






package com.biejh.test0521;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.function.BiConsumer;
public class MapForEachTest{
@SuppressWarnings({"rawtypes", "unchecked"})
public static void main(String[] args){
Map map = new HashMap<>();
map.put("test1", "test01");
map.put("test2", "test02");
map.put("test3", "test03");
// 遍历方法一
System.out.println("******** 方法1");
for(Iterator<String> it = map.keySet().iterator(); it.hasNext();) {
String key = it.next();
System.out.println(key + "," + map.get(key));
}
// 遍历方法二
System.out.println("******** 方法2");
for(Iterator<Map.Entry<String, String>> it = map.entrySet().iterator(); it.hasNext();) {
Entry<String, String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "," + value);
}
// 遍历方法三
System.out.println("******** 方法3");
map.forEach((key, value) -> System.out.println(key + "," + value));
// 遍历方法四
System.out.println("******** 方法4");
map.forEach(new BiConsumer<String, String>(){
@Override
public void accept(String key, String value){
System.out.println(key + "," + value);
}
});
// 遍历方法五
System.out.println("******** 方法5");
map.values().forEach(System.out::println);;
}
}
简单说明一下:
代码片段的前两种方法是我们在jdk1.8出现前常用的对map做遍历的最常用的方法。方法一首先是将map的key遍历生成一个set,然后在对key进行遍历整个map采用get方法获取value。方法二则是将map先转换成EntrySet,然后再对set遍历采用entry的getKey和getValue方法取得key和value。讲到这里我们先来了解一下map接口的源码:
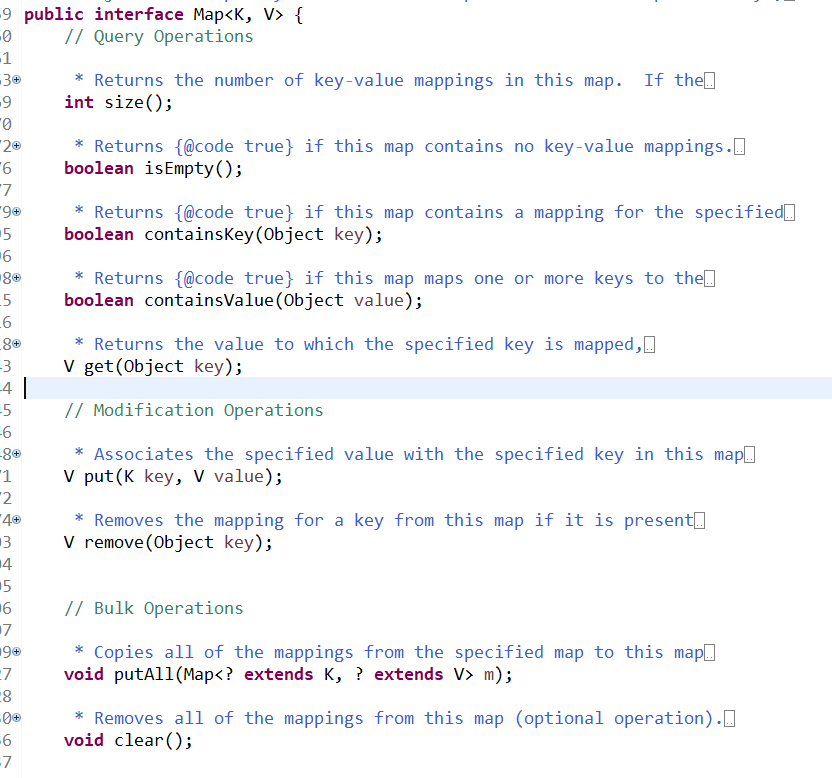
在1.8之前就有的常见方法就不做太多介绍了。

我们发现map接口里有一个内部接口Entry<K,V>,它里面有key和value的get方法。因此我们方法二其实直接使用了。既然我们map的实现是hashMap,那么我们这里就详细的看一下hashMap对Entry接口的实现:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}实现类是Node<K,V>包含成员变量hash,key,value以及下一个Node节点next。注意到我们代码片段里的hashCode方法出现了一个看似陌生的Objects类,其实Object我们并不陌生,但Objects可能就不一定很熟了。早在jdk1.7就出现了Objects类,里面的方法我们也稍作了解一下:
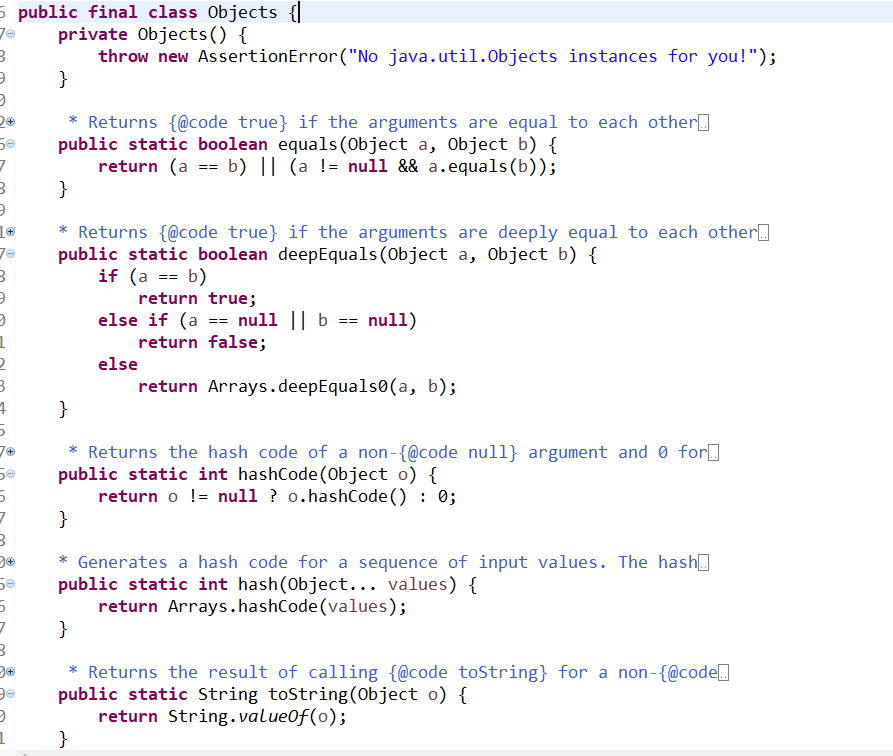


其实也还好了,代码并不是很难理解。我们在这里看到里面其实是对为空判断做了大量的静态方法定义。有简单的引用判断,也有深层次的equal判断。这些都是新的特性,我觉得在jvm的加载应用会很多:
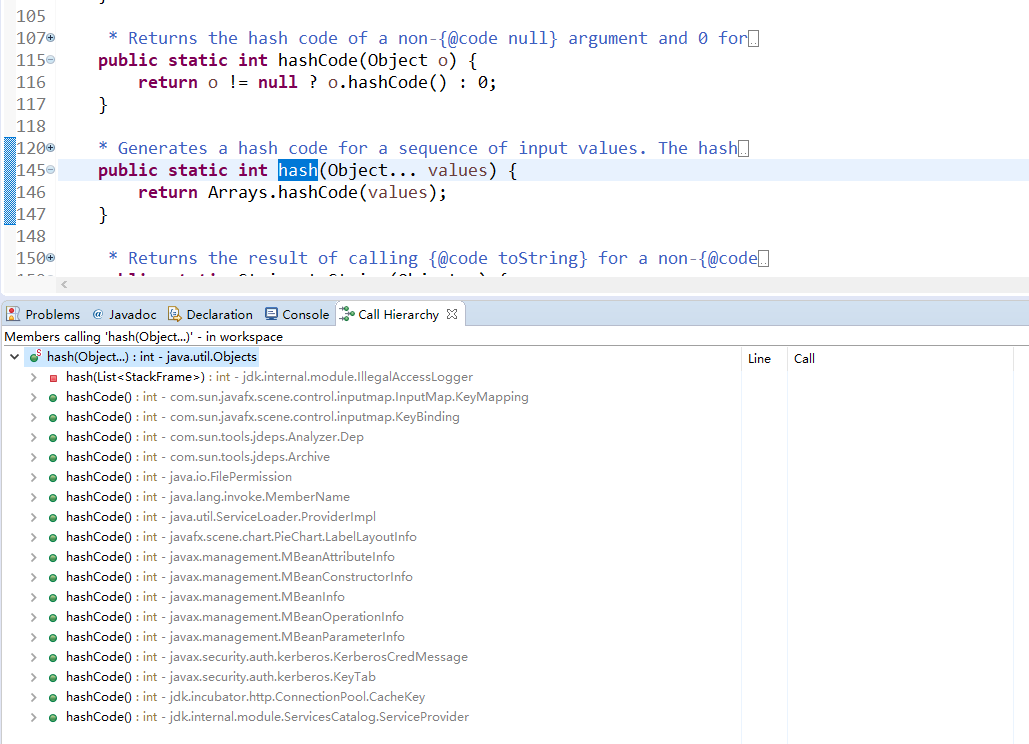
回到刚刚说的hashMap对entry接口的实现中的equal方法,它的判断是两个node的引用一样,或者是两个node的key和value分别对应的引用一致才返回true,否则都是返回false。
然后我们再回到文章开始的map遍历上,方法三,五其实是jdk1.8的lambda表达式,使用->对action的一种简写而已。而方法四完全就像我们在创建线程重写Runable方法一样,对BiComsumer的accept方法重写了而已。可能不太理解BiConsumer是什么,没有什么比源码要解释的更清楚了:
package java.util.function;
import java.util.Objects;
/**
* Represents an operation that accepts two input arguments and returns no
* result. This is the two-arity specialization of {@link Consumer}.
