



背景
由于架构变更,服务与服务之间职责发生变更,故而进行项目重构,而个人中心,是一个重要的入口,该接口开发后,需要进行压测,并结合线上的访问量,进而评估所需要的资源
问题
压测过程中,随着并发数的增加,CPU占用越来越高,但是TPS却依旧没有什么变化,对比之前老系统的压测结果,明显就有异常
因为下游系统并不是直接调用真实系统,而是mock,之前也有这种情况,mock占用资源导致TPS上不去的情况,所以让测试将下游系统也部署上去,真实调用下游看看压测结果,发现还是一样,没有改变
排查
1.通过日志排查
因为能直接接触到的,就是日志了,通过日志分析接口,发现大部分接口耗时都好几秒,然后看调用下游,调用redis前后的日志,发现调用的耗时其实算是正常的;去看其他日志的打印间隔,发现有两行日志之间的时间间隔比较大,定位到代码具体位置,发现这两行日志之间其实都没啥逻辑,对比该接口其他日志结果,发现耗时的地方并不相同,猜想是full gc导致的停顿
2.通过gc日志验证猜想
找到gc日志,查询到所有full gc的日志,发现确实full gc挺频繁的,但是光看gc日志,并不能得出什么信息
3.通过工具定位原因
使用jdk自带的监测工具jvisualvm.exe(jdk/bin目录中)
连接到远程应用,需要应用启动的时候增加JVM参数,暴露出端口,才可以通过下图红框来连接,这里通过本地连接做个样例
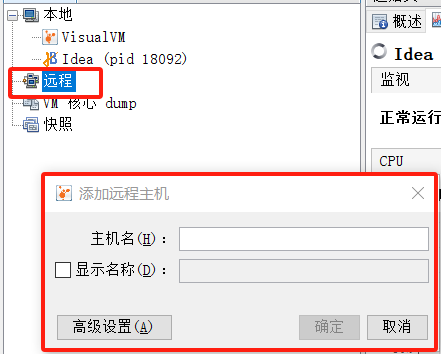
连接后,整个界面大概就是这样,首页的看板,可以实时反应出CPU,堆情况等信息
