



 本文档详细介绍了使用Eclipse进行Web项目开发时遇到的各种问题及其解决方案,包括部署项目的路径配置、解决中文文件上传乱码问题的方法、避免Tomcat启动时出现警告的方式以及如何使非Servlet文件的更改生效。
本文档详细介绍了使用Eclipse进行Web项目开发时遇到的各种问题及其解决方案,包括部署项目的路径配置、解决中文文件上传乱码问题的方法、避免Tomcat启动时出现警告的方式以及如何使非Servlet文件的更改生效。
大体上可以分为这些问题:
部署(deploy)
撸码(code)
构建(build)
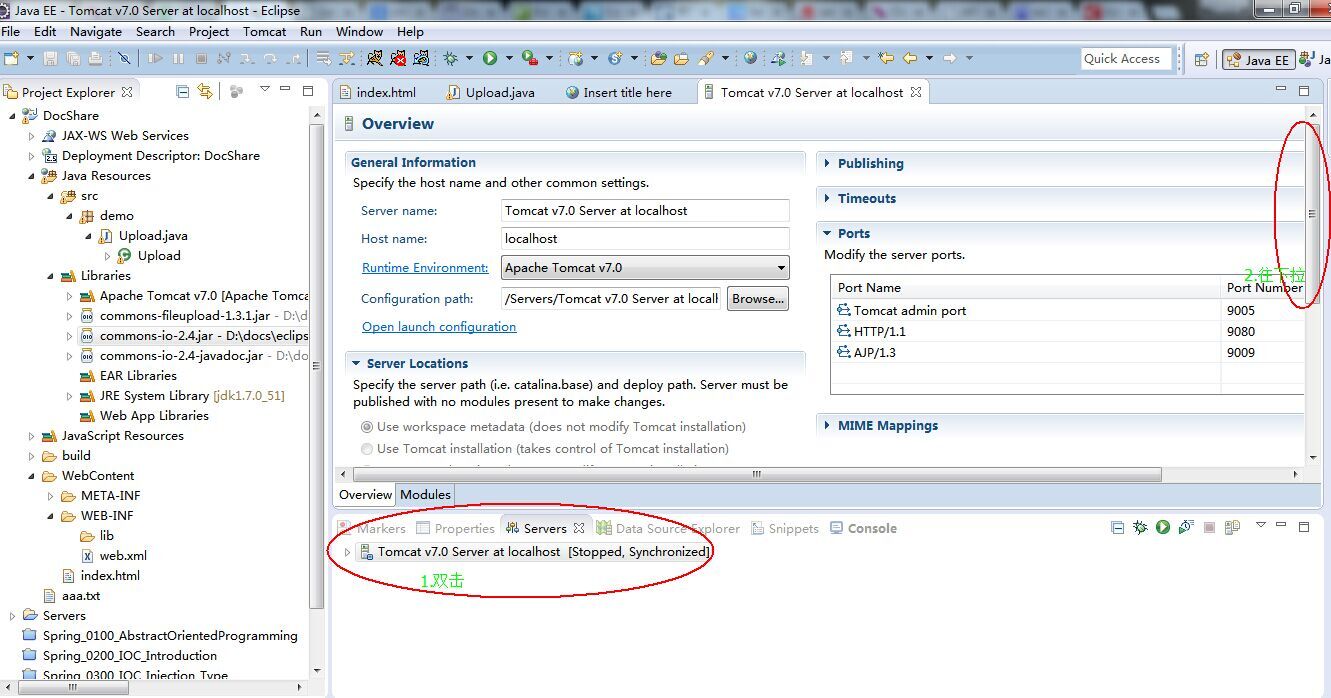
1.「deploy」Eclipse创建web项目并使用tomcat,空项目启动tomcat出warning:
提示信息为:
警告: [SetPropertiesRule]{Server/Service/Engine/Host/Context} Setting property 'source' to 'org.eclipse.jst.jee.server:DocShare' did not find a matching property.
解决方案:
这里DocShare是我的项目名。搜到的中文解决办法是,鼠标勾选Publish modual contexts to separat XML files:
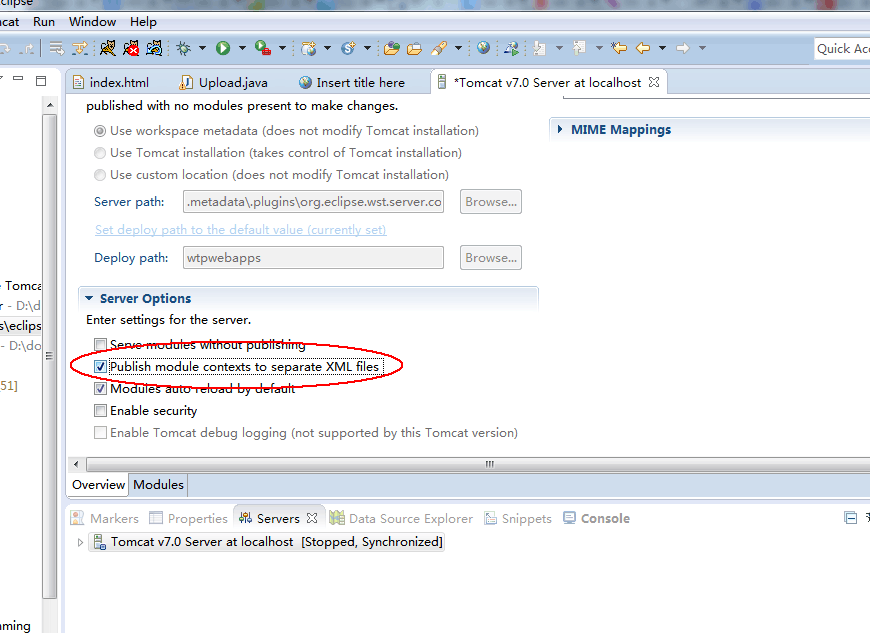
但是不管用!
stackoverflow上说了这个是warning是从tomcat6开始如果xml文件的dtd找不到就报warning。
那就不用解决了。
2.「code」javadoc
比如做文件上传功能时,使用了apache的commons-fileupload包,当然还要添加它依赖的commons-io包,然后从官网copy了sample代码运行,测试中文文件内容时乱码,而request和response等已经设定过编码了,所以google之。
发现String value=item.getString("UTF-8");这样一句代码,而官网给出的code没有utf-8的参数。
那么我怎么知道要添加这个utf-8的编码参数呢?javadoc。
问题是仅仅导入jar包是没有文档看到的,需要手动导入。

