






 本文是深度学习训练营的学习记录,介绍了生成对抗网络(GAN)。GAN由生成器和判别器组成,基于博弈思想,是无监督学习。文中说明了其基本原理,还给出了Python和Pytorch环境下的实践步骤,包括环境设置、数据准备、模型设计、训练及效果展示。
本文是深度学习训练营的学习记录,介绍了生成对抗网络(GAN)。GAN由生成器和判别器组成,基于博弈思想,是无监督学习。文中说明了其基本原理,还给出了Python和Pytorch环境下的实践步骤,包括环境设置、数据准备、模型设计、训练及效果展示。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
理论知识
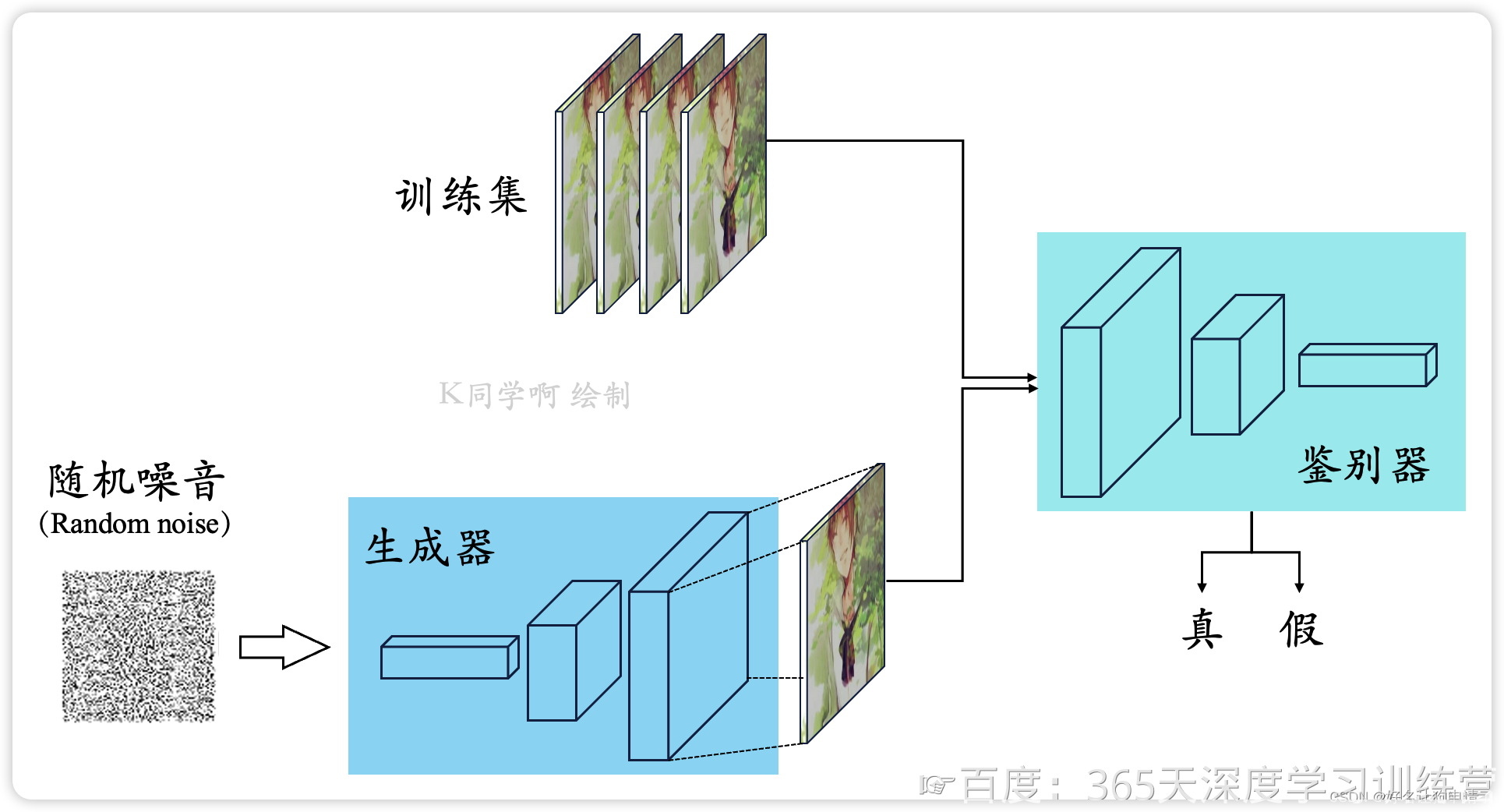
生成对抗网络(Generative Adversarial Networks, GAN)并不是指某一个具体的神经网络,而是指一类基于博弈思想而设计的神经网络。
GAN通常由两个部分组成,分别是:生成器(Generator)和判别器(Discriminator)。其中,生成器从某种噪声分布中随机采样作为输入,输出与训练集中真实样本非常相似的人工样本;判别器的输入则为真实样本或人工样本,其目的是将人工样本与真实的样本尽可能的区分出来。
理想情况下,经过足够多次的博弈,判别器会无法分辨出样本的真实性,这时可以认为生成器的结果已经逼真到让判别器无法分辨,就可以停止博弈了。
生成器
GANs中,生成器G选取随机噪声z作为输入,通过生成器的不断拟合,最终输出一个和真实样本尺寸相同,分布相似的伪造样本G(z)。生成器的本质是一个使用生成式方法的模型,它对数据的分布假设和分布参数进行学习,然后根据学习到的模型重新采样出新的样本。
从数据角度来说,生成式的方法对于特定的真实数据,首先要对数据的显式变量或隐含变量做分布假设;然后再将真实的数据输入到模型中对变量、参数进行训练;最后得到一个学习后的近似分布,这个分布可以用来生成新的数据。
从机器学习的角度来说,模型不会做分布假设,而是通过不断地学习真实的数据,对模型进行修正,最后也可以得到一个学习后的模型来做样本的生成任务。这种方法不同于数学方法,学习的过程对人类理解较不直观。
判别器
GANs中,判别器D对于输入的样本x,输出一个[0, 1]之间的概率数值D(x)。x可以是来自于原始数据集中的真实样本x,也可以是来自于生成器G的人工样本G(z)。通常约定,概率值 D(x) 越接近于1就代表样本为真实样本的可能性越大;反之概率值越小则此样本为伪造样本的可能性更大。也就是说,这里的判别器是一个二分类的神经网络分类器,目的不是判定输入数据的原始类别,而是区分输入样本的真伪。可以注意到,不管是在生成器中还是在判别器中,样本的类别信息都没有用到,也表明GAN是一个无监督学习的过程。
基本原理
GAN是博弈论和机器学习相结合的产物。于2014年Ian Goodfellow的论文中问世。
环境
Python: 3.11
Pytorch: 2.3.0+cu121
显卡:GTX3070
步骤
环境设置
首先设置数据的目录
PARENT_DIR = 'GAN01/'
然后引用本次需要的包
import torch.nn as nn
import torch
import numpy as np
import os
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision import transforms, datasets
import torch.optim as optim
创建需要用到的文件夹
os.makedirs(PARENT_DIR + 'images/', exist_ok=True) # 保存生成的图像
os.makedirs(PARENT_DIR + 'save/', exist_ok=True) # 保存模型参数
os.makedirs(PARENT_DIR + 'datasets', exist_ok=True) # 保存下载的数据集
超参数设置
n_epochs = 50 # 训练轮数
batch_size = 64 # 批次大小
lr = 2e-4 # 学习率
b1 = 0.5 # Adam参数1
b2 = 0.999 # Adam参数2
n_cpu = 2 # 数据加载时使用的cpu数量
latent_dim = 100 # 随机向量的维度
img_size = 28 # 图像的大小
channels = 1 # 图像的通道数
sample_intervals = 500 # 保存生成图像的间隔
img_shape = (channels, img_size, img_size) # 图像的尺寸
img_area = np.prod(img_shape)
# 全局设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
下载数据集
mnist = datasets.MNIST(root=PARENT_DIR+'/datasets', train=True, download=True, transform=transforms.Compose([
transforms.Resize(img_size),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]))
