




先简单了解一下树
树
二叉树的定义:把满足以下两个条件的树型结构叫做二叉树。
(1)每个结点的度都不大于2;
(2)每个结点的孩子结点次序不能任意颠倒。(位于左边的孩子叫做左孩子,位于右边的孩子叫做右孩子。)
二叉树的结构是非线性的(因为二叉树也是树),每一个结点最多可有两个后继。
而且二叉树还是有序树,因为二叉树的子树有左右之分。
二叉树的五种基本形态:
(1)空二叉树
(2)只有根节点的二叉树
(3)只有左子树的二叉树(左子树仍为二叉树)
(4)只有右子树的二叉树(右子树也是二叉树)
(5)左右子树均非空的二叉树(左右子树均为二叉树)
因此,二叉树是通过上述五种基本形式的组合或嵌套而形式的。
满二叉树
每层结点都是满的,即每层结点都具有最大的结点数。
完全二叉树
结点数为n的二叉树,如果其中1—n位置序号的结点分别与满二叉树中1—n位置序号的结点一一对应,则为完全二叉树。
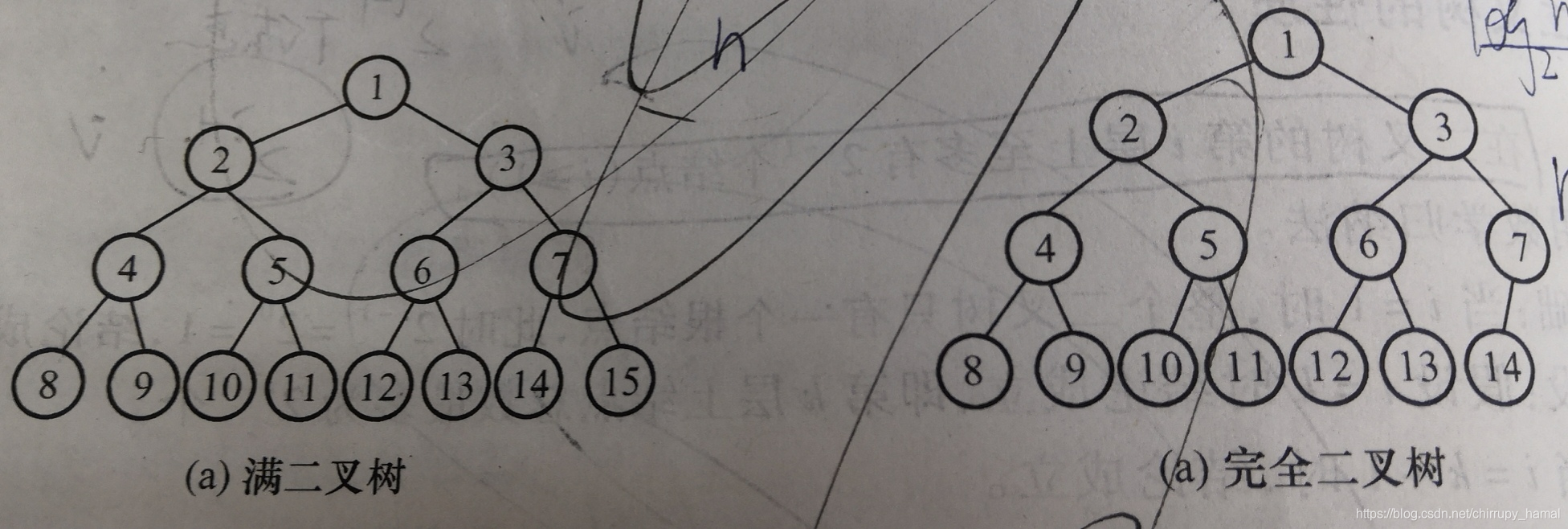
由此可见,满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
而且空二叉树既是完全二叉树,又是满二叉树。
二叉树的性质:
性质1:在二叉树的第i(i>=1)层上至多有2^(i-1)个结点。
性质2:深度为k(k>=1)的二叉树至多有2^k - 1个结点。
性质3:对任意一颗二叉树T,若终端结点数为n0,而其度数为2的结点数为n2,则n0=n2+1。
证明:
设二叉树中结点总数为n,n1为二叉树中度为1的结点总数。
因为二叉树中所有结点的度<=2,所以有n=n0+n1+n2
设二叉树中分支数目为B,因为除根节点外,每个结点均对应一个进入它的分支,所以有n=B+1
又因为二叉树中的分支都是由度为1和2的结点发出,所以分支数目为B=n1+2*n2
整理可得 n0=n2+1
性质4:具有n个结点的完全二叉树的深度为:对log2n向下取整(4.9->4)+1。
证明:
假设n个结点的完全二叉树的深度为k,
根据性质2可知,k-1层满二叉树的结点总数为n1=2^(k-1) - 1,k层满二叉树的结点总数为n2=2 ^ (k) - 1
显然有n1<n<=n2,进一步可以推出n1+1<= n <n2+1
将n1和n2代入,可得2k-1<= n <2k,即k-1<= log2n <k
因为k是整数,所以k-1=对log2n向下取整,所以k=对log2n向下取整+1。
性质5:对于具有n个结点的完全二叉树,如果按照从上到下和从左到右的顺序对二叉树中的所有结点从1开始顺序编号,则对于任意的序号为i的结点有:
(1)如i=1,则序号为i的结点就是根节点,无双亲结点;
如i>1,则序号为i的结点的双亲结点的序号为:对i/2向下取整。
(2)如2i>n,则序号为i的结点无左孩子;
如2i<=n,则序号为i的结点的左孩子结点的序号为2i。
(3)如2i+1>n,则序号为i的结点无右孩子;
