






 本文深入探讨了YugaByte的YB-TServer组件,详细解释了其如何通过跨节点的Raft组进行数据复制,以及如何通过全局块缓存、节流压缩、优先级压缩队列、全局内存限制等策略优化资源利用效率。
本文深入探讨了YugaByte的YB-TServer组件,详细解释了其如何通过跨节点的Raft组进行数据复制,以及如何通过全局块缓存、节流压缩、优先级压缩队列、全局内存限制等策略优化资源利用效率。
YB-TServer The YB-TServer (short for YugaByte Tablet Server) is the process that does the actual IO for end user requests. Recall from the previous section that data for a table is split/sharded into tablets. Each tablet is composed of one or more tablet-peers depending on the replication factor. And each YB-TServer hosts one or more tablet-peers.
Note: We will refer to the “tablet-peers hosted by a YB-TServer” simply as the “tablets hosted by a YB-TServer”.
Below is a pictorial illustration of this in the case of a 4 node YugaByte universe, with one table that has 16 tablets and a replication factor of 3.
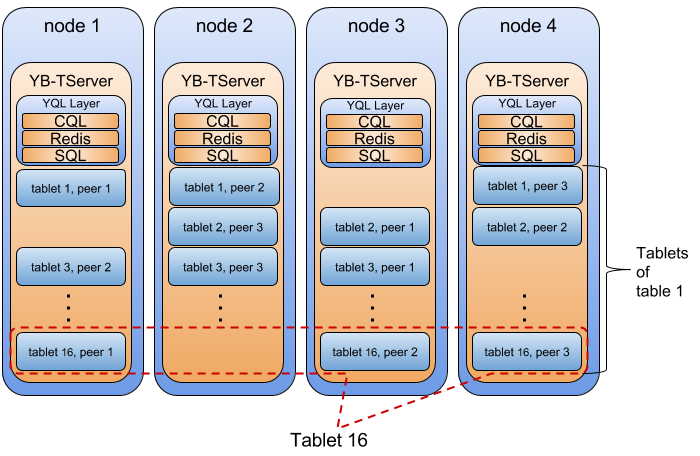 tserver_overview
tserver_overview
The tablet-peers corresponding to each tablet hosted on different YB-TServers form a Raft group and replicate data between each other. The system shown above comprises of 16 independent Raft groups. The details of this replication are covered in a previous section on replication.
Within each YB-TServer, there is a lot of cross-tablet intelligence built in to maximize resource efficiency. Below are just some of the ways the YB-TServer coordinates operations across tablets hosted by it:
Server-global block cache The block cache is shared across the different tablets in a given YB-TServer. This leads to highly efficient memory utilization in cases when one tablet is read more often than others. For example, one table may have a read-heavy usage pattern compared to others. The block cache will automatically favor blocks of this table as the block cache is global across all tablet-peers.
Throttled Compactions The compactions are throttled across tablets in a given YB-TServer to prevent compaction storms. This prevents the often dreaded high foreground latencies during a compaction storm.
Small/Large Compaction Queues Compactions are prioritized into large and small compactions with some prioritization to keep the system functional even in extreme IO patterns.
Server-global Memstore Limit Tracks and enforces a global size across the memstores for different tablets. This makes sense when there is a skew in the write rate across tablets. For example, the scenario when there are tablets belonging to multiple tables in a single YB-TServer and one of the tables gets a lot more writes than the other tables. The write heavy table is allowed to grow much larger than it could if there was a per-tablet memory limit, allowing good write efficiency.
Auto-Sizing of Block Cache/Memstore The block cache and memstores represent some of the larger memory-consuming components. Since these are global across all the tablet-peers, this makes memory management and sizing of these components across a variety of workloads very easy. In fact, based on the RAM available on the system, the YB-TServer automatically gives a certain percentage of the total available memory to the block cache, and another percentage to memstores.
Striping tablet load uniformly across data disks On multi-SSD machines, the data (SSTable) and WAL (RAFT write-ahead-log) for various tablets of tables are evenly distributed across the attached disks on a per-table basis. This ensures that each disk handles an even amount of load for each table. The YB-TServer (short for YugaByte Tablet Server) is the process that does the actual IO for end user requests. Recall from the previous section that data for a table is split/sharded into tablets. Each tablet is composed of one or more tablet-peers depending on the replication factor. And each YB-TServer hosts one or more tablet-peers.
Note: We will refer to the “tablet-peers hosted by a YB-TServer” simply as the “tablets hosted by a YB-TServer”.
Below is a pictorial illustration of this in the case of a 4 node YugaByte universe, with one table that has 16 tablets and a replication factor of 3.
tserver_overview
The tablet-peers corresponding to each tablet hosted on different YB-TServers form a Raft group and replicate data between each other. The system shown above comprises of 16 independent Raft groups. The details of this replication are covered in a previous section on replication.
Within each YB-TServer, there is a lot of cross-tablet intelligence built in to maximize resource efficiency. Below are just some of the ways the YB-TServer coordinates operations across tablets hosted by it:
Server-global block cache The block cache is shared across the different tablets in a given YB-TServer. This leads to highly efficient memory utilization in cases when one tablet is read more often than others. For example, one table may have a read-heavy usage pattern compared to others. The block cache will automatically favor blocks of this table as the block cache is global across all tablet-peers.
Throttled Compactions The compactions are throttled across tablets in a given YB-TServer to prevent compaction storms. This prevents the often dreaded high foreground latencies during a compaction storm.
Small/Large Compaction Queues Compactions are prioritized into large and small compactions with some prioritization to keep the system functional even in extreme IO patterns.
Server-global Memstore Limit Tracks and enforces a global size across the memstores for different tablets. This makes sense when there is a skew in the write rate across tablets. For example, the scenario when there are tablets belonging to multiple tables in a single YB-TServer and one of the tables gets a lot more writes than the other tables. The write heavy table is allowed to grow much larger than it could if there was a per-tablet memory limit, allowing good write efficiency.
Auto-Sizing of Block Cache/Memstore The block cache and memstores represent some of the larger memory-consuming components. Since these are global across all the tablet-peers, this makes memory management and sizing of these components across a variety of workloads very easy. In fact, based on the RAM available on the system, the YB-TServer automatically gives a certain percentage of the total available memory to the block cache, and another percentage to memstores.
Striping tablet load uniformly across data disks On multi-SSD machines, the data (SSTable) and WAL (RAFT write-ahead-log) for various tablets of tables are evenly distributed across the attached disks on a per-table basis. This ensures that each disk handles an even amount of load for each table.

















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









