




 本文详细介绍了消息队列的基本概念、优势与劣势,重点剖析了RabbitMQ的六种模式、消息确认机制及集群环境,对比了RabbitMQ与Kafka的特性。同时探讨了Kafka的高可用策略、数据持久化及存储策略。内容涵盖MQ产品选择、消费模式以及RocketMQ的特点。
本文详细介绍了消息队列的基本概念、优势与劣势,重点剖析了RabbitMQ的六种模式、消息确认机制及集群环境,对比了RabbitMQ与Kafka的特性。同时探讨了Kafka的高可用策略、数据持久化及存储策略。内容涵盖MQ产品选择、消费模式以及RocketMQ的特点。
目录
publish/Subscribe发布订阅模式 exchange交互机是广播模式:fanout
routing路由模式 exchange交互机是定向模式direct 。
topic模式,交互机模是通配符topic, 可以用* 或者 # 进行routing key 筛选发送订阅者
与 ActiveMQ、RabbitMQ、RocketMQ 不同的地方在于
一、MQ基本概念
消息队列
- 优势:
应用解耦、提升容错和可维护性
异步提速、提高用户体验和系统吞吐量
削峰填谷、处理高并发
- 劣势:
可用性降低(如何保证高可用)
复杂度提高
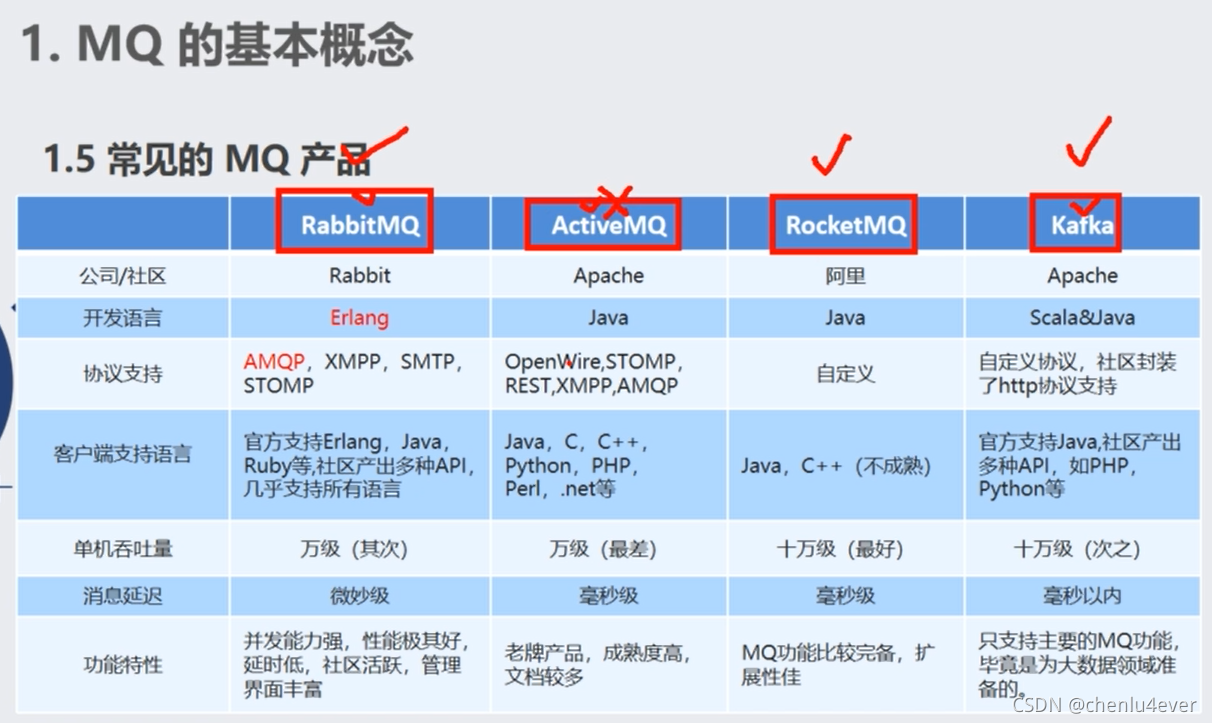
1.1常见MQ产品
RabbitMQ比价安全,所以金融行业常用。kafka多用于大数据。
1.2 消费模式 push/pull
- Push 模式
很难掌握消息推送的时机和速率,因为每个consumer的消费速率不同。
- Pull 模式
consumer可以根据自己的状况选择拉取消息的时机和速率,缺点在于如果服务端没有可供消费的消息,将导致consumer不断轮训,浪费资源。
二、RabbitMQ
Springboot 整合RabbitMq ,用心看完这一篇就够了_小目标青年的博客-优快云博客_springboot rabbitmq
RabbitMQ是一个实现了AMQP(Advanced Message Queuing Protocol)高级消息队列协议的消息队列服务,用Erlang语言。
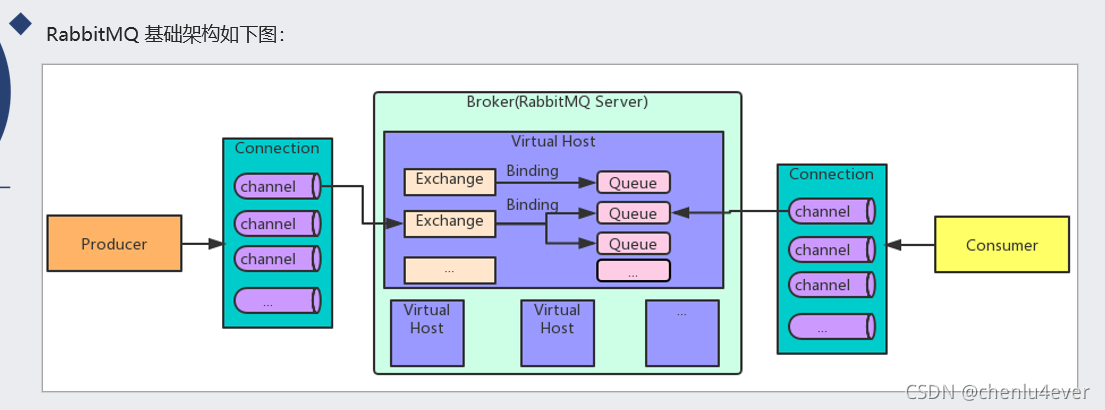
