




基于PaddlePaddle和PaddleHub的口罩检测系统的落地实现
一、项目意义
2020春节,新型冠状病毒肆虐华夏大地,中华儿女举国防止疫情扩散蔓延,为防止疫情扩散,做好个人防护是每个公民的义务,特别是公共场合,火车站、飞机场和汽车站,人流量大的密集地区,做好人员口罩监控相当有必要。
二、项目目标
实现视频实时监测,并且做出简易GUI,打包出EXE文件,达到可以实用的目的
除此之外,做出具有照片检测功能的APP和服务器版,为后续优化提升打下基础
三、模型简介
1.pyramidbox_lite_mobile_mask
PyramidBox-Lite是基于2018年百度发表于计算机视觉顶级会议ECCV 2018的论文PyramidBox而研发的轻量级模型,模型基于主干网络FaceBoxes,对于光照、口罩遮挡、表情变化、尺度变化等常见问题具有很强的鲁棒性。该PaddleHub Module是针对于移动端优化过的模型,适合部署于移动端或者边缘检测等算力受限的设备上,并基于WIDER FACE数据集和百度自采人脸数据集进行训练,支持预测,可用于检测人脸是否佩戴口罩。
2.pyramidbox_lite_server_mask
PyramidBox-Lite是基于2018年百度发表于计算机视觉顶级会议ECCV 2018的论文PyramidBox而研发的轻量级模型,模型基于主干网络FaceBoxes,对于光照、口罩遮挡、表情变化、尺度变化等常见问题具有很强的鲁棒性。该PaddleHub Module基于WIDER FACE数据集和百度自采人脸数据集进行训练,支持预测,可用于检测人脸是否佩戴口罩。
3.模型效果展示

4. YOLO
APP使用了YOLO3模型
四、原理简介
本次重在实现该项目,对原理仅作简要介绍
1.PyramidBox
PyramidBox使用了与 S3FD完全相同的主干网络,包括基础卷积层和额外卷积层。基础卷积层即为 VGG16 中的 conv1_1 层到 pool5 层,额外卷积层将 VGG16 中的 fc6 层和 fc7 层转换为 conv_fc 层,又添加了更多的卷积层使网络变得更深。
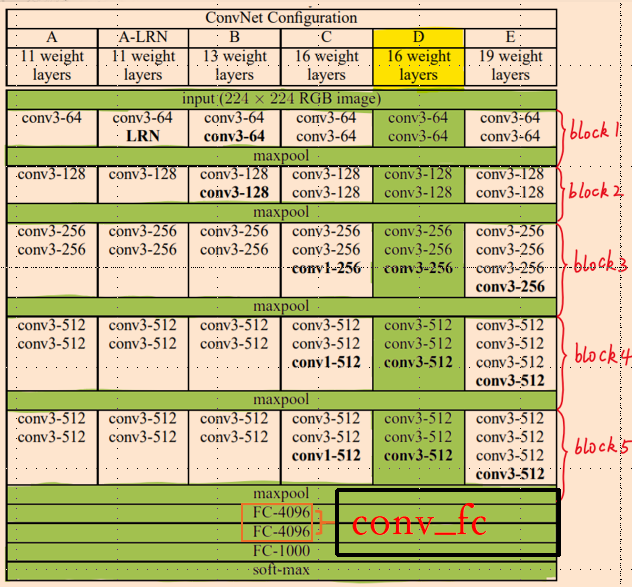
创新点:
-
提出了一种基于anchor的上下文辅助方法,称为pyramid anchors,用于监督学习小、模糊和部分遮挡人脸的上下文特征的监督信息
-
设计了低层特征金字塔网络(LFPN)来更好地融合文本特征和面部特征。同时,该方法可以在一次拍摄中很好地处理不同尺度的人脸
-
设计一个上下文敏感的预测模块,由混合网络结构和max-in-out层组成,从合并的特征中了解精确的位置和分类
-
提出了基于尺度感知的 Data-anchor-sampling,以改变训练样本的分布,将重点放在较小的人脸上
2. yolo3
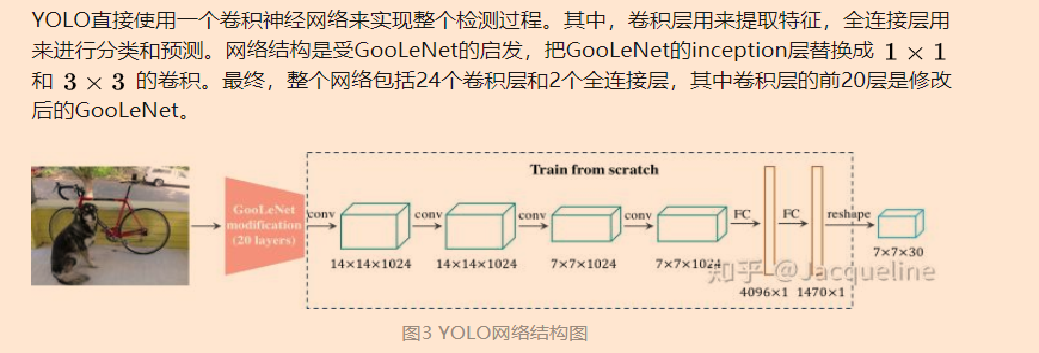
优点:
-
YOLO的结构非常简单,直接使用一个卷积神经网络就可以同时预测bounding box的位置和类别。
-
YOLO速度非常快,所以YOLO也可以实现视频的实时检测。
-
YOLO直接使用整幅图来进行检测,所以可以减少将背景检测为物体的错误。
五、项目实现
I.视频实时监控
1. 视频实时监控的实现
# -*- coding:utf-8 -*-
import paddlehub as hub
import cv2
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import json
import os
