 SPSS Modeler空间数据分析
SPSS Modeler空间数据分析





 IBM SPSS Modeler 17.0新增空间数据分析功能,包括地图文件读取与可视化、空间-时间预测及关联规则算法。可用于预测犯罪高发区、疾病传播等。
IBM SPSS Modeler 17.0新增空间数据分析功能,包括地图文件读取与可视化、空间-时间预测及关联规则算法。可用于预测犯罪高发区、疾病传播等。
IBM SPSS Modeler作为大数据分析应用层数据挖掘平台,受到业界的广泛好评与喜爱,这也依赖于产品本身技术的不断的发展与完善,IBM SPSS的研发团队在中国历史文化名城—西安,拥有超过300多名技术研发人员,致立于产品新技术的引入与研发,为产品本身提供源源不断发展动力,更好地为我们的客户服务。在我们优秀团队的带领下,我们的产品每年都有新的版本、新的技术发布,那么接下来,我给大家介绍下,SPSS Modeler最新版本 17.0新增空间数据分析的相关功能及Demo演示。
SPSS Modeler空间数据分析功能介绍
I.引入地图文件及地图可视化展现

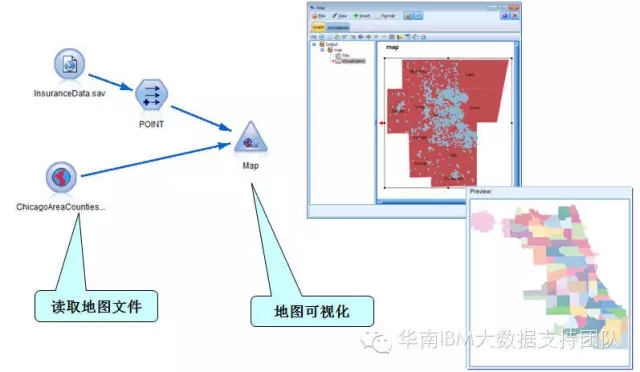
在SPSS Modeler平台上,我们新增了读取地理位置信息的源节点,以及地图展现的输出节点;
连接方式:我们有两种方式可以连接地图文件,分别是
1、通过形状文件 (.shp) 进行导入;
2、通过连接到包含地图文件的分层文件系统所在的 ESRI 服务器进行导入。
功能:读取地图文件,与其它数据信息融合在一起,以直观的地图的方式展现最终的分析结果;
应用场景:需要将分析结果与地图结合起来的场景,比如购物中心的客流分布、交通状态、运输物流等。
II.新增算法:空间-时间预测(Spatio-temporal prediction)

