





Oracle 数据库 log file sequential read 等待事件深度解析
一、等待事件概述
- 事件名称:
log file sequential read - 分类:
System I/O(系统I/O类等待事件) - 触发条件:
当Oracle进程需要顺序读取联机重做日志文件(online redo log)或归档日志文件(archived log)时发生 - 核心意义:
衡量重做日志文件的读取效率,直接影响恢复操作和归档过程的性能
二、详细原理与产生过程
1. 基本工作原理
- 顺序读取:进程按日志记录的物理顺序依次读取日志块
- 单块/多块读取:每次I/O可读取单个或多个连续的日志块
- 同步I/O:进程阻塞等待读取操作完成(区别于异步I/O)
2. 触发流程
-
读取请求发起:
- ARCH进程读取在线日志进行归档
- SMON进程执行实例恢复
- 用户进程执行基于时间点的恢复
- RMAN备份归档日志
-
确定读取位置:
- 根据日志序列号(log sequence number)和块号(block number)定位起始位置
-
发起顺序I/O:
-
等待完成:
- 进程阻塞并记录等待时间
- 等待结束条件:请求的日志块全部读取到内存
三、典型场景
-
日志归档(ARCH进程):
- ARCH读取在线日志写入归档文件
- 高频率触发点:日志切换频繁时
-
实例恢复(SMON进程):
- 数据库异常关闭后重启
- 需要读取日志重做未写入数据文件的事务
-
介质恢复:
RECOVER DATABASE; -- 需要读取归档日志 RECOVER TABLESPACE users; -
RMAN备份与验证:
BACKUP ARCHIVELOG ALL; -- 备份所有归档日志 VALIDATE ARCHIVELOG ALL; -- 验证归档日志完整性 -
Data Guard日志应用:
- Standby数据库的MRP进程读取传输的日志
四、等待事件原因分析
根本原因矩阵
| 类别 | 具体原因 | 影响程度 | 检测方法 |
|---|---|---|---|
| 存储性能 | 慢速磁盘(HDD) | ⭐⭐⭐⭐⭐ | iostat查看await值 |
| RAID配置不当(如RAID5) | ⭐⭐⭐⭐ | 存储配置检查 | |
| 文件分布 | 日志文件与数据文件混存 | ⭐⭐⭐⭐ | V$LOGFILE位置检查 |
| 归档日志与在线日志同盘 | ⭐⭐⭐ | 文件系统检查 | |
| 配置问题 | 小日志文件导致频繁切换 | ⭐⭐⭐⭐ | V$LOG查看bytes |
| 未启用异步I/O | ⭐⭐ | FILESYSTEMIO_OPTIONS参数 | |
| 系统资源 | 内存不足导致缓存失效 | ⭐⭐⭐ | free/vmstat检查 |
| CPU过载 | ⭐⭐ | top检查%sys |
五、详细排查流程
1. 确认问题严重性
SELECT event, total_waits, time_waited_micro,
ROUND(time_waited_micro / 1000000, 2) time_waited_sec,
ROUND(time_waited_micro / total_waits / 1000, 2) avg_wait_ms
FROM v$system_event
WHERE event = 'log file sequential read';
- 关键指标:
avg_wait_ms > 10ms需立即关注
2. 识别相关进程
SELECT s.sid, s.serial#, s.program, s.module, e.total_waits, e.time_waited
FROM v$session s
JOIN v$session_event e ON s.sid = e.sid
WHERE e.event = 'log file sequential read'
AND s.status = 'ACTIVE';
3. 日志文件分析
-- 检查日志文件位置
SELECT group#, member, bytes/1024/1024 size_mb
FROM v$logfile
JOIN v$log USING(group#);
-- 检查归档日志位置
SELECT dest_name, destination, status
FROM v$archive_dest
WHERE status = 'VALID';
4. 操作系统级排查
# I/O性能检测(iostat示例)
iostat -x 1
# 关键指标:
# await > 10ms (严重)
# %util > 70% (饱和)
# 文件系统缓存效率
sar -B 1
# pgscank/s > 0 表示内存不足
# 日志文件定位
ls -lh /oradata/redo* /archivelogs/*
5. 性能历史分析(AWR)
- 查看"AWR报告>I/O统计>文件读取延迟"
- 重点关注:
