





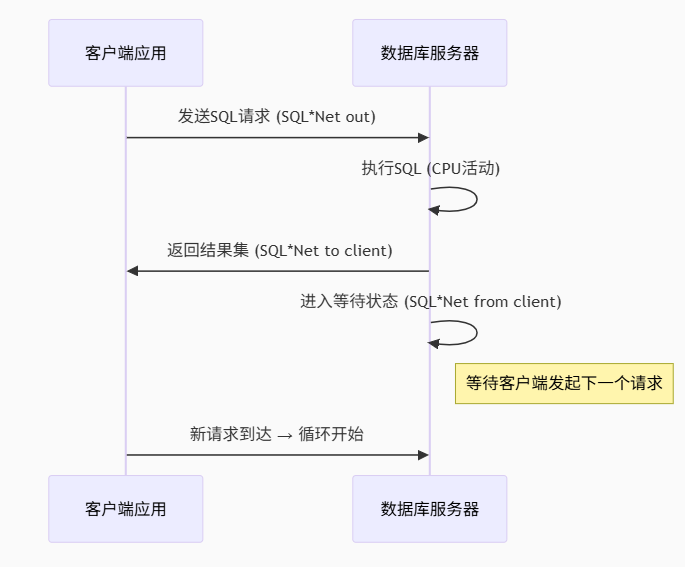
以下是针对 Oracle 数据库中 “SQL*Net message from client” 等待事件的深度解析,涵盖产生机制、触发场景、根因排查及优化方案:
⚙️ 一、等待事件本质
- 定义:
当 服务器进程完成工作后,等待客户端通过 SQL*Net 发送下一个请求(SQL 语句或数据)时产生。这是网络交互中的空闲等待,通常表示应用层处理时间。 - 关键特性:
- 非数据库性能指标:反映客户端响应时间
- 健康阈值:在 OLTP 系统中占比 60~80% 属正常,若 < 30% 需警惕数据库瓶颈
🔄 二、产生机制详解
🔥 三、典型场景与根本原因
📍 1. 健康场景(无需干预)
- 用户思考时间:用户在界面操作间隙(如填写表单)
- 应用逻辑处理:应用层处理数据后再发起新请求
- 批处理间隔:ETL 任务处理批次间的自然间隔
📍 2. 异常场景(需优化)
- 应用设计缺陷:
- 过度频繁提交(每行提交一次,而非批量提交)
- 未使用连接池导致物理连接暴涨
- 网络性能问题:
- 高延迟网络(跨国访问 RTT > 200ms)
- 带宽不足(结果集过大挤占带宽)
- 客户端资源瓶颈:
- 应用服务器 CPU 过载(无法及时处理结果集)
- 内存不足导致频繁 GC 停顿
🔍 四、深度排查流程
✅ 步骤1:确认等待事件占比
-- 检查总等待时间占比
SELECT event, total_waits, time_waited_ms,
ROUND(100 * time_waited_ms / SUM(time_waited_ms) OVER(), 2) pct
FROM v$system_event
WHERE event = 'SQL*Net message from client';
- 健康指标:
- OLTP 系统:60~80%
- 数据仓库:30~50%
- 异常信号:
- 占比 < 30% → 数据库存在性能瓶颈
- 平均等待时间 > 500ms → 网络/客户端问题
✅ 步骤2:定位高等待会话
-- 实时高等待会话查询
SELECT sid, username, program,
state, seconds_in_wait, wait_time
FROM v$session
WHERE event = 'SQL*Net message from client'
ORDER BY wait_time DESC;
- 关键字段:
PROGRAM:识别应用来源(如 “JDBC Thin Client”)SECONDS_IN_WAIT:持续等待时间(>300s 需警惕)
✅ 步骤3:网络性能诊断
-- 检查SQL*Net统计(发送/接收效率)
SELECT name, value
FROM v$sysstat
WHERE name LIKE '%SQL*Net%bytes%';
-- 计算网络传输效率
SELECT
(SELECT value FROM v$sysstat WHERE name = 'bytes sent via SQL*Net to client') sent_bytes,
(SELECT value FROM v$sysstat WHERE name = 'bytes received via SQL*Net from client') recv_bytes,
(sent_bytes/1024/1024) sent_mb,
(recv_bytes/1024/1024) recv_mb
FROM dual;
- 带宽验证命令(操作系统层):
# Linux 网络质量测试 iperf3 -c <DB_IP> -p 1521 -t 10 # 测试1G带宽下实际吞吐
✅ 步骤4:客户端性能分析
- 应用服务器检查:
# CPU负载 top -c | grep java # Java应用 # GC停顿时间(JVM应用) jstat -gcutil <pid> 1000 5 - 抓取应用SQL日志:
-- 开启10046跟踪(需SYS权限) EXEC DBMS_MONITOR.session_trace_enable(session_id=>123, serial_num=>456, waits=>TRUE);
🛠️ 五、根治解决方案
💡 1. 应用层优化
- 批处理改造:
// 错误:每行提交 for (Item item : list) { jdbc.execute("INSERT ..."); conn.commit(); // 每行提交 } // 优化:批量提交 int batchSize = 100; for (int i=0; i<list.size(); i++) { stmt.addBatch(); if ((i+1) % batchSize == 0) stmt.executeBatch(); } stmt.executeBatch(); // 最后一批 - 连接池调优:
# Tomcat JDBC配置 maxActive=50 # 最大连接数 maxIdle=20 # 最大空闲连接 validationQuery=SELECT 1 FROM DUAL
💡 2. 网络架构优化
-
压缩大数据集:
ALTER SYSTEM SET SQLNET.COMPRESSION = ON; -- 启用SQL*Net压缩 -
部署拓扑调整:
- 跨地域访问 → 通过 应用缓存层(Redis) 减少数据库交互
💡 3. 数据库配置调优
- 调整SQL*Net超时:
-- sqlnet.ora 配置 SQLNET.INBOUND_CONNECT_TIMEOUT = 60 -- 入站超时 SQLNET.SEND_TIMEOUT = 300 -- 发送超时 - 优化结果集传输:
-- 分页查询改造 SELECT * FROM ( SELECT t.*, ROWNUM rn FROM big_table t WHERE ROWNUM <= 1000 ) WHERE rn > 900;
💎 六、监控与预防体系
📊 健康指标基线
| 指标 | 健康范围 | 风险阈值 |
|---|---|---|
| SQL*Net from client 占比 | OLTP: 60~80% | <30% 或 >90% |
| 单次等待平均时间 | < 200ms | > 500ms |
| 网络往返延迟 (RTT) | < 50ms | > 150ms |
🔔 实时预警脚本
-- 每小时检查异常等待
SELECT SYSDATE,
SUM(CASE WHEN event='SQL*Net message from client' THEN time_waited ELSE 0 END) client_wait,
SUM(time_waited) total_wait,
ROUND(100 * client_wait / total_wait, 2) pct
FROM v$system_event
HAVING pct < 30 OR pct > 90; -- 触发告警
⚠️ 预防性措施
- 应用压力测试:
- 使用 Swingbench 模拟真实场景,记录 SQL*Net 等待基线
- 网络健康巡检:
# 月度网络质量报告 ping DB_IP -c 3600 | awk -F/ '/rtt/ {print $5}' > monthly_rtt.log - 客户端资源监控:
- 部署 APM 工具(如 AppDynamics)监控应用服务器性能
核心优化哲学:
该等待事件是 应用与数据库协作的效率镜子。优化优先级应为:
应用批处理设计 → 网络架构优化 → 数据库参数微调
当占比过低时,需反查数据库是否存在真实瓶颈(如DB CPU或latch free过高)
通过上述方法,可精准区分健康等待与异常阻塞,确保数据库资源高效服务于业务请求。
欢迎关注我的公众号《IT小Chen》

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