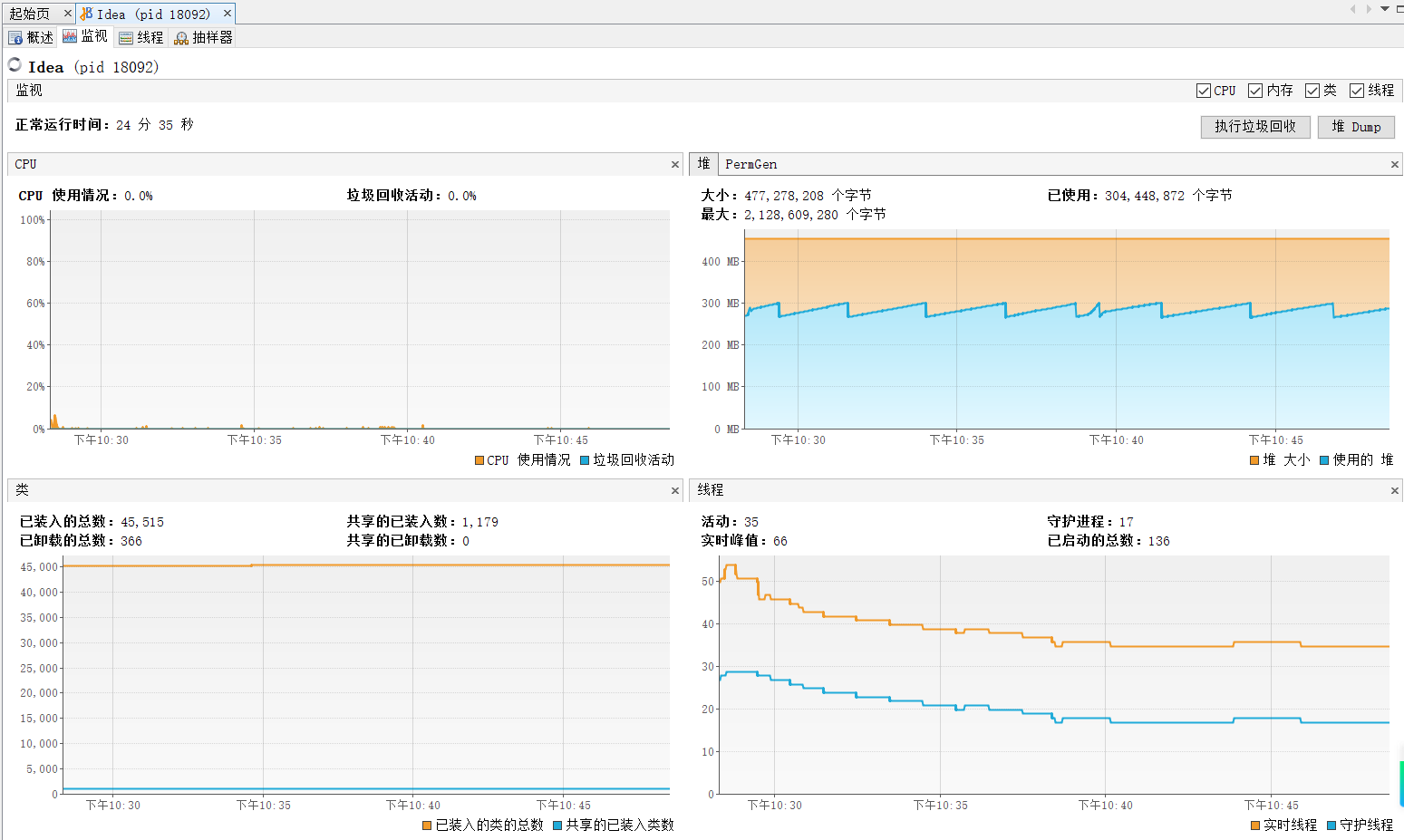
当时CPU的情况大概如下图红线(所有图标,都大概画了当时的情形,以红线为准)
压测的整个过程,CPU直接满载了,并且居高不下,一直到压测结束,才降下来
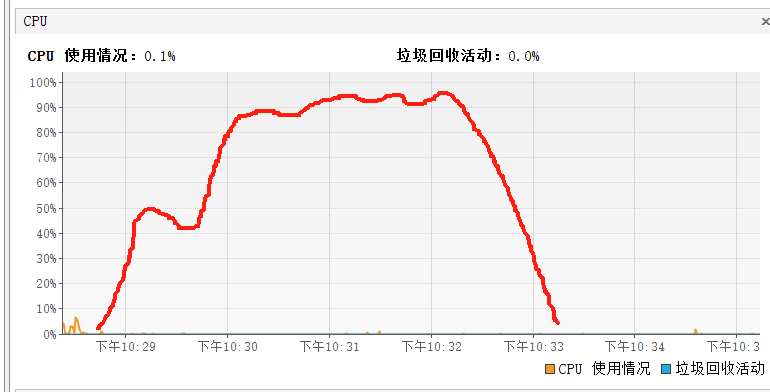
看堆的情况,发现gc频繁,但是gc的曲线如下图红线,每次触发gc后,都只回收一部分,另一部分回收不掉,堆内存持续增长。这样应用运行久了,肯定会内存溢出的。
初步猜测,应该是一直产生大对象,并且被长时间持有,释放不了
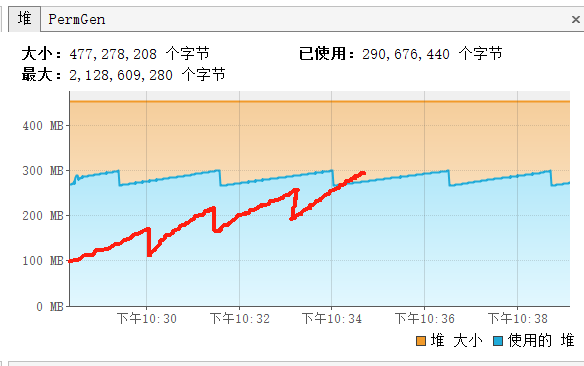
通过抽样器,大概反应出堆的情况,发现并没有持有大对象,没有异常的情况,就很奇怪,为什么一直堆一直回收不了,一直持续增长?
下图只是说明在哪里看,给个示例
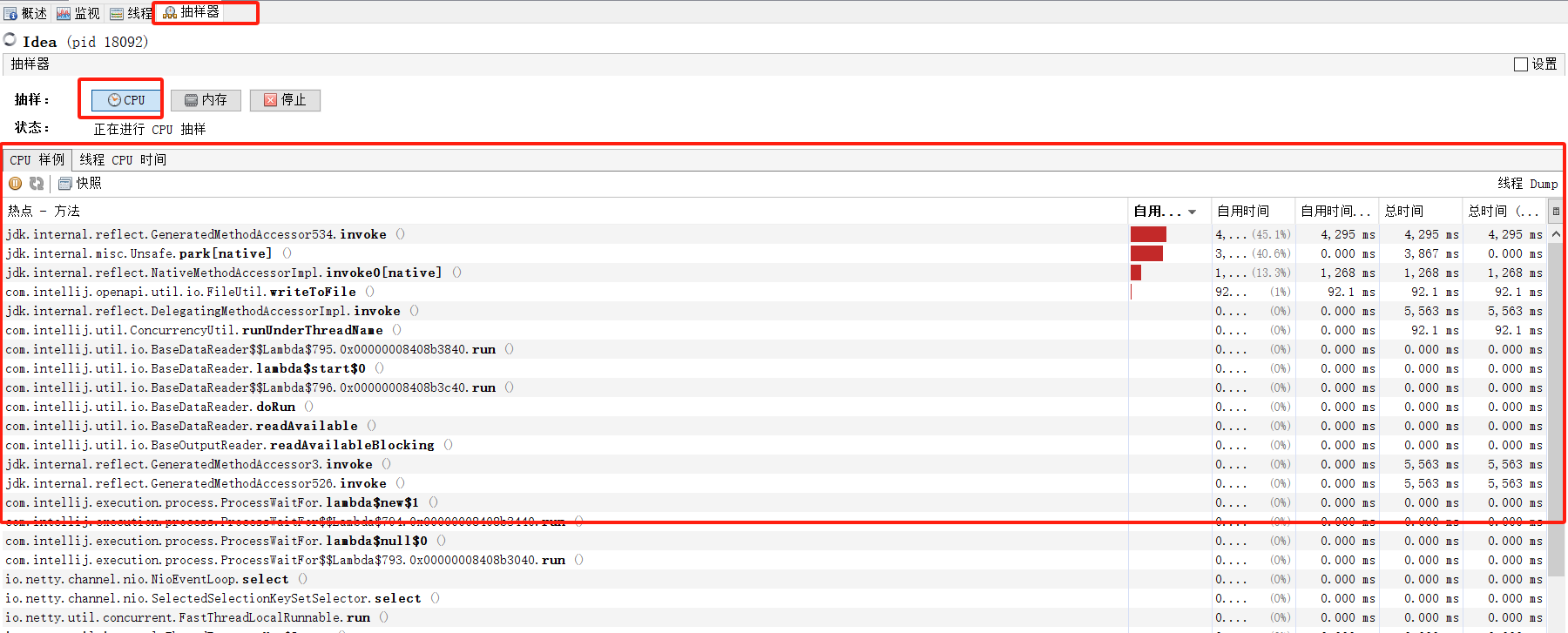
观察一下CPU的情况,发现有几个方法,一直占用了大量的CPU资源,而且都是日志打印的方法,这就很不对劲了
代码定位到具体的类,发现是做日志脱敏的日志扩展类
下图只是说明在哪里看,给个示例
所以到这里可以初步认定是日志脱敏消耗了大量的CPU资源导致的
4.验证结论
尝试着关掉日志脱敏,重新进行压测,发现压测结果正常,随着并发数的增加,TPS也增加了,CPU正常上升,不存在大量接口延时的情况
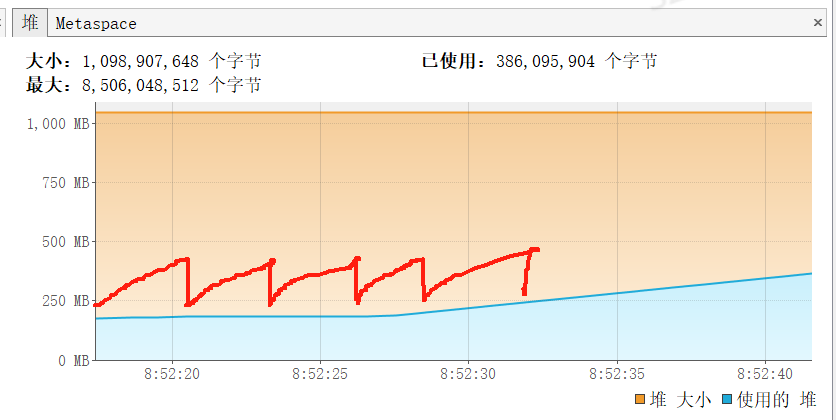
