




💯博主:✌全网拥有50W+粉丝、博客专家、全栈领域优质创作者、平台优质Java创作者、专注于Java技术领域和毕业项目实战✌💯
💗开发技术:SpringBoot、Vue、SSM、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、机器学习设计与开发。💗
👇🏻 推荐订阅👇🏻
Java精品实战案例《1000套》🌟获取源码请在文末查看🌟
温馨提示:文末有 优快云 平台官方提供的佩奇联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的佩奇联系方式的名片!
对程序定制感兴趣的可以先收藏起来,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,免费答疑,希望帮助更多的人
前后端架构:
Spring Boot/python/php/nodejs + Vue 前后端分离架构是一种现代Web应用开发模式,前端采用Vue框架实现页面渲染与交互,后端使用Spring Boot/python/php/nodejs提供RESTful API接口。前后端通过HTTP协议进行数据通信,常用JSON格式传输数据。该架构实现了前后端职责分离,提高了开发效率和项目可维护性:

实现截图:
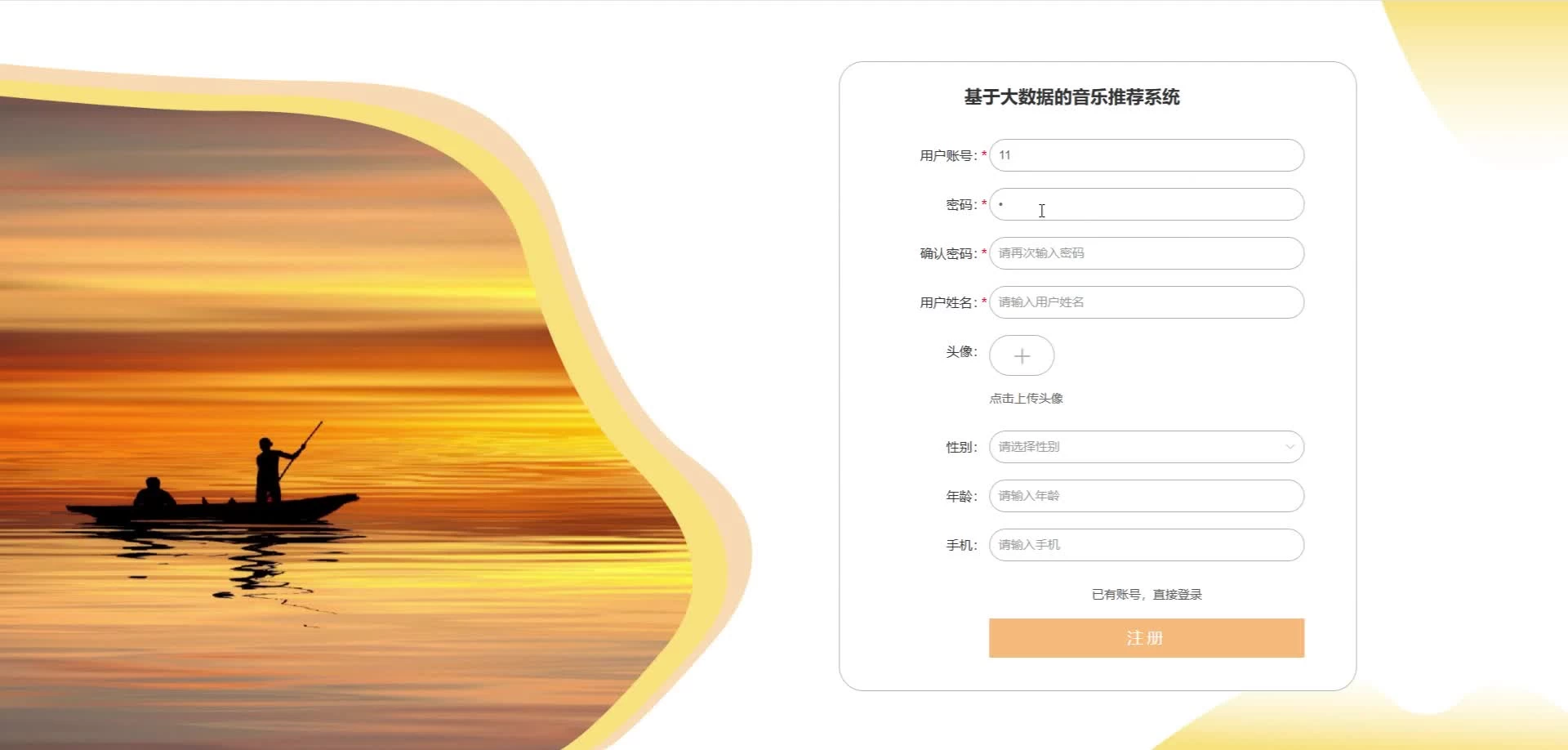
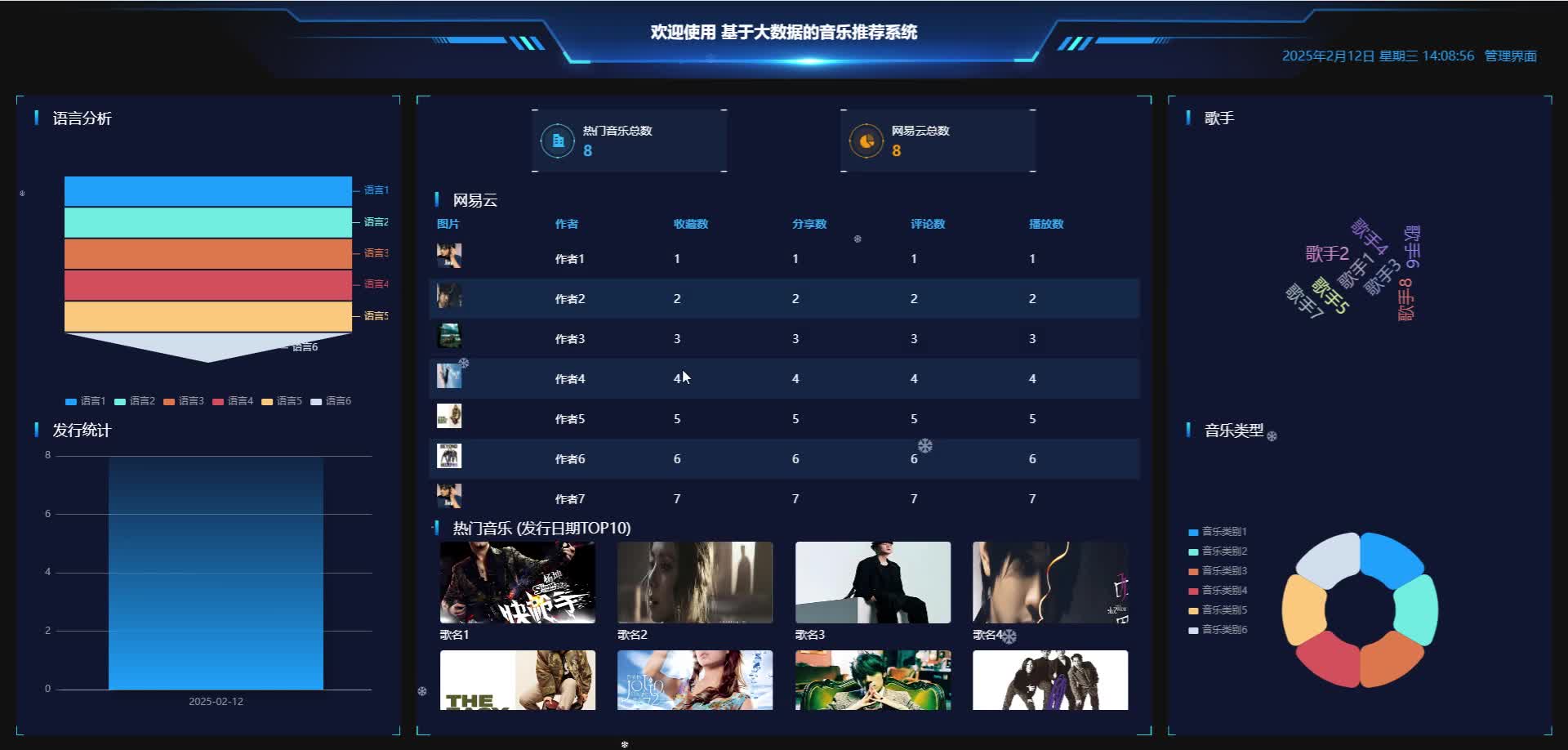
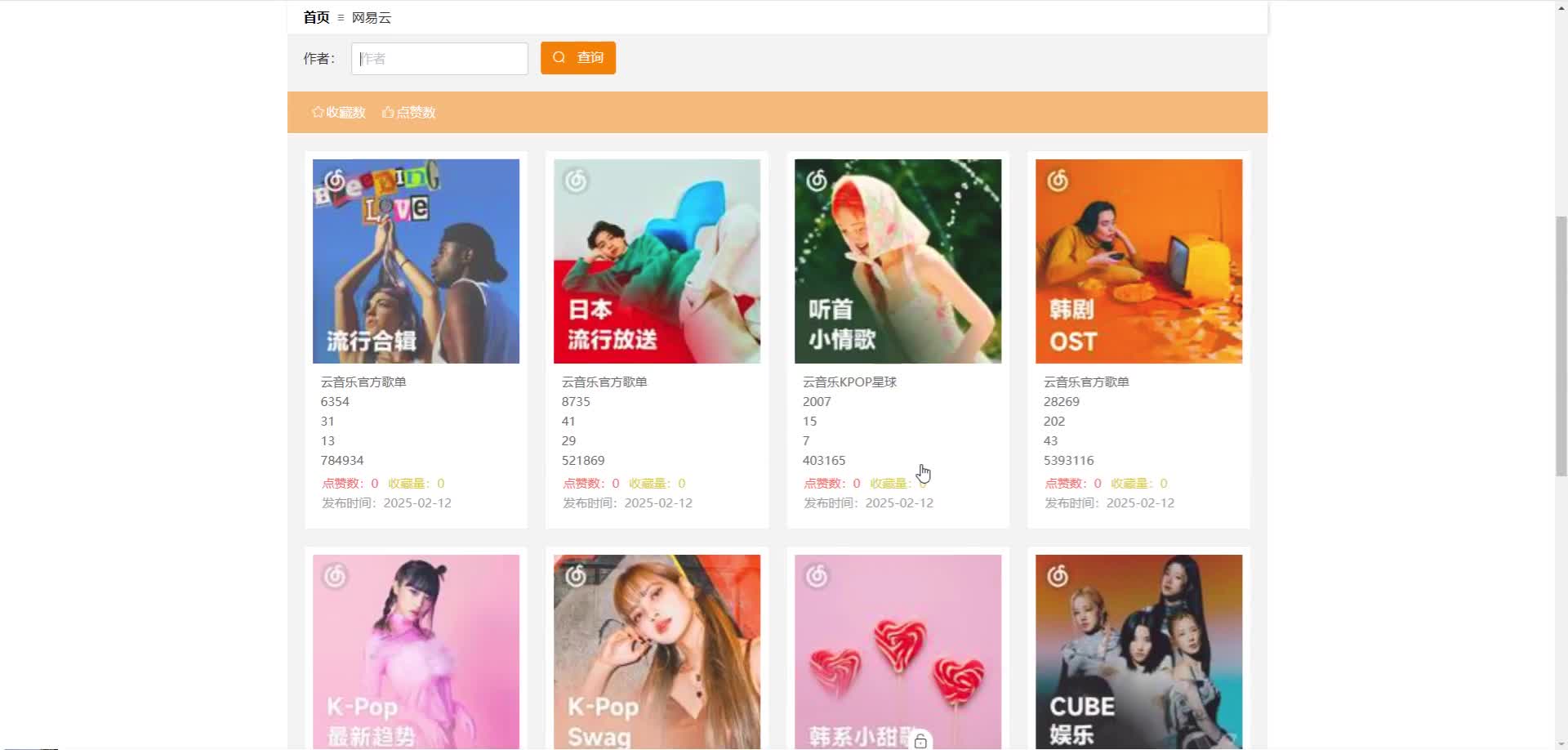
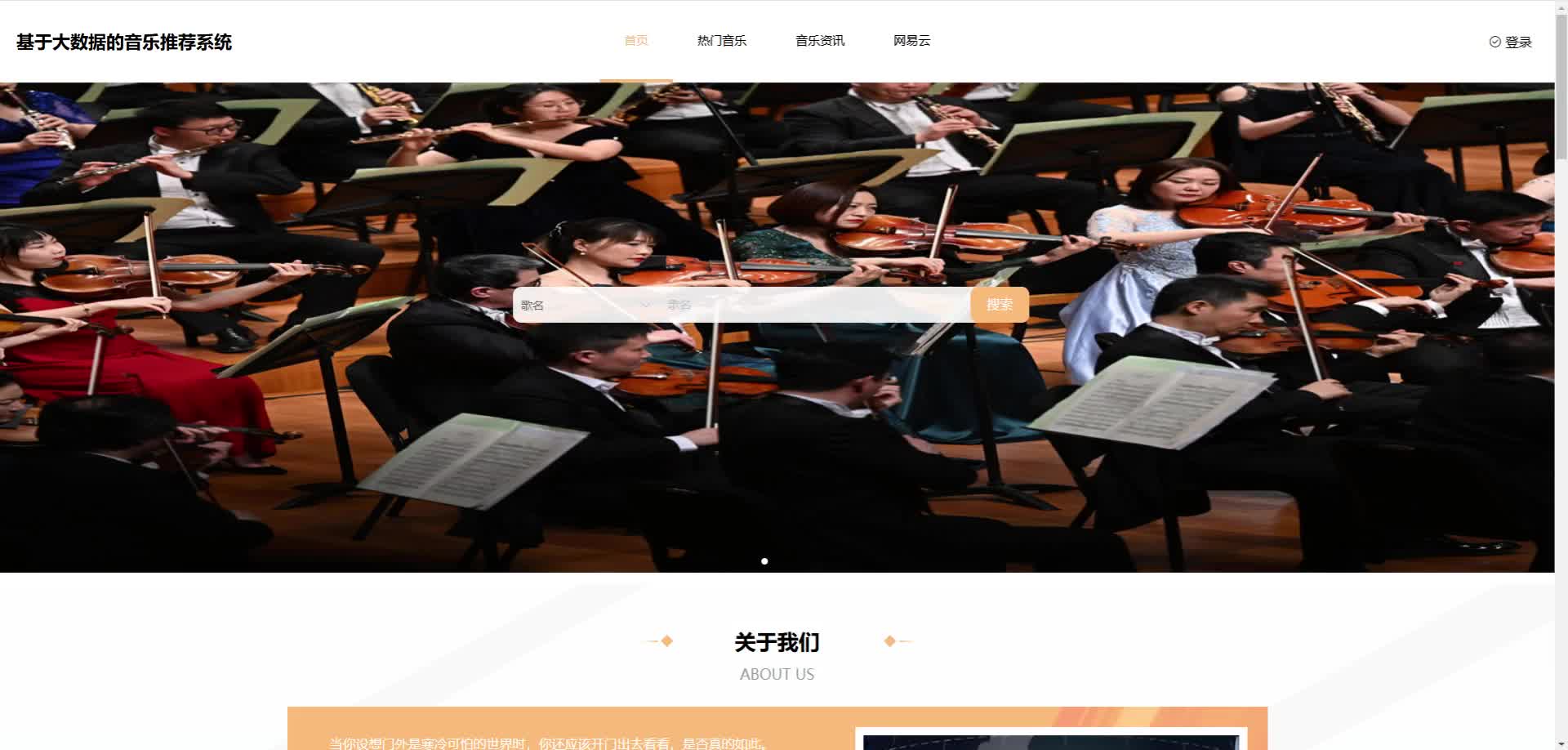
代码参考:
/**
* 密码重置
*/
@IgnoreAuth
@RequestMapping(value = "/resetPass")