2.1消息处理两种模式
- 推模式/订阅模式/投递模式(也叫push模式)
消费者调用channel.basicConsume方法订阅队列后,由RabbitMQ主动将消息推送给订阅队列的消费者;
投递消息的个数还是会受到channel.basicQos的限制,推模式将消息提前推送给消费者,消费者必须设置一个缓冲区缓存这些消息。优点是消费者总是有一堆在内存中待处理的消息,所以当真正去消费消息时效率很高。缺点就是缓冲区可能会溢出。
- 拉模式/检索模式(也叫pull模式)
需要消费者调用channel.basicGet方法,主动从指定队列中拉取消息。
2.2 三种Exchange Type
-
Direct Exchange
直连型交换机,根据消息携带的Routing key (路由键)匹配 binding key将消息投递给对应队列。
-
Fanout Exchange
扇型交换机,这个交换机没有Routing key (路由键)概念, 交换机在接收到消息后,会直接转发到绑定到所有队列。
-
Topic Exchange
主题交换机,这个交换机其实跟直连交换机流程差不多,但是它的特点就是在它的路由键和绑定键之间是有规则的。
* (星号) 用来表示一个单词 (必须出现的)
# (井号) 用来表示任意数量(零个或多个)单词
通配的绑定键是跟队列进行绑定的,举个小例子
队列Q1 绑定键为 *.mq.* 队列Q2绑定键为 mq.#
如果一条消息携带的路由键为 A.mq.B,那么队列Q1将会收到;
如果一条消息携带的路由键为mq.AA.BB,那么队列Q2将会收到;
2.3 六种模式
-
Hello Wold 简单模式
-
work queue(队列)模式
-
publish/Subscribe发布订阅模式 exchange交互机是广播模式:fanout
-
routing路由模式 exchange交互机是定向模式direct 。
不同与发布订阅,会根据routing key筛选消息发送给订阅者 -
topic模式,交互机模是通配符topic, 可以用* 或者 # 进行routing key 筛选发送订阅者
-
RPC

2.4 消息确认机制
发布者需要开启监听模式!