如2i+1<=n,则序号为i的结点的右孩子结点的序号为2i+1。
性质6(个人总结):对于一个完全二叉树来讲,如果其中的一个结点连左孩子都没有,那注定该结点也不会有右孩子。
二叉树的存储结构
二叉树的存储结构有两种:顺序存储结构和链式存储结构。
(1)对于完全二叉树来说,可以将其数据元素逐层存放到一组连续的存储单元中。用一维数组作存储结构,将二叉树中编号为i的结点存放到数组的第i个分量中。根据二叉树的性质5(这里是从0开始编号),可得结点i的左孩子的位置为 LChild(i)=2 * i;右孩子的位置为 RChild(i)=2*i+1。即便使用顺序存储结构,二叉树仍是非线性的。

显然,这种存储方式对于一棵完全二叉树来说是非常方便的。因为对完全二叉树采用顺序存储结构既不浪费空间,又可以根据公式计算出每一个结点的左右孩子的位置。但是,对于一般的二叉树,必须用“虚结点”将其补成一棵“完全二叉树”来存储,这就会造成空间浪费。一种极端的情况,如图,从中可以看出,对于一个深度为k的二叉树,在最坏的情况下(每个结点只有右孩子的右单支树,当然还有左单支树。)需占用2k-1个存储单元,而实际该二叉树只有k个结点,空间的浪费太大,这是顺序存储结构的一大缺点。

(2)链式存储结构(一般都是以这种结构形式出现):对于任意的二叉树来说,从并不严格意义上来讲,每个结点只有两个孩子和一个双亲结点。可以设计每个结点至少包括三个域,(一般情况下,二叉树都是这样定义的。)依次是:数据域(data)用来记录该结点的信息,左孩子域(LChild)用来指向该结点的左孩子,右孩子域(RChild)用来指向该结点的右孩子。
二叉树的二叉链表定义如下
typedef int DataType;
typedef struct BTreeNode
{
DataType data;
struct BTreeNode *Left;
struct BTreeNode *Right;
} BTreeNode;
若一个二叉树含有n个结点,则它的二叉链表中必含有2n个指针域,其中必有n+1个空的链域。
证明:
分支数目B=n-1,即非空的链域有n-1个,故空链域有2n-(n-1)=n+1个。
代码
二叉树的三叉链表定义如下
typedef int DataType;
typedef struct BTreeNode
{
DataType data;
struct BTreeNode *Parent;//在二叉链表的基础上+Parent指针域
struct BTreeNode *Left;
struct BTreeNode *Right;
} BTreeNode;
三叉链表较二叉链表的优点是:找一个结点的双亲结点很方便。
二叉树的遍历
二叉树的遍历是指按一定规律对二叉树中的每个结点进行访问且仅访问一次。其中的“访问”可指计算二叉树中结点的数据信息,打印该结点的信息,也包括对结点进行任何其他操作。
那为什么需要对二叉树进行遍历呢?
