







一、Sharding-JDBC 不支持的查询类型
Sharding-JDBC 作为客户端分库分表方案,存在以下查询限制:
1.1 跨分片复杂查询
-
JOIN 操作限制:
-
不支持跨库 JOIN(除非使用绑定表或广播表)
-
不支持跨表 JOIN(非绑定表关系)
-
-
子查询限制:
-
子查询中包含分片表且分片键不一致时
-
相关子查询(Correlated Subquery)跨分片
-
-
聚合函数限制:
-
DISTINCT跨分片使用可能结果不准确 -
AVG函数需要特殊处理(先 SUM+COUNT 再计算) -
GROUP_CONCAT等特定数据库函数
-
1.2 分页查询限制
-
大偏移量分页问题:
SELECT * FROM orders LIMIT 100000, 10需要从所有分片获取前 100010 条数据再归并
-
跨分片 ORDER BY + LIMIT:
当排序字段非分片键时,结果可能不准确
1.3 其他限制
-
不支持存储过程/函数调用
-
不支持
SAVEPOINT相关操作 -
不支持
CASE WHEN等复杂表达式跨分片 -
不支持
UNION/UNION ALL跨分片查询
二、Sharding-JDBC 扩展机制与难点
2.1 扩展方式
-
自定义分片算法:
public class CustomShardingAlgorithm implements PreciseShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) { // 实现自定义分片逻辑 long value = shardingValue.getValue(); return "ds_" + (value % 2); } } -
自定义分布式ID生成器:
public class CustomIdGenerator implements KeyGenerator { @Override public Comparable<?> generateKey() { // 实现自定义ID生成逻辑 return SnowflakeIdGenerator.nextId(); } } -
自定义SQL改写:
public class CustomSQLRewriter implements SQLRewriteContextDecorator { @Override public void decorate(SQLRewriteContext context) { // 修改SQL执行计划 } }
2.2 扩展难点
-
SQL兼容性:
-
需要深入理解 SQL 解析引擎(ANTLR)
-
处理不同数据库方言的差异
-
-
分布式一致性:
-
扩展功能时需考虑数据一致性
-
跨分片事务处理复杂
-
-
性能优化:
-
避免全路由导致性能下降
-
流式归并的内存控制
-
-
事务管理:
-
整合分布式事务框架(如 Seata)
-
柔性事务状态恢复
-
三、跨分表范围查询实现
3.1 解决方案
-
绑定表策略:
shardingRule: bindingTables: - t_order, t_order_item -
Hint 强制路由:
try (HintManager hintManager = HintManager.getInstance()) { hintManager.addTableShardingValue("t_order", 1); hintManager.addTableShardingValue("t_order", 2); // 执行跨分片查询 } -
范围分片算法:
public class RangeShardingAlgorithm implements RangeShardingAlgorithm<Long> { @Override public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) { // 根据范围值返回目标分片 } }