这里如果是添加本地javadoc,比如commons-fileupload的这个,添加到apidoc路径就好了,只要这个路径中index.html和package-list两个文件基本上就正确了;然后记得把包的优先级上调,否则还是可能出不来:

3. 「build」Eclipse创建的web项目,build path中添加jar包无效,先复制到WEB-INF/lib后再添加则有效
这个是Eclipse本身没做好,不像MyEclipse那么人性化。对策就是把jar包拷贝到lib路径,这用于编译。
4. 「deploy」Eclipse开发web项目,部署路径怎么搞?
(1)我用的是EclipseJee版本,另外安装了tomcat7,在eclipse中要新建server把自己装的这个tomcat配置好。
(2)默认Eclipse会把你的web项目部署到工作目录下
.metadata\.plugins\org.eclipse.wst.server.core\tmp0\wtpwebapps\项目名路径
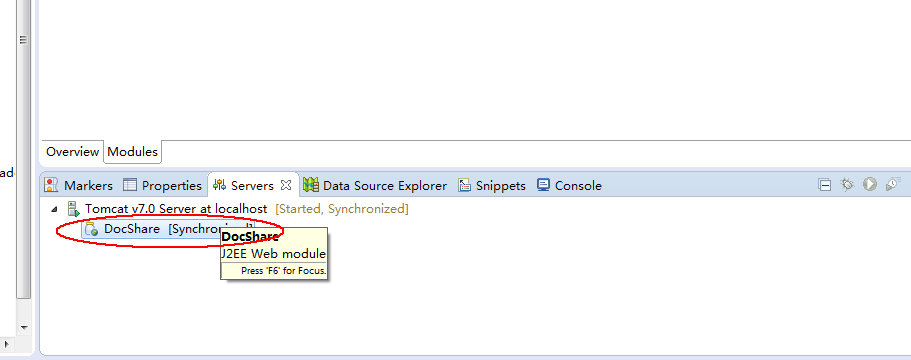
有时候觉得这个路径很难找到,幸运的是可以在eclipse中建立的tomcat server中配置它:
1.启动服务器,然后将服务器中的项目清空。
2.双击服务器会打开一个配置的文件,修改 Server Locations下为Use tomcat installation ...(原为 Use workspace metadata...), 再修改 Deploy path 为 webapps(原为 wtpwebapps),最后点关闭弹出提示是否保存 点yes
3.再把项目添加到服务器中,部署启动 这样就把项目发布到外面的tomcat文件下了
(参考:http://bbs.youkuaiyun.com/topics/390168868)

比如我设定D:\workspace\java\tomcat-deploy目录专门用于Eclipse中的web项目本地测试的部署路径。
设定完毕,ctrl+s保存,然后重新运行你的web项目,项目就部署在你新指定的路径了!
5. web项目中非servlet文件的修改(比如模版文件修改)不起作用,要重启tomcat才生效,怎么办?
因为webapp工程publish了,也就是部署到了另一个路径。
解决办法就是不让它publish。怎么搞呢?还是图形界面,tomcat界面的ServerOption中勾选Server modules without publishing:


















 6766
6766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