public R resetPass(String username, HttpServletRequest request){
//根据登录账号判断是否存在用户信息,否则返回错误信息
YonghuEntity u = yonghuService.selectOne(new EntityWrapper<YonghuEntity>().eq("zhanghao", username));
if(u==null) {
return R.error("账号不存在");
}
//重置密码为123456,并使用des方式加密
u.setMima(EncryptUtil.desEncrypt("123456"));
yonghuService.updateById(u);
return R.ok("密码已重置为:123456");
}
/**
* 后台列表
*/
@RequestMapping("/page")
public R page(@RequestParam Map<String, Object> params,YonghuEntity yonghu,
HttpServletRequest request){
//设置查询条件
EntityWrapper<YonghuEntity> ew = new EntityWrapper<YonghuEntity>();
//查询结果
PageUtils page = yonghuService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.likeOrEq(ew, yonghu), params), params));
Map<String, String> deSens = new HashMap<>();
//给需要脱敏的字段脱敏
DeSensUtil.desensitize(page,deSens);
return R.ok().put("data", page);
}
/**
* 前台列表
*/
@IgnoreAuth
@RequestMapping("/list")
public R list(@RequestParam Map<String, Object> params,YonghuEntity yonghu,
HttpServletRequest request){
//设置查询条件
EntityWrapper<YonghuEntity> ew = new EntityWrapper<YonghuEntity>();
//查询结果
PageUtils page = yonghuService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.likeOrEq(ew, yonghu), params), params));
Map<String, String> deSens = new HashMap<>();
//给需要脱敏的字段脱敏
DeSensUtil.desensitize(page,deSens);
return R.ok().put("data", page);
}
//前端向后端发送消息
@OnMessage
public void onMessage(String message) {
System.out.println("【websocket实例】" + this);
if ("ping".equals(message)) {
sendMessage("pong", fromUserId, toUserId);
} else {
System.out.println("【websocket消息】收到客户端发来的消息:" + message);