3.2 跨天数据查询
-
按时间分片配置:
tables: log_table: actualDataNodes: ds$->{0..1}.log_$->{202301..202312} tableStrategy: standard: shardingColumn: create_time preciseAlgorithmClassName: com.example.MonthShardingAlgorithm -
多天数据合并:
// 自动路由到多个分片 List<Log> logs = logRepository.findByCreateTimeBetween( LocalDate.of(2023, 1, 1), LocalDate.of(2023, 1, 7) );
四、不停服扩容方案
4.1 扩容流程
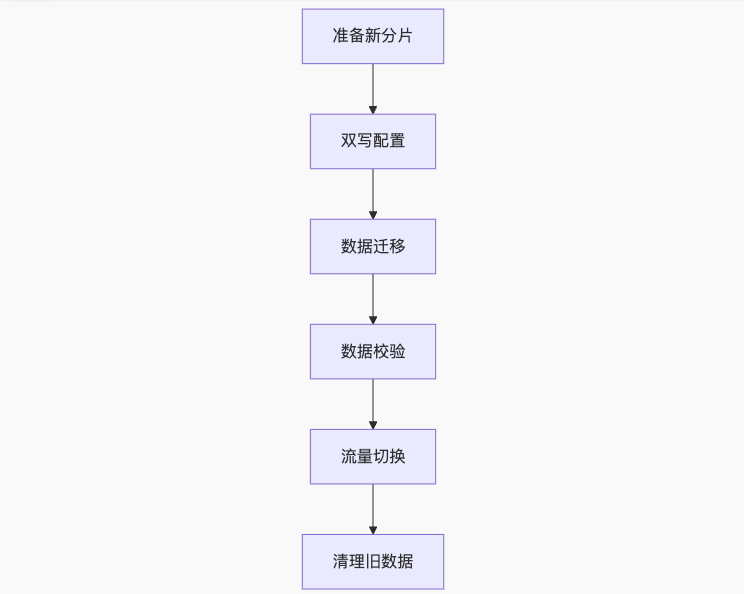
4.2 关键步骤
-
双写阶段:
-
同时写入新旧分片
-
使用消息队列保证双写一致性
-
-
数据迁移:
-
存量数据:使用 DataX 等工具迁移
-
增量数据:通过 Binlog 同步(如 Canal)
-
-
数据校验:
// 数据校验伪代码 List<Data> oldData = queryOldShard(shardKey); List<Data> newData = queryNewShard(shardKey); assert oldData.equals(newData); -
流量切换:
-
逐步切流(10% → 50% → 100%)
-
基于配置中心的动态规则更新
-
4.3 兜底方案
-
快速回滚:
-
配置版本化管理
-
一键回滚机制
-
-
数据补偿:
-
消息队列存储同步差异
-
定时补偿任务修复数据
-
-
熔断机制:
# 配置熔断规则 circuitBreaker: enable: true maxConsecutiveErrors: 5
五、多库多表数据聚合
5.1 归并引擎原理
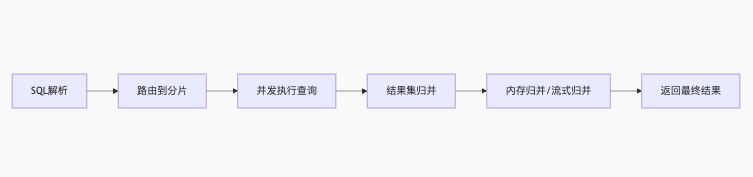
5.2 聚合类型
-
遍历归并:普通查询结果合并
-
排序归并:
ORDER BY查询 -
分组归并:
GROUP BY查询-
先在分片本地分组
-
再在内存中合并分组
-
-
聚合归并:
SUM/COUNT/MAX/MIN-
分片本地聚合
-
结果二次聚合
-
5.3 分组归并示例
SELECT user_id, SUM(amount)
FROM orders
GROUP BY user_id
执行流程:
-
各分片执行:
SELECT user_id, SUM(amount) FROM orders GROUP BY user_id -
归并引擎按
user_id合并结果 -
对相同
user_id的SUM(amount)再次求和
六、Sharding-JDBC 内部流程
6.1 核心执行流程
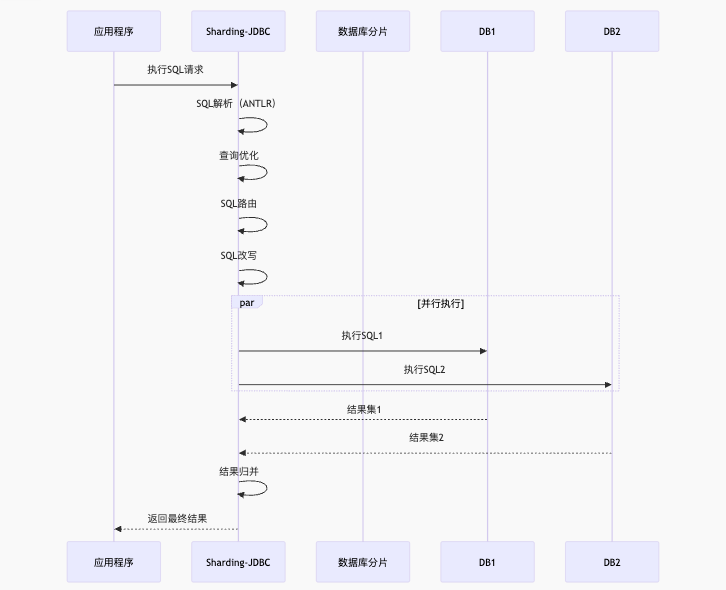
6.2 关键组件
-
解析引擎:ANTLR 实现的 SQL 解析
-
路由引擎:根据分片策略计算目标分片
-
改写引擎:逻辑 SQL → 真实 SQL
-
执行引擎:并发执行分片查询
-
归并引擎:合并分片结果集
七、Sharding-JDBC vs MyCAT
7.1 架构对比
| 维度 | Sharding-JDBC | MyCAT |
|---|---|---|
| 架构模式 | 客户端分片(无中心化) | 服务端代理(中心化) |
| 性能 | 更高(无网络跳转) | 有网络开销 |
| 部署 | 应用集成,无需额外部署 | 需独立中间件服务器 |
| 语言支持 | Java 生态 | 多语言(MySQL 协议兼容) |
| 功能 | 专注分库分表 | 支持读写分离、分库分表等 |
| 运维成本 | 低 | 需维护中间件集群 |
7.2 选择 Sharding-JDBC 的原因
-