server:
port: 8021
spring:
application:
name: rabbitmq-provider
rabbitmq:
host: 127.0.0.1
port: 5672
username: root
password: root
#虚拟host 可以不设置,使用server默认host
virtual-host: JCcccHost
#确认消息已发送到交换机(Exchange)
#publisher-confirms: true #之前版本
publisher-confirm-type: correlated
#确认消息已发送到队列(Queue)
publisher-returns: true

rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
System.out.println("ConfirmCallback: "+"相关数据:"+correlationData);
System.out.println("ConfirmCallback: "+"确认情况:"+ack);
System.out.println("ConfirmCallback: "+"原因:"+cause);
}
});
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("ReturnCallback: "+"消息:"+message);
System.out.println("ReturnCallback: "+"回应码:"+replyCode);
System.out.println("ReturnCallback: "+"回应信息:"+replyText);
System.out.println("ReturnCallback: "+"交换机:"+exchange);
System.out.println("ReturnCallback: "+"路由键:"+routingKey);
}
});
消费者接收到消息的消息确认机制
自动确认、手动确认
RabbitMQ默认是自动确认的
消费者收到消息后,手动调用basic.ack/basic.nack/basic.reject后,RabbitMQ收到这些消息后,才认为本次投递成功。
- basic.ack用于肯定确认
- basic.nack用于否定确认(注意:这是AMQP 0-9-1的RabbitMQ扩展)
channel.basicNack(deliveryTag, false, true);
第一个参数依然是当前消息到的数据的唯一id;
第二个参数是指是否针对多条消息;如果是true,也就是说一次性针对当前通道的消息的tagID小于当前这条消息的,都拒绝确认。
第三个参数是指是否重新入列,也就是指不确认的消息是否重新丢回到队列里面去。