module = hub.Module(name="pyramidbox_lite_server_mask", version='1.1.0')
# opencv输出中文
def paint_chinese(im, chinese, position, fontsize, color_bgr):
# 图像从OpenCV格式转换成PIL格式
img_PIL = Image.fromarray(cv2.cvtColor(im, cv2.COLOR_BGR2RGB))
font = ImageFont.truetype(
'SourceHanSansSC-Medium.otf', fontsize, encoding="utf-8")
#color = (255,0,0) # 字体颜色
#position = (100,100)# 文字输出位置
color = color_bgr[::-1]
draw = ImageDraw.Draw(img_PIL)
# PIL图片上打印汉字 # 参数1:打印坐标,参数2:文本,参数3:字体颜色,参数4:字体
draw.text(position, chinese, font=font, fill=color)
img = cv2.cvtColor(np.asarray(img_PIL), cv2.COLOR_RGB2BGR) # PIL图片转cv2 图片
return img
result_path = './result'
if not os.path.exists(result_path):
os.mkdir(result_path)
name = "./result/1-mask_detection.mp4"
width = 1280
height = 720
fps = 30
fourcc = cv2.VideoWriter_fourcc(*'vp90')
writer = cv2.VideoWriter(name, fourcc, fps, (width, height))
maskIndex = 0
index = 0
data = []
capture = cv2.VideoCapture(0) # 打开摄像头
#capture = cv2.VideoCapture('./test_video.mp4') # 打开视频文件
while True:
frameData = {
}
ret, frame = capture.read() # frame即视频的一帧数据
if ret == False:
break
frame_copy = frame.copy()
input_dict = {
"data": [frame]}
results = module.face_detection(data=input_dict)
maskFrameDatas = []
for result in results:
label = result['data']['label']
confidence_origin = result['data']['confidence']
confidence = round(confidence_origin, 2)
confidence_desc = str(confidence)
top, right, bottom, left = int(result['data']['top']), int(
result['data']['right']), int(result['data']['bottom']), int(
result['data']['left'])
#将当前帧保存为图片