sendMessage(message, fromUserId, toUserId);
}
}
private Map<String, String> parseQueryString(String queryString) {
Map<String, String> query_pairs = new HashMap<>();
String[] pairs = queryString.split("&");
try {
for (String pair : pairs) {
int idx = pair.indexOf("=");
String key = (idx > 0) ? URLDecoder.decode(pair.substring(0, idx), "UTF-8") : pair;
String value = (idx > 0 && pair.length() > idx + 1) ? URLDecoder.decode(pair.substring(idx + 1), "UTF-8") : null;
query_pairs.put(key, value);
}
} catch (Exception e) {
e.printStackTrace();
}
return query_pairs;
}
}
数据库sql:
DROP TABLE IF EXISTS `syslog`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `syslog` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`addtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`username` varchar(200) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名',
`operation` varchar(200) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户操作',
`method` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '请求方法',
`params` longtext COLLATE utf8mb4_unicode_ci COMMENT '请求参数',
`time` bigint(20) DEFAULT NULL COMMENT '请求时长(毫秒)',
`ip` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 'IP地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='系统日志';前后端技术介绍:
springboot介绍:
Spring Boot 是基于 Spring 框架的快速开发框架,它通过简化配置、自动装配和开箱即用的特性,极大地提高了Java后端开发的效率。其核心理念是“约定优于配置”,让开发者能够专注于业务逻辑的实现,而不必过多关注复杂的框架配置。Spring Boot 的最大优势之一是快速开发。它集成了大量常用的第三方库和Spring组件,如Spring MVC、Spring Data JPA、Spring Security等,并提供了默认配置,使开发者可以快速构建出功能完善的Web应用或微服务系统。通过启动类中的@SpringBootApplication注解,一个简单的类即可启动整个应用,大大减少了样板代码。Spring Boot 支持自动配置,能够根据项目依赖自动判断需要配置的内容,无需手动编写繁琐的XML配置文件,这对于减少人为出错和提高开发效率非常关键。