






一 对Spark Streaming的理解
Spark Streaming是流式计算,当今时代是一个流处理时代,一切数据如果不是流式处理, 或者说和流式处理不相关的话,都是无效的数据。
流式处理才是我们对大数据的初步印象,而不是批处理和数据挖掘,当然Spark强悍的地方在于,他的流式处理可以在线的直接使用机器学习、图计算、SparkSQL、Spark R的成果。
Spark Streaming和其他子框架的不同之处,Spark Streaming很像基于Spark Core之上的应用程序。
二. 如何入手?
通过对Spark Streaming数据的流入,流出和处理的观察来看透内幕!
通过把Batch Interval 放的足够大,比如1分钟1次,或者5分钟1次观察spark UI来观察其运行过程。
四. 实验

1 启动nc -lk 9999,将应用发布到Spark集群上运行,并在nc中发送如下数据
2016-05-01 mahout
2016-05-01 scala
2016-05-01 hadoo
2016-05-01 spark2 在应用收到数据后会有如下输出
2016-05-01 scala
2016-05-01 spark3 从Spark 的history server中我们观察到运行了如下jobs
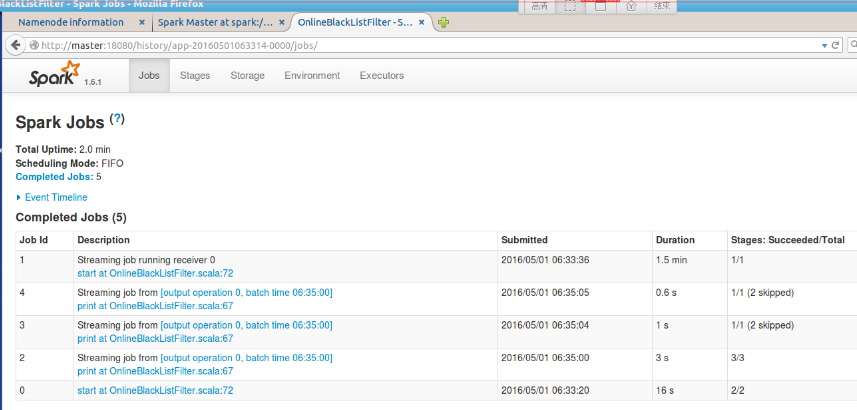
4 得出结论:图中我们可知, 有5个完成的job,但是我们从代码以RDD的视角来看只有一个job(print),由此可知,Spark Streaming应用在启动过程中,会自己启动一些job。
再看看Job 1 receiver的时间是1.5min, 从各个job所花的时间来看,整个应用运行的时间大部分时间是花在了receiver上。
从上面获得的启发:一个Spark应用中能启动多个job,不同的job之间可以相互配合,这是写Spark复杂程序的黄金模板。但是各个job之间的怎么配合还需要进一步深入。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