img_name = "avatar_%d.png" % (maskIndex)
path = "./result/" + img_name
image = frame[top - 10:bottom + 10, left - 10:right + 10]
cv2.imwrite(path, image, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
maskFrameData = {
}
maskFrameData['top'] = top
maskFrameData['right'] = right
maskFrameData['bottom'] = bottom
maskFrameData['left'] = left
maskFrameData['confidence'] = float(confidence_origin)
maskFrameData['label'] = label
maskFrameData['img'] = img_name
maskFrameDatas.append(maskFrameData)
maskIndex += 1
color = (0, 255, 0)
label_cn = "有口罩"
if label == 'NO MASK':
color = (0, 0, 255)
label_cn = "无口罩"
cv2.rectangle(frame_copy, (left, top), (right, bottom), color, 3)
cv2.putText(frame_copy, label, (left, top - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
#origin_point = (left, top - 36)
#frame_copy = paint_chinese(frame_copy, label_cn, origin_point, 24,
# color)
writer.write(frame_copy)
cv2.imshow('Mask Detection', frame_copy)
frameData['frame'] = index
# frameData['seconds'] = int(index/fps)
frameData['data'] = maskFrameDatas
data.append(frameData)
print(json.dumps(frameData))
index += 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
with open("./result/2-mask_detection.json", "w") as f:
json.dump(data, f)
writer.release()
cv2.destroyAllWindows()
2. 简易GUI的实现
首先选择了wxPython,并利用其提供的软件wxFormBuilder尝试制作GUI,但是网上对wxFormBuilder的介绍极少,最终只实现了部分功能:开启与结束。
使用该软件的作用也仅是获取GUI的代码
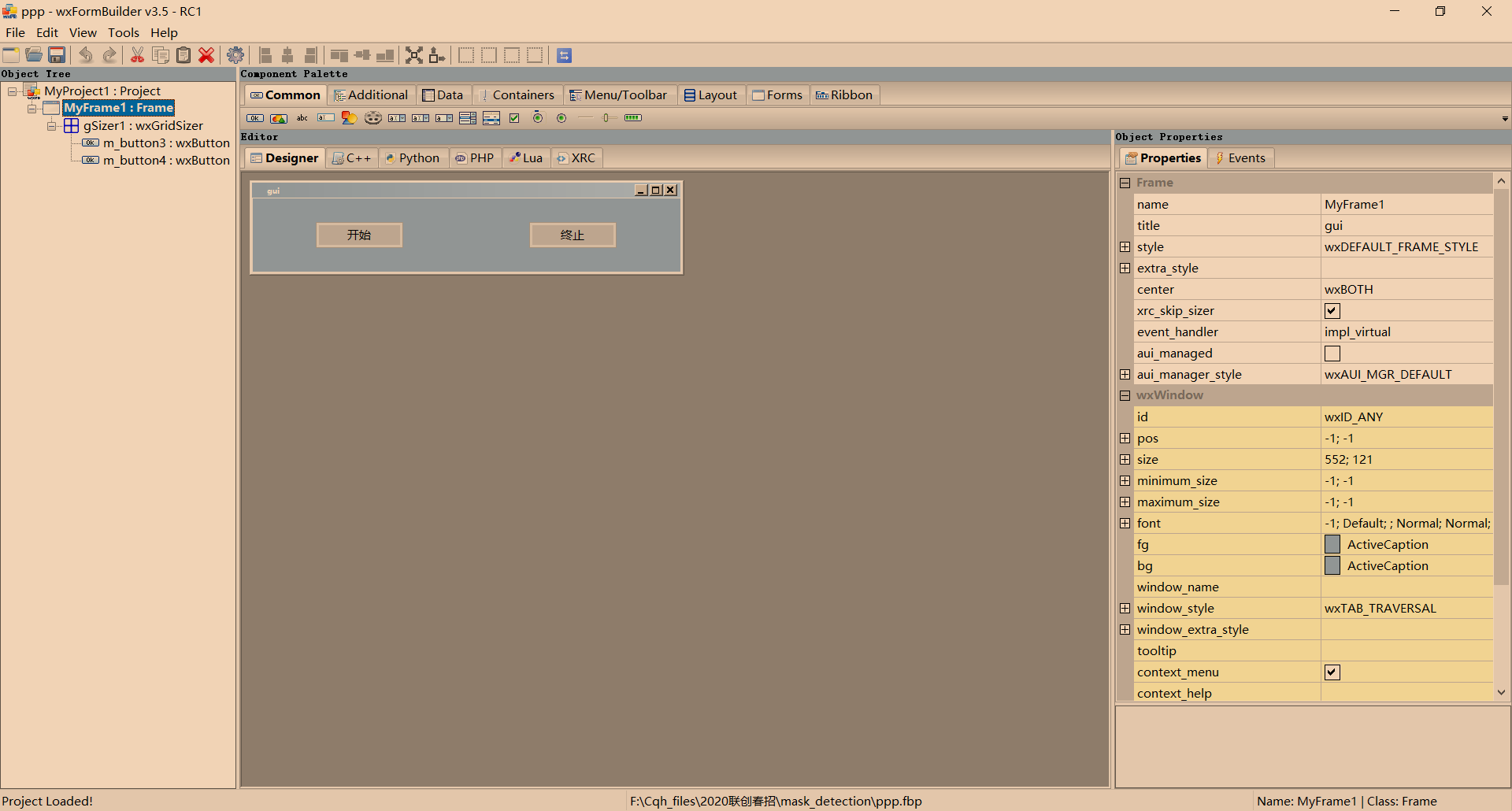
其对应代码如下
# -*- coding: utf-8 -*-  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1271
1271




 到【灌水乐园】发言
到【灌水乐园】发言







