



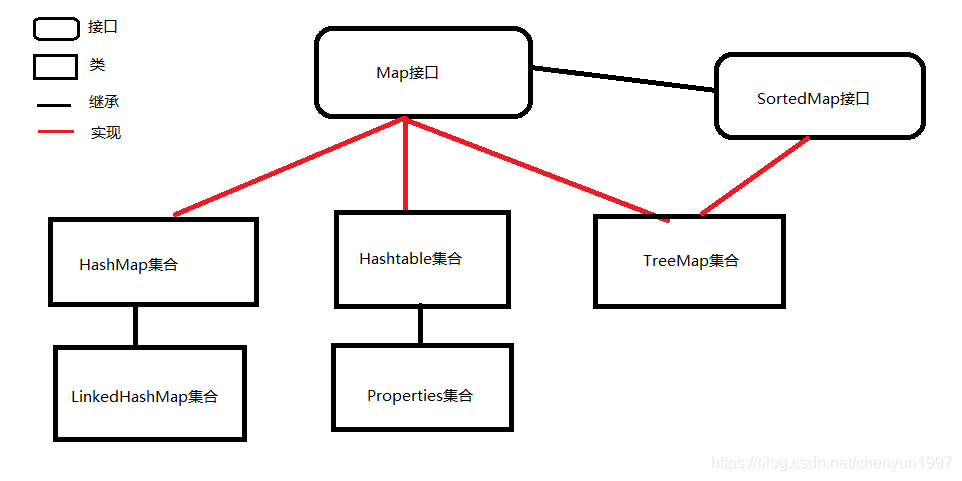
 本文详细解析了HashMap的存储结构及工作原理,包括其在JDK1.7和JDK1.8的不同实现,以及与HashTable的区别。探讨了HashMap如何通过计算Hash值减少冲突,并在特定条件下使用红黑树来提高查找效率。
本文详细解析了HashMap的存储结构及工作原理,包括其在JDK1.7和JDK1.8的不同实现,以及与HashTable的区别。探讨了HashMap如何通过计算Hash值减少冲突,并在特定条件下使用红黑树来提高查找效率。
特点:无序,键值对,键不能重复,值可以重复,无下标。允许存null;
存储结构:jdk1.7(包括)是采用数组+链表 jdk1.8(包括)是采用数组+链表+红黑树 键值对其存储开始默认大小是 16,默认加载因子是0.75f(就是说当存储内容已经超过了容量的75%就开始扩容),在一开始并不 会触发红黑树,只有当容量大于64和链表长度大于8的时候(可以理解为每个数组中存有链表,下图有 示意),才会触发红黑树存储。
HashMap:
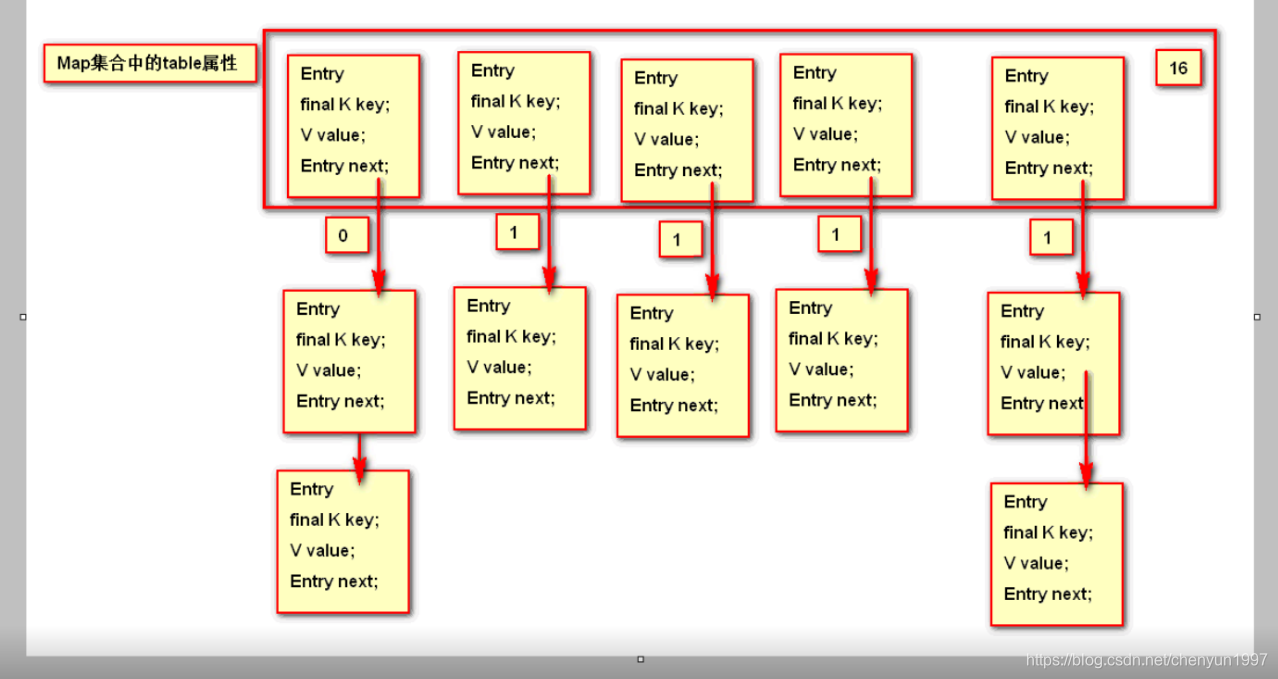
Map存储过程:Map实质是一个数组链表,Entry里面是个泛型,泛型的类型是在new对象的时候传入,key用final修饰表示不可修改,而value值是可以修改的,HashMap初始默认大小是16,相当于数组的开始默认大小是16,然后根据传入的键值,计算对应的的Hash值,再对Hash值的高16位和低16位进行异或运算,目的是为了减少Hash值冲突的概率(可谓下足了功夫),然后其结果再和(容量-1)(15(0001111)开始默认16)进行与运算(相当于取后四位,也就是说后四位值是小于16的,也就会存在这个数组中),虽然在绝大多数情况下hash值是不同的,但保留后四位时会出现相等的值出现,当出现值相同时,此元素就会纵向存储,相当于链式存储,若计算的后四位值相同时,在比较equals,若equals不同则添加,相同则不添加。在未出现红黑树时,是从头开始插入,后来就变成从尾部插入。采用取后四 位,可保证散列均匀。为什么与15(1111),31(11111)(数组默认长度减1)......进行与运算,可以保证最少移动过次数,同时保证了所有数都小于16,32........。
TreeMap:
存储方式:自平衡红黑二叉树 因为TreeSet类中的方法大多数都是使用TreeMap的方法,所以两个基本类似
可以根据自己的习惯,改写equals和hashcode 得到自己想要的排序 同时还要是实Comparable 接口才能比较引用数据类型
HashTable
结构:哈希表(数组+链表+(红黑树))
存储元素特点:无序,不可重复,不能为空值
HashMap和HashTable的区别
相同点:都采用哈希表存储,都是无序不可重复的,
不同点:HashMap键和值都可以存入null,而HashTable不可以
HashMap是线程不安全的集合,而HashTable是线程安全的集合
HashSet、HashMap、TreeSet和TreeMap的关系
HashSet实质就是对HashMap的key操作,HashSet中的值实质就是存在HashMap的键上,键对应的值为 null,所以Set值不可重复。
HashSet实质上是HashMap的一个实例

















 2954
2954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