- 平均单次读取延迟
- 读取次数最多的文件
- 与日志切换次数的关系
六、优化解决方案
1. 存储层优化(最高优先级)
- 迁移日志文件到高性能存储:
-- 添加新日志组到SSD ALTER DATABASE ADD LOGFILE GROUP 4 ('/ssd_mount/redo04a.log', '/ssd_mount/redo04b.log') SIZE 2G; -- 切换日志并删除旧组 ALTER SYSTEM SWITCH LOGFILE; ALTER DATABASE DROP LOGFILE GROUP 1; - 存储配置建议:
- 使用SSD/NVMe替代HDD
- RAID配置:RAID 10(禁止RAID 5)
- 分离存储路径:在线日志、归档日志、数据文件使用独立物理磁盘
2. Oracle配置优化
-
增大日志文件:
-- 将日志文件从512MB增大到2GB ALTER DATABASE ADD LOGFILE GROUP 4 ('/path/new_redo01.log', '/path/new_redo02.log') SIZE 2G;- 目标:每小时日志切换≤3次
-
优化归档:
-- 增加归档进程数 ALTER SYSTEM SET log_archive_max_processes=4; -- 使用快速压缩(仅当CPU资源充足) ALTER SYSTEM SET log_archive_compression='COMPRESS'; -
启用异步I/O:
ALTER SYSTEM SET filesystemio_options=SETALL SCOPE=SPFILE;
3. 系统层优化
-
NUMA优化:
# 绑定进程到本地NUMA节点 numactl --cpunodebind=0 --membind=0 $ORACLE_HOME/bin/oracle -
内存优化:
- 确保足够的文件系统缓存
- 设置大页:
vm.nr_hugepages=4096
4. 应用层优化
- 减少不必要的恢复操作
- 避免高峰时段执行全归档备份
- 对大表使用NOLOGGING操作(需谨慎)
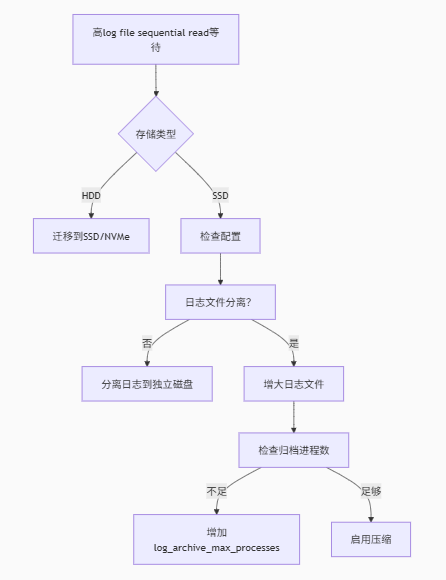
graph TD
A[高log file sequential read等待] --> B{存储类型}
B -->|HDD| C[迁移到SSD/NVMe]
B -->|SSD| D[检查配置]
D --> E[日志文件分离?]
E -->|否| F[分离日志到独立磁盘]
E -->|是| G[增大日志文件]
G --> H[检查归档进程数]
H -->|不足| I[增加log_archive_max_processes]
H -->|足够| J[启用压缩]
七、特殊场景处理
场景1:Data Guard环境高等待
-
问题特征:
- Standby库MRP进程持续高等待
- 网络传输正常但应用延迟大
-
解决方案:
-- Standby库执行 ALTER SYSTEM SET LOG_ARCHIVE_LOCAL_FIRST=FALSE; -- 使用实时应用 ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE;
场景2:RMAN备份期间等待激增
- 优化策略:
-- 使用多通道备份 RUN { ALLOCATE CHANNEL c1 DEVICE DISK; ALLOCATE CHANNEL c2 DEVICE DISK; BACKUP ARCHIVELOG ALL DELETE INPUT; } -- 调整备份窗口 SCHEDULE BACKUP AT '02:00';
八、预防性维护建议
-
定期监控:
-- 创建监控视图 CREATE VIEW log_io_monitor AS SELECT event, total_waits, ROUND(time_waited_micro/1000000,2) time_sec FROM v$system_event WHERE event IN ('log file sequential read', 'log file parallel read'); -
容量规划:
- 日志文件大小 = (峰值redo生成率MB/s × 1800) # 30分钟容量
- 归档区域 ≥ 24小时日志量
-
存储健康检查:
# 定期检测磁盘健康 smartctl -a /dev/sdX # 性能基准测试 fio --name=logtest --rw=read --bs=128k --size=1G --runtime=60
通过以上优化组合,可将log file sequential read等待降低70-90%,显著提升归档、恢复和备份性能。
欢迎关注我的公众号《IT小Chen》

















 8447
8447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