* Unlike most other functional interfaces, {@code BiConsumer} is expected
* to operate via side-effects.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #accept(Object, Object)}.
*
* @param <T> the type of the first argument to the operation
* @param <U> the type of the second argument to the operation
*
* @see Consumer
* @since 1.8
*/
@FunctionalInterface
public interface BiConsumer<T, U> {
/**
* Performs this operation on the given arguments.
*
* @param t the first input argument
* @param u the second input argument
*/
void accept(T t, U u);
/**
* Returns a composed {@code BiConsumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code BiConsumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default BiConsumer<T, U> andThen(BiConsumer<? super T, ? super U> after) {
Objects.requireNonNull(after);
return (l, r) -> {
accept(l, r);
after.accept(l, r);
};
}
}
注解@FunctionalInterface已经很清晰的说明了它是一个方法型接口,表示一个带有两个参数的无返回结构的操作,从jdk1.8开始出现。我们在test类里对这个方法型接口的accept方法实现了,其实可以理解为两个参数分别接收了map的key和value。
与其相对应的还有一个接口Consumer,表示的是只带一个参数的无返回的操作,那么我们对于非key-value结构只有一个value(比方说List,Set等)的数据做遍历是不是就可以通过重写Consumer的accept方法了。
package java.util.function;
import java.util.Objects;
/**
* Represents an operation that accepts a single input argument and returns no
* result. Unlike most other functional interfaces, {@code Consumer} is expected
* to operate via side-effects.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #accept(Object)}.
*
* @param <T> the type of the input to the operation
*
* @since 1.8
*/
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
/**
* Returns a composed {@code Consumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code Consumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
既然我们使用map的forEach方法,我们就看看map的forEach源码
/**
* Performs the given action for each entry in this map until all entries
* have been processed or the action throws an exception. Unless
* otherwise specified by the implementing class, actions are performed in
* the order of entry set iteration (if an iteration order is specified.)
* Exceptions thrown by the action are relayed to the caller.
*
* @implSpec
* The default implementation is equivalent to, for this {@code map}:
* <pre> {@code
* for (Map.Entry<K, V> entry : map.entrySet())
* action.accept(entry.getKey(), entry.getValue());
* }</pre>
*
* The default implementation makes no guarantees about synchronization
* or atomicity properties of this method. Any implementation providing
* atomicity guarantees must override this method and document its
* concurrency properties.
*
* @param action The action to be performed for each entry
* @throws NullPointerException if the specified action is null
* @throws ConcurrentModificationException if an entry is found to be
* removed during iteration
* @since 1.8
*/
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch (IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}这里我们看到了default关键字,其实这个并不奇怪,jdk1.8就对interface做了扩充,谁说interface里面的方法都是只定义不实现的呢?想想也是哈,如果jdk在后面的扩展中如果想对一个接口做一个扩展方法,如果没有default,是不是所有实现该接口的方法都得实现这个方法,这样的维护工作量要多大呢?所以default对我们jdk的扩展开发,作用还是非常之大的。
看到了吧,map的forEach方法其实跟我们的方法二有啥区别吗?除了对一些异常的强校验,是不是没有什么区别。
世界在进步,科技在发展,我们岂能不学习掌握新的知识?jdk版本已经1.10了,而我们目前的开发可能大部分还是使用1.6,1.7。是时候熟悉一波1.8,1.9甚至1.10了,再不学习就真的落伍了!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









