




 本文介绍如何使用Python正则表达式从Google高级搜索的结果中提取站点地址。通过分析页面源码,利用开发工具找到目标信息所在的HTML标签,编写正则表达式实现提取。代码示例展示在Python3.2环境下操作,强调了自学Python及提升计算机基础的重要性。
本文介绍如何使用Python正则表达式从Google高级搜索的结果中提取站点地址。通过分析页面源码,利用开发工具找到目标信息所在的HTML标签,编写正则表达式实现提取。代码示例展示在Python3.2环境下操作,强调了自学Python及提升计算机基础的重要性。
@本文来源于公众号:csdn2299,喜欢可以关注公众号 程序员学府
正则表达式对于Python来说并不是独有的,最近在把google搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址。
这其中涉及几个需要解决的问题:
1、获取搜索的结果文本
为了获得更多的地址,我使用了Google的高级搜索功能,每个页面显示100条结果。
获得显示的结果后,可以查看源码,并保持成文本文件就有了搜索的结果文本
2、分析如何提取站点信息
首先需要分析获取的页面,查看以怎样的方式可以提取出站点信息。
我使用IE8自带的开发工具(按F12就会弹出来)中的探查器功能查看自己要关心的内容有什么特殊的格式
从上图可以看出我需要的站点在标签中,所以我使用正则表达式提取这其中的文本是否就可以呢?
3、编写正则表达式来获取站点地址
接下来的就是写表达式了,我使用Python3.2编写的,方便好用(_)
代码如下,先把搜索结果页面保持到e:/t3.txt中,在执行如下代码
import re
p = re.compile(r'<cite>([^<>\/].+?)</cite>')
f = open("e:/t3.txt", encoding='utf-8')
content = f.read()
print ("\n".join(p.findall(content)))
运行如下: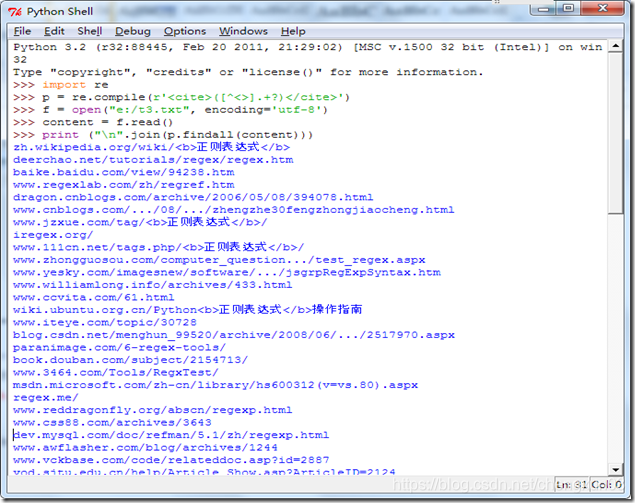
非常感谢你的阅读
大学的时候选择了自学python,工作了发现吃了计算机基础不好的亏,学历不行这是
没办法的事,只能后天弥补,于是在编码之外开启了自己的逆袭之路,不断的学习python核心知识,深入的研习计算机基础知识,整理好了,如果你也不甘平庸,那就与我一起在编码之外,不断成长吧!
其实这里不仅有技术,更有那些技术之外的东西,比如,如何做一个精致的程序员,而不是“屌丝”,程序员本身就是高贵的一种存在啊,难道不是吗?[点击加入]想做你自己想成为高尚人,加油!

















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