Spring Boot 还内嵌了Tomcat、Jetty等Web服务器,使得应用可独立运行,部署方便,无需单独安装Web服务器。只需打包成一个可执行的JAR文件,即可通过java -jar命令运行,非常适合容器化和云部署。
Vue介绍:
Vue是一款轻量、高效、易上手的前端JavaScript框架,由尤雨溪开发并开源,采用MVVM架构模式,专注于构建用户界面和单页应用。它通过数据驱动和组件化的开发方式,让开发者能更高效地构建复杂的交互界面。Vue的核心库只关注视图层,拥有响应式的数据绑定和灵活的组件系统,易于与其它库或已有项目整合,同时也能与Vue Router、Vuex等配套库组合用于构建完整的前端项目。其语法简洁、文档完善,极大降低了前端开发的门槛,是前后端分离项目中常用的前端框架之一。Vue支持双向数据绑定,提升了开发效率,也便于状态管理与视图同步,广泛应用于企业级系统、后台管理平台及各种Web应用开发中。
全包定制案例:
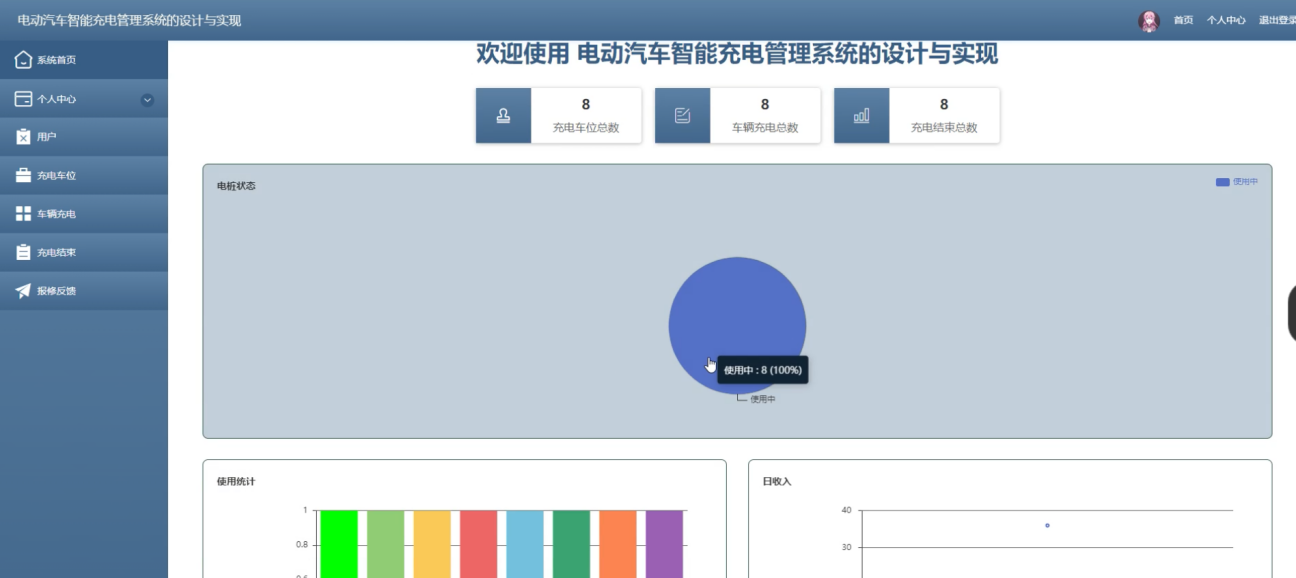

代码获取:
为什么选择我(我可以一对一指导并实现需求,一对一推荐)实现定制!!!
我是程序员佩奇,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是优快云特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。
已经为上百名同学获得优秀毕业生!
源码获取:
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏

















 2365
2365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