功能:将地理位置信息和时间都作为分析场景的输入影响因素,预测未来具体时间点以及具体位置发生某类事件的可能性。
计算逻辑:在回归的基础,添加了空间协方差矩阵和时间序列来处理时间和空间信息;
应用场景:可用于预测未来某一时间某些地点可能发生的事件,比如疾病多发区、犯罪多发地的预测;
大数据支持:可以通过Analytic Server进行Map-Reduce计算,提升计算效率。
III.新增算法:关联规则

功能:可将空间地理信息作为分析因素,分析出事件发生的模式或规则;
应用场景:犯罪模式分析、流行病/传染病监控等;
大数据支持:可以通过Analytic Server进行Map-Reduce计算,提升计算效率。

SPSS Modeler空间数据分析Demo演示
介绍了以上功能后,我们通过Demo来了解SPSS Modeler如何应用空间数据,实现对犯罪事件发生类型的预测。
I.分析场景:
我们有美国芝加哥州包括的10个乡镇以往发生犯罪事件的记录,我们要分析的目标就是根据以往的犯罪事件发生的情况,研究在哪些区域可能是犯罪事件高发区域,并通过地图的方式展现分析结果。
II.分析思路:
结合犯罪事件发生的地理位置,通过关联规则分析各类犯罪事件发生的规则。
III.分析步骤:
整个分析数据流如下图,分为3个步骤,分别是数据整理、建模和地图展现。
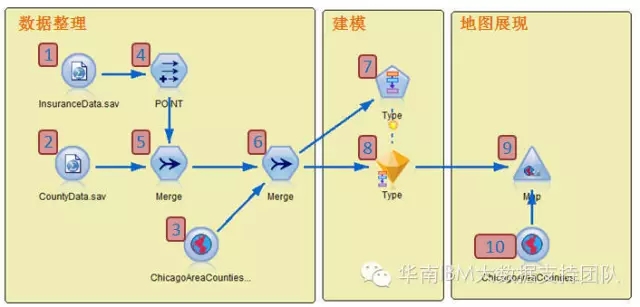
接下来按流程图中的具体编号具体介绍实现过程。
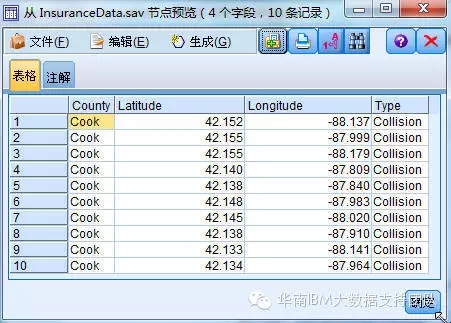
1.连接犯罪事件数据源文件InsuranceData.sav
文件记录了历史发生犯罪事件的地理位置(经、纬度)以及发生的犯罪事件类型,包括以下内容:
- 乡镇名称(Country)
- 纬度(Latitude)