观察堆的情况,发现垃圾回收没有那么频繁了,并且触发垃圾回收后,也能回收掉所有垃圾,如下图红线,很平稳,不像之前堆内存一直在持续增长,所以这里验证了前一步的猜想,是日志脱敏导致的
5.解决方案
由于监管要求,日志脱敏并不能关闭,所以得另外找解决办法,既然是日志脱敏消耗大量的CPU资源,那只能对日志进行处理了
分析发现,因为内部框架对于请求/响应报文重复打印了好几次,并且有两个接口,是存在大报文的(由于工作量原因,某些配置表当期没安排迁移,只能通过老系统提供接口,获取整个配置表)
尝试着把这两个接口的配置都清空,开启日志脱敏的情况下,再进行压测,发现堆内存变化也是正常的
因为配置表暂时没人力可以做迁移,最后只能推动框架的负责人,优化日志,减少日志重复打印,避免日志脱敏占用大量CPU资源,但是隐患依旧是存在的,后续推动配置表的迁移
原因
日志脱敏,因为需要做正则匹配,但是大量的日志,以及都是大报文,会消耗特别多的CPU资源
系统是对C的,为了减少延迟,使用的是CMS垃圾回收器
CMS垃圾回收器,触发一次full gc,只会在初期暂停所有应用线程,标记没有被引用的对象,后面并发标记和并发回收,并不会暂停应用,这样是为了减少应用的延迟时间,但由于CPU资源被日志脱敏大量消耗了,导致垃圾回收线程抢占不到CPU资源,回收缓慢,旧垃圾没回收完,新垃圾又产生,堆内存就呈现出持续增长的情况

















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