二叉树是非线性结构数据,通过遍历可以将二叉树的结点访问一次且仅一次,从而得到访问结点的顺序序列。从这个意义上说,遍历操作就是将二叉树中的结点按照一定规律线性化的操作,目的在于将非线性化结构变成线性化的访问序列。二叉树的遍历操作是二叉树中最基本的运算。
二叉树的基本结构是由根结点、左子树和右子树三个基本单元组成的。因此,只要依次遍历这三部分,就遍历了整个二叉树。
如果用L、D、R分别表示遍历左子树、访问根结点、遍历右子树,那么对二叉树的遍历顺序就可以有6种方式。
(1)访问根,遍历左子树,遍历右子树,记作DLR。
(2)访问根,遍历右子树,遍历左子树,记作DRL。
(3)遍历左子树,访问根,遍历右子树,记作LDR。
(4)遍历左子树,遍历右子树,访问根,记作LRD。
(5)遍历右子树,访问根,遍历左子树,记作RDL。
(6)遍历右子树,遍历左子树,访问根,记作RLD。
如果规定按先左后右的顺序,那么就只剩下DLR、LDR和LRD三种。
根据对根的访问先后顺序的不同,分别称DLR为先序遍历或先根遍历,LDR为中序遍历或对称遍历,LRD为后序遍历。
注意:先序、中序、后序遍历是递归定义的,即在其子树中亦按相应规律进行遍历。显然,遍历操作是一个递归过程。
1、先序遍历(DLR)的操作过程:
若二叉树为空,则为空操作,否则依次执行如下3个操作:
(1)访问根结点;
(2)按先序遍历左子树;
(3)按先序遍历右子树。
2、中序遍历(LDR)的操作过程:
若二叉树为空,则为空操作,否则依次执行如下3个操作:
(1)按中序遍历左子树;
(2)访问根结点;
(3)按中序遍历右子树。
3、后序遍历(LRD)的操作过程:
(1)按后序遍历左子树;
(2)按后序遍历右子树;
(3)访问根结点。
4、二叉树的层序遍历
按照二叉树的层次,即从根结点层到叶结点层,同一层中按先左子树再右子树的次序遍历二叉树。
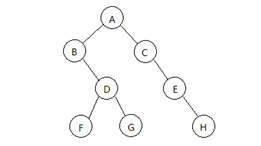
先序遍历:A、B、D、F、G、C、E、F
中序遍历:B、F、D、G、A、C、E、H
后序遍历:F、G、D、B、H、E、C、A
层序遍历:A、B、C、D、E、F、G、H
由遍历序列惟一确定一棵二叉树
1、给定一棵二叉树的前序和中序序列,可惟一确定一棵二叉树;
2、给定一棵二叉树的后序和中序序列,可惟一确定一棵二叉树。
注意:前序和后序序列是不能惟一确定一棵二叉树的。
把上图中B的右子树改为其左子树,它的先序和后序仍不变。所以前序和后序序列不能惟一确定一棵二叉树。
例如:用上述的前序和中序求证。
首先由前序序列得知二叉树的根为A,则其左子树的中序序列为{B,F,D,G},右子树的中序序列为{C,E,H}。
反过来得知左子树的前序序列必为{B,D,F,G},右子树的先序序列为{C,E,H}。
类似地,可由左子树的前序和中序序列构造A的左子树,由右子树的前序和中序序列构造A的右子树。
以此类推。其实,单单给出先序序列或者后序序列也可以唯一确定一棵二叉树,不过是在一定基础上,具体请参看代码。
二叉树的镜像:将二叉树放在平面的左侧,沿y轴对称的右侧就是二叉树的镜像。
二叉树的相关代码
二叉树

















 4272
4272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