- 经度(Longitude)
- 犯罪事件类型(Type),包括Collision、Theft、Vandalism、Uninsured。
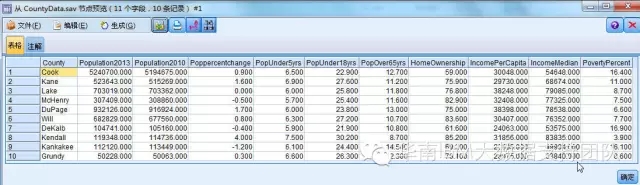
2.连接各个country(乡镇)的属性信息文件CountyData.sav
文件收集了各个乡镇人口、收入等相关信息,包括以下内容:
- 乡镇名称(Country)
- 2013年人口数量(Population2013)
- 2010年人口数量(Population2010)
- 人口增长率(Poppercentchange)
- 小于5岁的人口占比(Popunder5yrs)
- 小于18岁的人口占比(Popunder18yrs)
- 大于65岁的人口占比(PopOver65yrs)
- 拥有房产人员占比(HomeOwership)
- 人均收入(IncomePerCapita)
- 收入中位数(IncomeMedian)
- 贫困率(PovertyPercent)
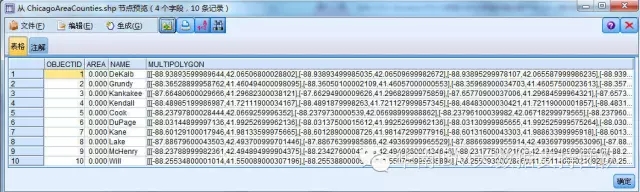
3.连接芝加哥地图文件ChicagoAreaCounties.shp
文件包括各个乡镇(Country)的地理位置信息,包括以下内容:
1、乡镇ID号(ObjectieID)
2、乡镇名称(Name)
3、图层信息(MultiPolygon)
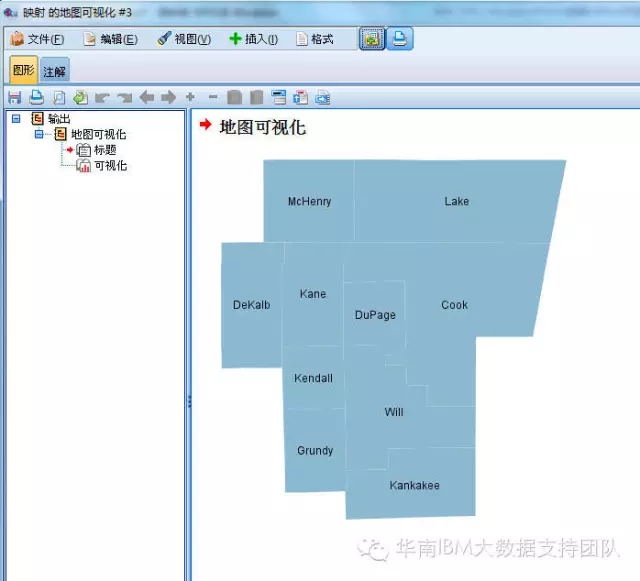
可以用SPSS Modeler的地图展现如下:
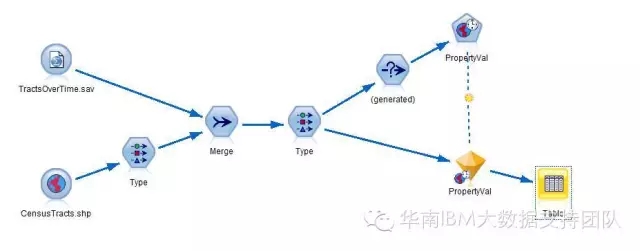
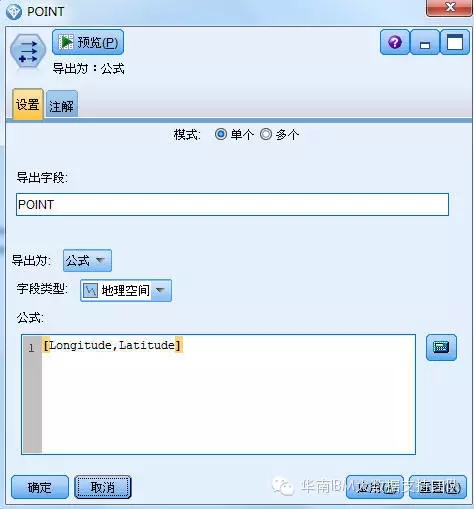
4.生成新的地理空间字段POINT