配置数据加载器
dataloader = DataLoader(mnist, batch_size=batch_size, shuffle=True)
模型设计
鉴别器模块
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(img_area, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
生成器模块
class Generator(nn.Module):
def __init__(self):
super().__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, img_area),
nn.Tanh(),
)
def forward(self, z):
imgs = self.model(z)
imgs = imgs.view(imgs.size(0), *img_shape)
return imgs
模型训练
创建模型实例
# 生成器
generator = Generator().to(device)
# 判别器
discriminator = Discriminator().to(device)
# 损失函数
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
训练过程
for epoch in n_epochs:
for i, (imgs, _ ) in enumerate(dataloader):
imgs = imgs.view(imgs.size(0), -1)
real_img = Variable(imgs).to(device)
real_label = Variable(torch.ones(imgs.size(0), -1).to(device)
fake_label = Variable(torch.zeros(imgs.size(0), -1).to(device)
# 训练判别器 - 正例
real_out = discriminator(real_img)
loss_real_D = criterion(real_out, real_label)
real_scores = real_out
# 训练判别器 - 反例
z = Variable(torch.randn(imgs.size(0), latent_dim).to(device)
fake_img = generator(z).detach()
fake_out = discriminator(fake_img)
loss_fake_D = criterion(fake_out, fake_label)
fake_scores = fake_out
# 训练判别器
loss_D = loss_real_D + loss_fake_D
optimizer_D.zero_grad()
loss_D.backward()
optimizer_D.step()
# 训练生成器
z = Variable(torch.randn(imgs.size(0), latent_dim).to(device)
fake_img = generator(z)
output = discriminator(fake_img)
loss_G = criterion(output, real_label)
optimizer_G.zero_grad()
loss_G.backward()
optimizer_G.step()
# 日志打印
if (i+1) % 300 == 0:
print('[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [D real: %f] [D fake: %f]' % (epoch, n_epochs, i, len(dataloader), loss_D.item(). loss_G.item(), real_scores.data.mean(). fake_scores.data.mean()))
# 保存训练过的图片
batches_done = epoch * len(dataloader) + i
if batches_done % sample_intervals == 0:
save_image(fake_img.data[:25], (PARENT_DIR + 'images/%d.png') % batches_done, nrow-5, normalize=True)
训练过程
[Epoch 0/50] [Batch 299/938] [D loss: 1.420514] [G loss: 1.961581] [D real: 0.811836] [D fake: 0.694541]
[Epoch 0/50] [Batch 599/938] [D loss: 0.922259] [G loss: 1.839481] [D real: 0.734683] [D fake: 0.444037]
[Epoch 0/50] [Batch 899/938] [D loss: 0.883128] [G loss: 1.256595] [D real: 0.541903] [D fake: 0.187425]