- basic.reject用于否定确认,但与basic.nack相比有一个限制:一次只能拒绝单条消息
channel.basicReject(deliveryTag, true);
reject第二个参数true/false 判断消息是否要重入队列,重入有风险,可能会造成消息积压。
2.5 集群环境
-
普通模式:
主备结构,保证服务可用,但是无法达到高可用
slave复制master节点,除了队列数据,队列数据只在master上。slave需要连接到master上进行转发。
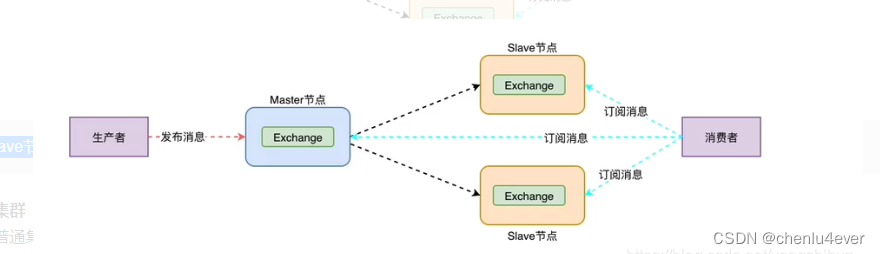
-
镜像集群:
基于普通集群实现队列的集群主从,消息会在集群中同步(至少三个节点)
四、Rocket MQ
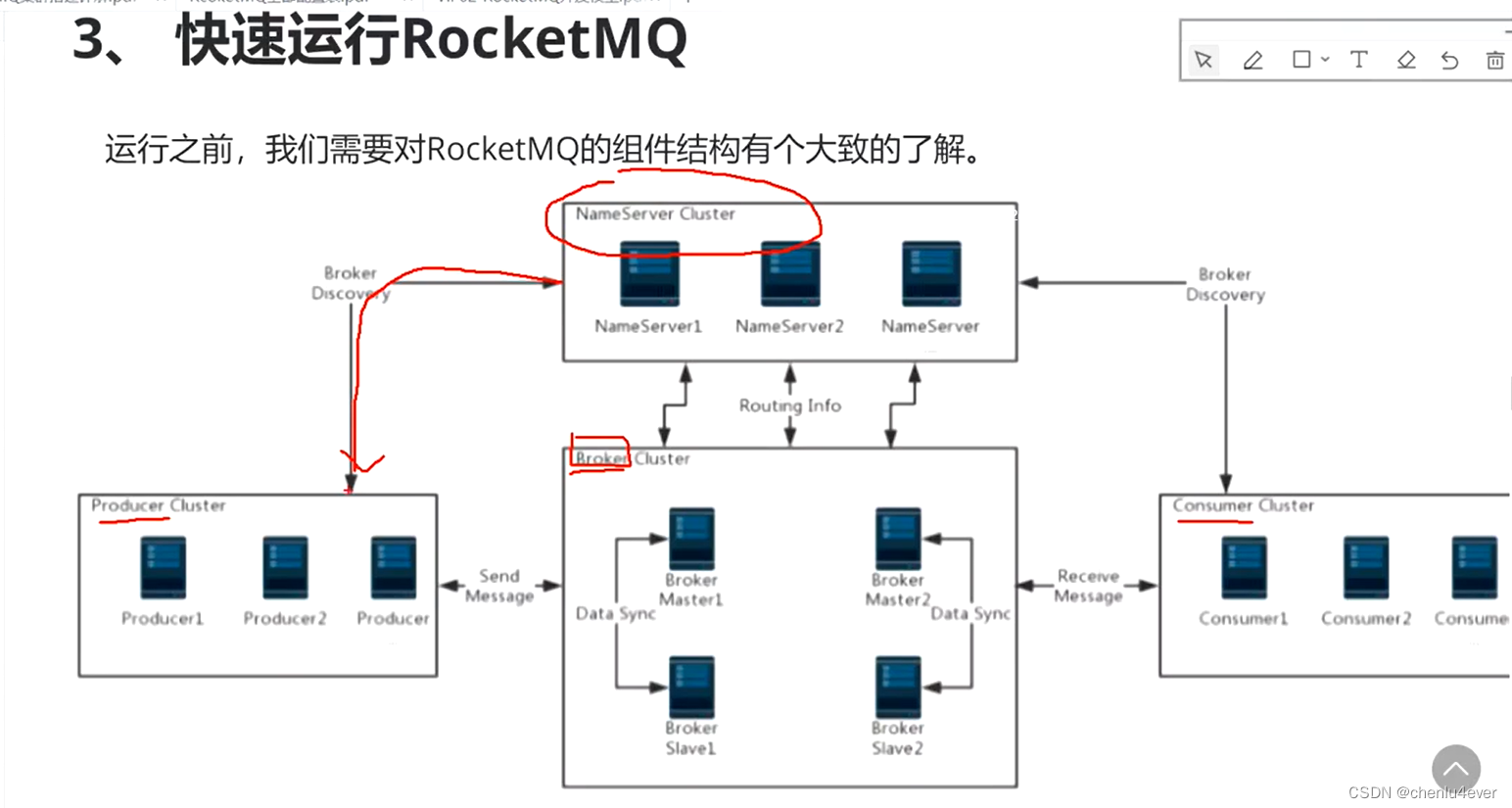
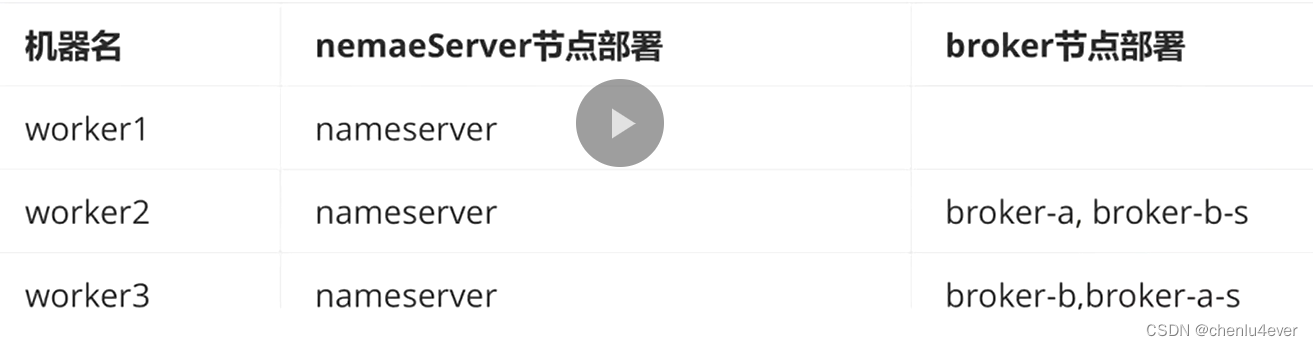
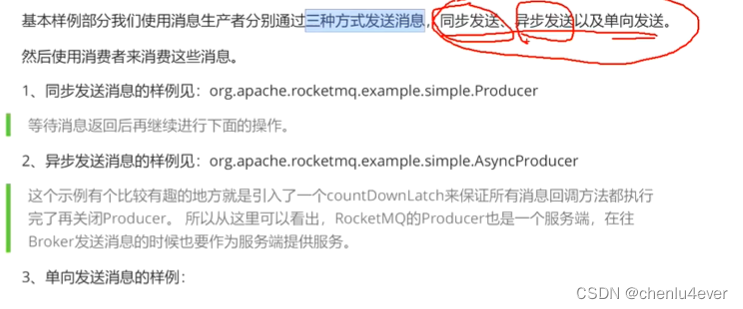
全局有序,这个
局部有序,
无效
一个系统一个topic,不通业务通过tag过滤
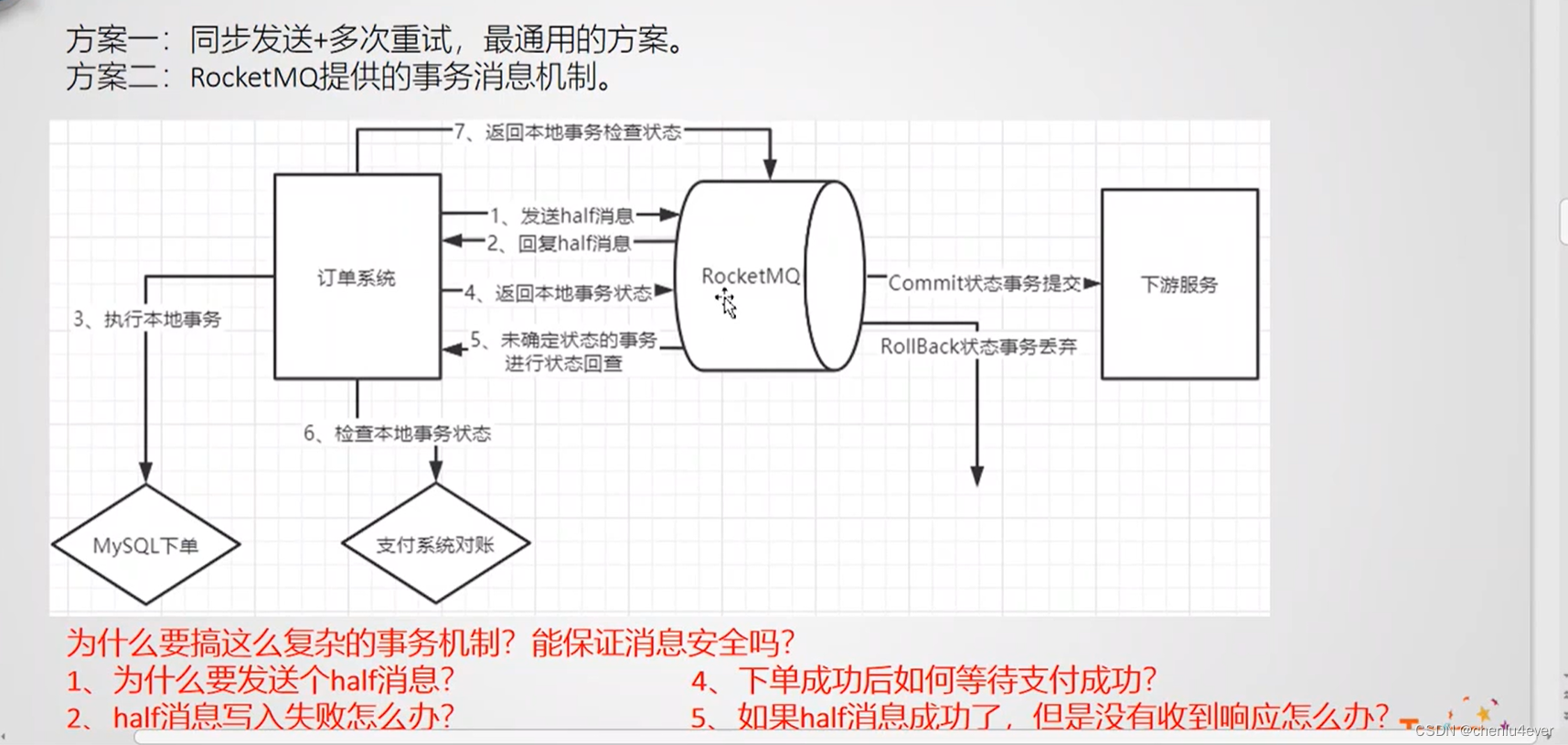
相较于Zookeeep的的ZAP协议选举,不会产生脑裂
每个节点都有:leader、follower、candidate三种状态
选举时,每个节点会带termID,查过半数人认为termId最大的人为Leader.