对记录犯罪事件发生的InsuranceData.sav文件中的经度和纬度两列数据(Latitude、Longitude)合并到地理空间上,字段类型为地理空间,节点命名为POINT,为下面与地图数据的合并做准备。
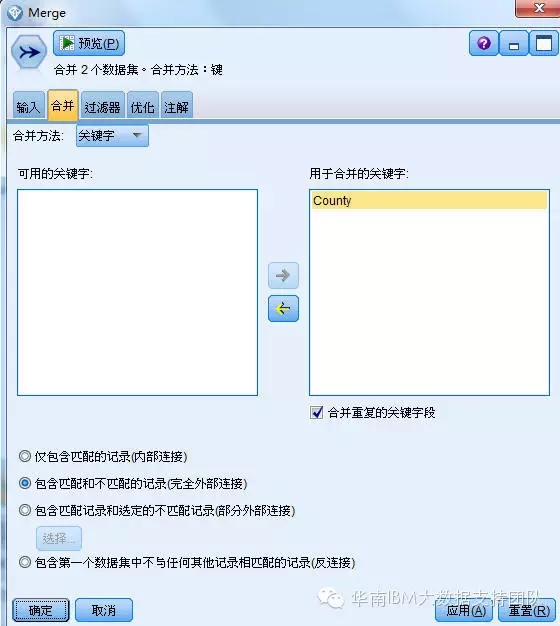
5.将犯罪事件记录数据与各乡镇属性信息合并
即对CountyData.sav和InsuranceData.sav两份数据按关键字Country合并。
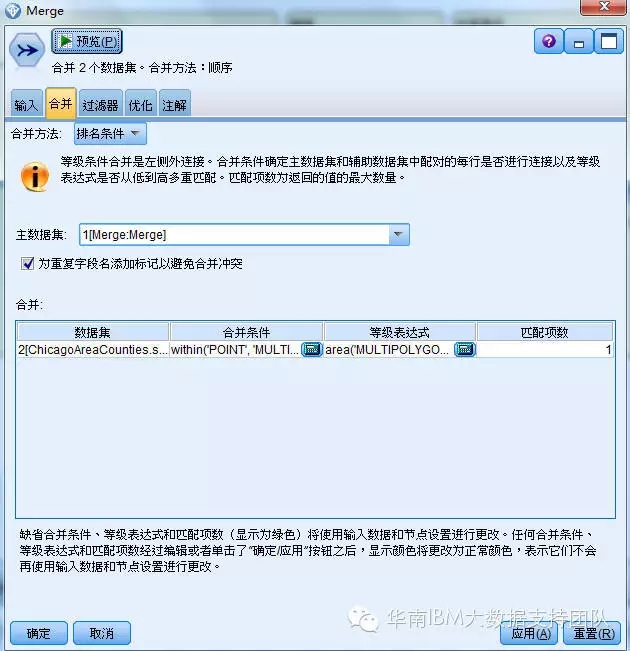
6.将上面整理好的数据与芝加哥地图文件再做合并
至此,我们将数据整理完成,合并后的数据内容包括:
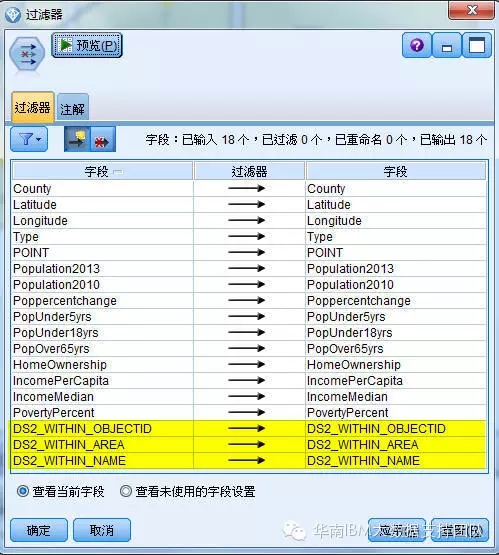
其中以DS2开头的三列数据,表示事件发生的位置对应地图上的对象、区域和名称。
7.选择关联规则算法建模
我们使用关联规则算法,生成犯罪事件发生的规则模型,只需要将犯罪类型(Type)设置为预测,并选择影响因素作为条件,然后点击运行则会自动生成业务规则模型。
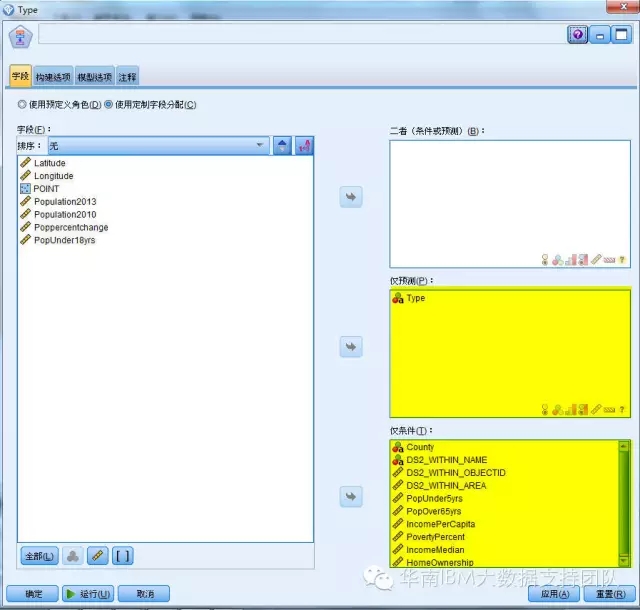
8.生成模型,得到规则
以下可以看到规则结果(列出部分规则)。
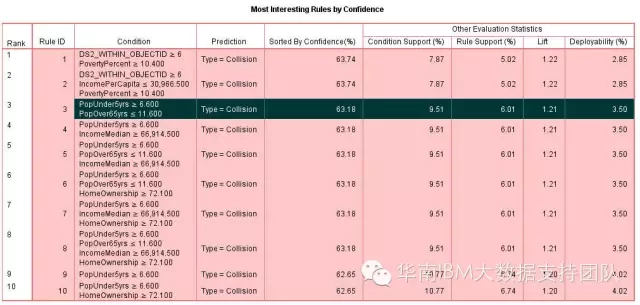
比如可以看到第三条规则(Rule ID=3)
条件(Condition)
PopUnder5yrs ≥ 6.600
PopOver65yrs ≤ 11.600
预测结果(Prediction)
Type = Collision
结果解读