性能优势:减少网络跳转,降低延迟
-
架构轻量:无单点故障,符合云原生趋势
-
灵活集成:与 Spring 生态无缝整合
-
扩展性强:易于定制分片策略
-
社区活跃:Apache 顶级项目,持续更新
八、分库分表规则设计实践
8.1 分片键选择原则
-
高基数:字段值分布均匀(如 user_id)
-
业务相关性:常作为查询条件的字段
-
低修改频率:避免分片键频繁更新
-
业务增长模式:
-
用户维度:按 user_id 分片
-
时间维度:按 create_time 分片
-
8.2 常用分片策略
-
哈希分片:
tableStrategy: standard: shardingColumn: user_id preciseAlgorithmClassName: HashModShardingAlgorithm -
范围分片:
// 范围分片算法实现 public Collection<String> doSharding(RangeShardingValue<Long> shardingValue) { Long lower = shardingValue.getValueRange().lowerEndpoint(); Long upper = shardingValue.getValueRange().upperEndpoint(); // 计算包含的分片范围 } -
复合分片:
complex: shardingColumns: user_id,order_id algorithmClassName: CompositeShardingAlgorithm
8.3 分片策略配置示例
sharding:
tables:
t_order:
actualDataNodes: ds${0..1}.t_order${0..15}
databaseStrategy:
standard:
shardingColumn: user_id
preciseAlgorithmClassName: HashDatabaseShardingAlgorithm
tableStrategy:
standard:
shardingColumn: order_id
preciseAlgorithmClassName: HashTableShardingAlgorithm
九、面试常见问题深度解析
9.1 如何解决跨分片分页问题?
-
业务优化:
-
使用连续分页(基于上次最大ID)
SELECT * FROM orders WHERE id > ? ORDER BY id LIMIT 10 -
-
内存归并:
-
设置最大归并行数限制
props: max.connections.size.per.query: 5 max.rows: 100000 -
9.2 如何实现全局唯一ID?
-
Snowflake 算法:
public class SnowflakeIdGenerator implements KeyGenerator { public Comparable<?> generateKey() { return Snowflake.generateId(); } } -
数据库分段分配:
-
使用单独的 ID 分配服务
-
9.3 如何保证数据一致性?
-
分布式事务:
-
集成 Seata 的 AT 模式
-
使用 XA 事务
-
-
最终一致性:
-
基于消息队列的补偿机制
-
对账系统定时校验
-
十、最佳实践总结
-
分片设计原则:
-
单分片不超过 5000 万行
-
预留 30% 容量用于扩容
-
-
性能优化:
props: sql.show: true # 开启SQL日志 executor.size: 20 # 并发执行线程数 -
监控指标:
-
分片查询延迟
-
归并结果集大小
-
分布式事务成功率
-
-
灾备方案:
-
同城双活部署
-
分片级数据备份
-

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