五、kafka
5.1 什么是kafka
实时数据处理系统,可以横向扩展,并高可靠
Kafka是用scala语言编写。是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统。
5.2 需求场景
基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,
5.3 架构与工作原理
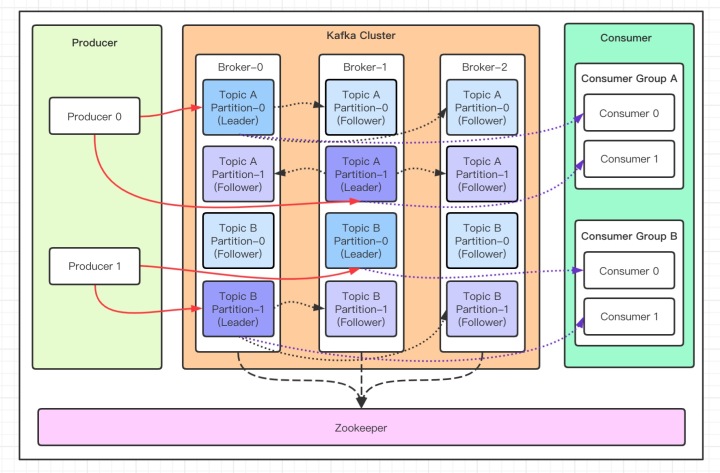
- Broker:Broker 是 kafka 一个实例,每个服务器上有一个或多个 kafka 的实例,简单的理解就是一台 kafka 服务器,
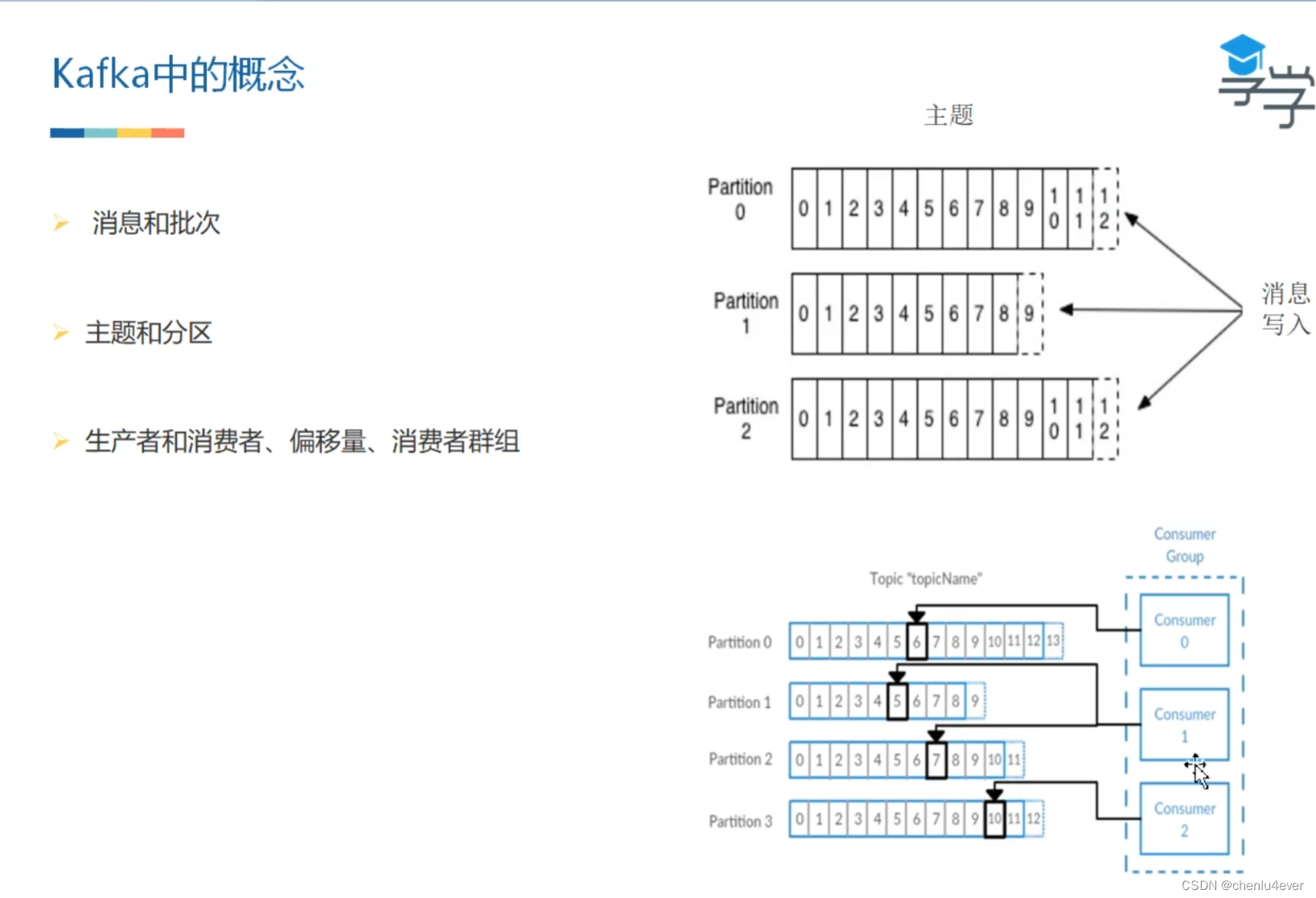
kafka cluster表示集群的意思 - Topic:消息的主题,可以理解为消息队列,kafka的数据就保存在topic。在每个 broker 上都可以创建多个 topic 。
- Partition:Topic的分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。同一个 topic 在不同的分区的数据是不重复的,partition 的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎,主分区(Leader)会将数据同步到从分区(Follower)。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为 Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在 kafka 的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka 集群依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性。
与 ActiveMQ、RabbitMQ、RocketMQ 不同的地方在于
它有一个分区Partition的概念。这是 kafka 与其他的消息系统最大的不同!
如果你创建的topic有5个分区,当你一次性向 kafka 中推 1000 条数据时,这 1000 条数据默认会分配到 5 个分区中,其中每个分区存储 200 条数据。
消费者从不同的分区拉取数据,假如你启动 5 个线程同时拉取数据,每个线程拉取一个分区,消费速度会非常非常快!