如果5岁以下人口占比大于等于6.6%,65岁以上人口占比小于等于11.6%,则可能发生的犯罪类型为Collision(冲突).该规则的支持度为9.51% (即有9.51%条记录符合该规则) ,置信度为63.18%(即符合条件"PopUnder5yrs ≥ 6.600 and PopOver65yrs ≤ 11.600"的这些区域里面,有63.18%的区域发生了Collision事件),因此在做接下来的预测时,如果有区域符合以上规则(Ruld ID=3),那么我们判断该区域发生Collision事件的概率为63.18%。
9.连接原来的芝加哥地图文件,让预测结果展现在地图层之上
10.地图展现预测结果
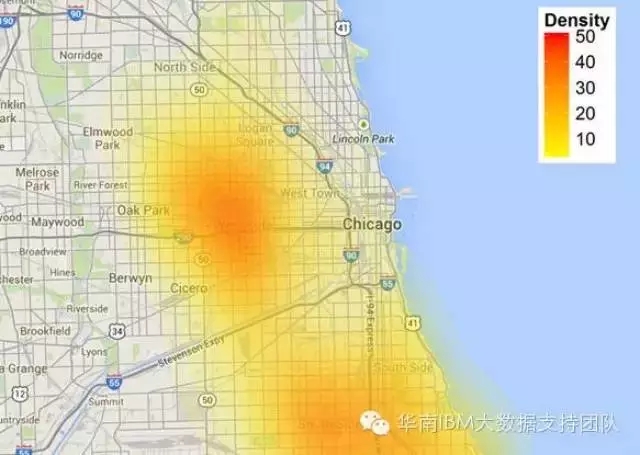
接下来我们把预测结果与地图展现结合在一起,如下图所示。
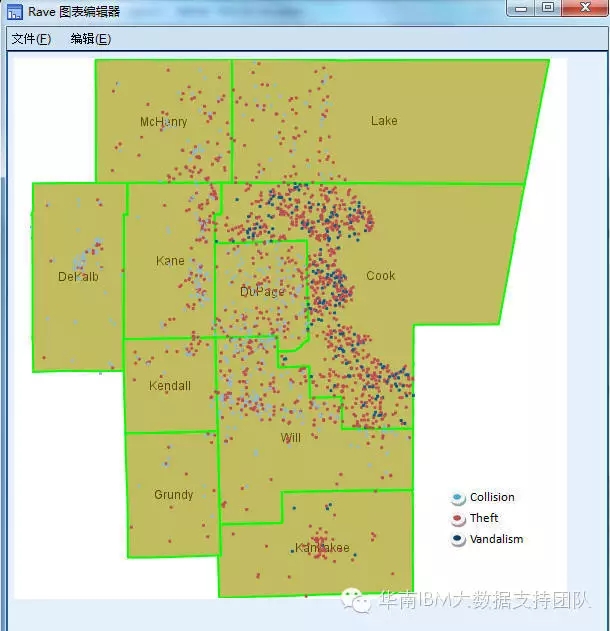
从这地图我们可以很清晰看到,我们对各类犯罪事件发生预测结果的分布情况,根据该预测结果,我们可以有在针对性地部署相关的警力,预防犯罪事件的发生。
SPSS Modeler空间数据分析扩展
以上我们通过关联规则对犯罪事件的发生进行了预测,如果使用空间-时间预测也可以实现类似的应用场景,只是分析的计算逻辑不一样。
SPSS Modeler对空间数据分析除了将其作为影响因素加入到分析过程之外,还可以通过运动轨迹(包括时间和地点)来判断人物事件的特征,我们称之为空间-时间框(STB),比如我们通过的士的运动轨迹及乘客的运动轨迹,来精准地告诉的士司机,哪些时间点,在哪些区域,有更大的乘车需求;也可以通过人员的运动轨迹对群体做细分,通过设定活动范围,找出哪些人员是家庭主妇、哪些是商务人士、哪些是白领等等,这可以更好地完善我们的客户画像。这些分析都挺有意思的,我们可以下次再做具体介绍,敬请期待吧.....

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









