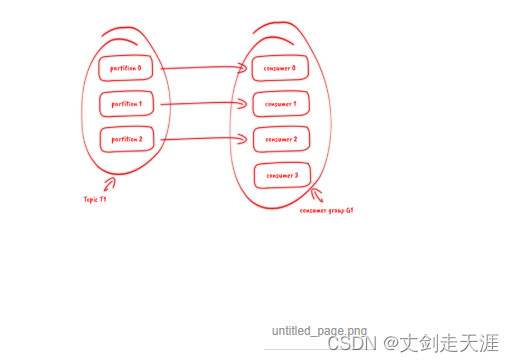
订阅topic是以一个消费组来订阅的,一个消费组里面可以有多个消费者。同一个消费组中的两个消费者,不会同时消费一个partition。换句话来说,就是一个partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费。因此,如果消费组内的消费者如果比partition多的话,那么就会有个别消费者一直空闲。
API
订阅topic时,可以用正则表达式,如果有新topic匹配上,那能自动订阅上。
offset的保存
一个消费组消费partition,需要保存offset记录消费到哪,以前保存在zk中,由于zk的写性能不好,以前的解决方法都是consumer每隔一分钟上报一次。这里zk的性能严重影响了消费的速度,而且很容易出现重复消费。
在0.10版本后,kafka把这个offset的保存,从zk总剥离,保存在一个名叫__consumeroffsets topic的topic中。写进消息的key由groupid、topic、partition组成,value是偏移量offset。topic配置的清理策略是compact。总是保留最新的key,其余删掉。一般情况下,每个key的offset都是缓存在内存中,查询的时候不用遍历partition,如果没有缓存,第一次就会遍历partition建立缓存,然后查询返回。
确定consumer group位移信息写入__consumers_offsets的哪个partition,具体计算公式:
__consumers_offsets partition = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount) //groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,默认是50个分区。
分配partition--reblance
生产过程中broker要分配partition,消费过程这里,也要分配partition给消费者。类似broker中选了一个controller出来,消费也要从broker中选一个coordinator,用于分配partition。
下面从顶向下,分别阐述一下
- 怎么选coordinator。
- 交互流程。
- reblance的流程。
选coordinator
- 看offset保存在那个partition
- 该partition leader所在的broker就是被选定的coordinator
这里我们可以看到,consumer group的coordinator,和保存consumer group offset的partition leader是同一台机器。
交互流程
把coordinator选出来之后,就是要分配了
整个流程是这样的:
- consumer启动、或者coordinator宕机了,consumer会任意请求一个broker,发送ConsumerMetadataRequest请求,broker会按照上面说的方法,选出这个consumer对应coordinator的地址。
- consumer 发送heartbeat请求给coordinator,返回IllegalGeneration的话,就说明consumer的信息是旧的了,需要重新加入进来,进行reblance。返回成功,那么consumer就从上次分配的partition中继续执行。
reblance流程
- consumer给coordinator发送JoinGroupRequest请求。
- 这时其他consumer发heartbeat请求过来时,coordinator会告诉他们,要reblance了。
- 其他consumer发送JoinGroupRequest请求。
- 所有记录在册的consumer都发了JoinGroupRequest请求之后,coordinator就会在这里consumer中随便选一个leader。然后回JoinGroupRespone,这会告诉consumer你是follower还是leader,对于leader,还会把follower的信息带给它,让它根据这些信息去分配partition
5、consumer向coordinator发送SyncGroupRequest,其中leader的SyncGroupRequest会包含分配的情况。
6、coordinator回包,把分配的情况告诉consumer,包括leader。
当partition或者消费者的数量发生变化时,都得进行reblance。
列举一下会reblance的情况:
- 增加partition
- 增加消费者
- 消费者主动关闭
- 消费者宕机了
- coordinator自己也宕机了
kafka支持3种消息投递语义
At most once:最多一次,消息可能会丢失,但不会重复
At least once:最少一次,消息不会丢失,可能会重复
Exactly once:只且一次,消息不丢失不重复,只且消费一次(0.11中实现,仅限于下游也是kafka)
在业务中,常常都是使用At least once的模型,如果需要可重入的话,往往是业务自己实现。
At least once
先获取数据,再进行业务处理,业务处理成功后commit offset。
1、生产者生产消息异常,消息是否成功写入不确定,重做,可能写入重复的消息
2、消费者处理消息,业务处理成功后,更新offset失败,消费者重启的话,会重复消费
At most once
先获取数据,再commit offset,最后进行业务处理。
1、生产者生产消息异常,不管,生产下一个消息,消息就丢了
2、消费者处理消息,先更新offset,再做业务处理,做业务处理失败,消费者重启,消息就丢了
Exactly once
思路是这样的,首先要保证消息不丢,再去保证不重复。
- 生产者重做导致重复写入消息----生产保证幂等性
- 消费者重复消费---消灭重复消费,或者业务接口保证幂等性重复消费也没问题
由于业务接口是否幂等,不是kafka能保证的,所以kafka这里提供的exactly once是有限制的,消费者的下游也必须是kafka。所以一下讨论的,没特殊说明,消费者的下游系统都是kafka(注:使用kafka conector,它对部分系统做了适配,实现了exactly once)。
kafka(注:使用kafka conector,它对部分系统做了适配,实现了exactly once)。
生产者幂等性好做,没啥问题。
解决重复消费有两个方法:
- 下游系统保证幂等性,重复消费也不会导致多条记录。
- 把commit offset和业务处理绑定成一个事务。
本来exactly once实现第1点就ok了。
但是在一些使用场景下,我们的数据源可能是多个topic,处理后输出到多个topic,这时我们会希望输出时要么全部成功,要么全部失败。这就需要实现事务性。既然要做事务,那么干脆把重复消费的问题从根源上解决,把commit offset和输出到其他topic绑定成一个事务。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