5.4 发送数据
kafka中有以下几个原则:
- 1、数据在写入的时候可以指定需要写入的分区,如果有指定,则写入对应的分区
- 2、如果没有指定分区,但是设置了数据的key,则会根据key的值hash出一个分区
- 3、如果既没指定分区,又没有设置key,则会轮询选出一个分区

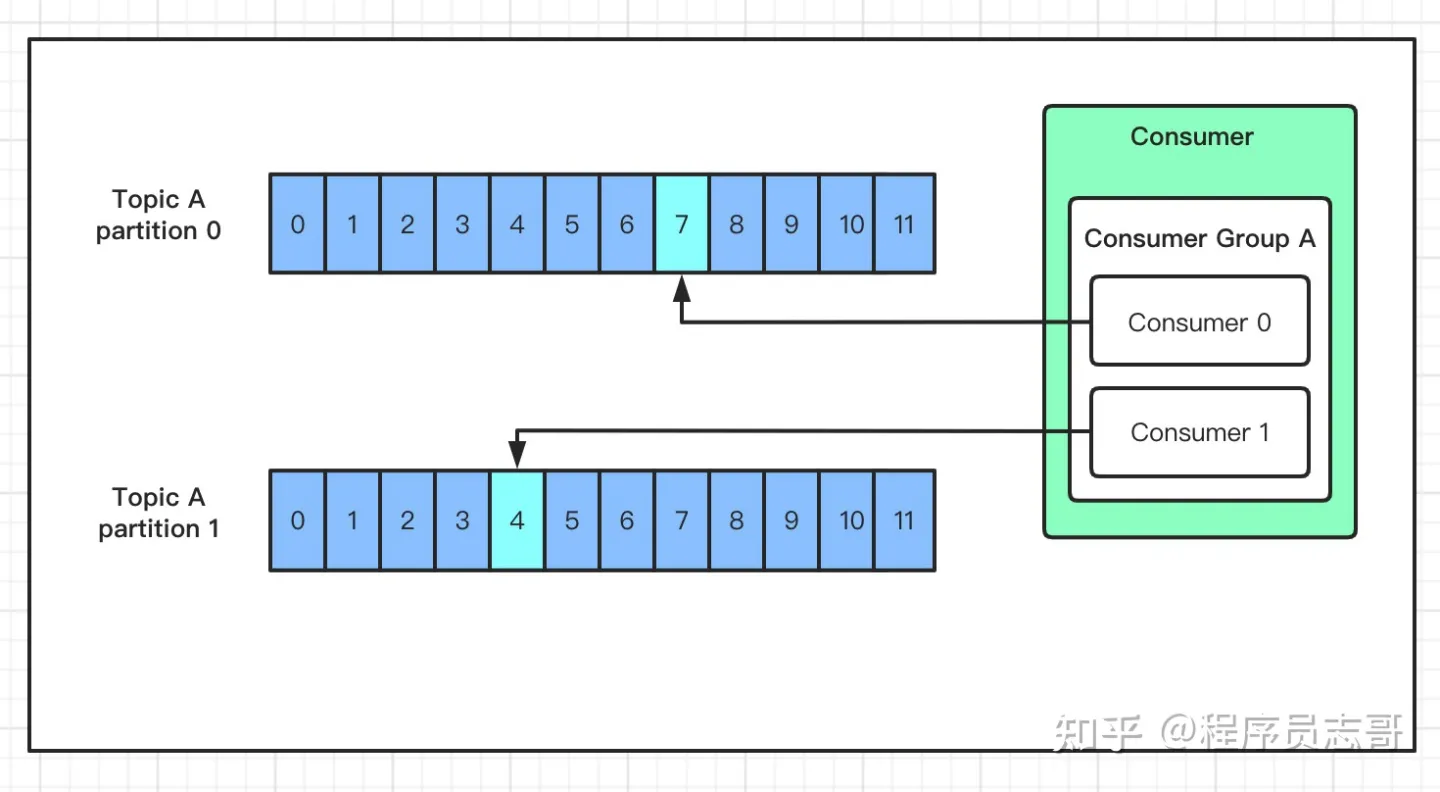
5.5 消费数据
kafka采取的是发布订阅模式,消费者主动去Leader分区拉去数据。
同一个消费组者的消费者可以消费同一个 topic 下不同分区的数据,同一个分区只会被一个消费组内的某个消费者所消费,防止出现重复消费的问题!
5.6 kafka如何保证高可用
通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
- 0 不确保消息发送是否成功。安全性最低但是效率最高。
- 1 代表producer往集群发送数据只要leader应答就可以发送下一条。
- all 代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,安全性最高,但是效率最低。
数据持久化,文件保存
- 文件夹:.index索引文件、.log message文件

-
如何通过offset查出message
offset=368776的message,需要通过下面2个步骤查找。
第一步查找segment file
其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件 00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件列表,就可以快速定位到具体文件。当offset=368776时定位到00000000000000368769.index|log
第二步通过segment file查找message通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和 00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到 offset=368776为止。
-
存储策略 旧数据什么时候删除
基于时间:文件7天内未被更新被删除
基于大小:

















 5906
5906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