[Epoch 1/50] [Batch 299/938] [D loss: 0.952949] [G loss: 0.963832] [D real: 0.596297] [D fake: 0.311674]
[Epoch 1/50] [Batch 599/938] [D loss: 0.950359] [G loss: 0.834425] [D real: 0.543845] [D fake: 0.203204]
[Epoch 1/50] [Batch 899/938] [D loss: 0.973158] [G loss: 1.313089] [D real: 0.631495] [D fake: 0.311304]
[Epoch 2/50] [Batch 299/938] [D loss: 0.812588] [G loss: 1.251890] [D real: 0.721250] [D fake: 0.340005]
[Epoch 2/50] [Batch 599/938] [D loss: 0.804412] [G loss: 1.442456] [D real: 0.651448] [D fake: 0.206814]
[Epoch 2/50] [Batch 899/938] [D loss: 0.796317] [G loss: 1.303452] [D real: 0.636756] [D fake: 0.235744]
[Epoch 3/50] [Batch 299/938] [D loss: 0.818155] [G loss: 1.293481] [D real: 0.613244] [D fake: 0.196964]
[Epoch 3/50] [Batch 599/938] [D loss: 0.929434] [G loss: 1.275021] [D real: 0.659611] [D fake: 0.259689]
[Epoch 3/50] [Batch 899/938] [D loss: 0.712755] [G loss: 2.305767] [D real: 0.800935] [D fake: 0.339025]
[Epoch 4/50] [Batch 299/938] [D loss: 0.740710] [G loss: 2.199127] [D real: 0.808014] [D fake: 0.370125]
[Epoch 4/50] [Batch 599/938] [D loss: 0.796852] [G loss: 2.494107] [D real: 0.848230] [D fake: 0.427257]
[Epoch 4/50] [Batch 899/938] [D loss: 0.801556] [G loss: 1.366514] [D real: 0.619396] [D fake: 0.125212]
[Epoch 5/50] [Batch 299/938] [D loss: 0.866250] [G loss: 2.395396] [D real: 0.806042] [D fake: 0.434844]
[Epoch 5/50] [Batch 599/938] [D loss: 0.802661] [G loss: 1.157616] [D real: 0.661669] [D fake: 0.212725]
[Epoch 5/50] [Batch 899/938] [D loss: 0.886610] [G loss: 1.533640] [D real: 0.700454] [D fake: 0.274916]
[Epoch 6/50] [Batch 299/938] [D loss: 0.677418] [G loss: 2.137760] [D real: 0.714654] [D fake: 0.156297]
[Epoch 6/50] [Batch 599/938] [D loss: 0.852677] [G loss: 1.679850] [D real: 0.712336] [D fake: 0.336238]
[Epoch 6/50] [Batch 899/938] [D loss: 0.894991] [G loss: 1.345476] [D real: 0.609528] [D fake: 0.158049]
[Epoch 7/50] [Batch 299/938] [D loss: 0.749311] [G loss: 2.185987] [D real: 0.786740] [D fake: 0.332746]
[Epoch 7/50] [Batch 599/938] [D loss: 0.823957] [G loss: 2.364408] [D real: 0.828811] [D fake: 0.423014]
[Epoch 7/50] [Batch 899/938] [D loss: 0.811460] [G loss: 1.441192] [D real: 0.611505] [D fake: 0.110525]
[Epoch 8/50] [Batch 299/938] [D loss: 0.653301] [G loss: 1.886070] [D real: 0.764065] [D fake: 0.245890]
[Epoch 8/50] [Batch 599/938] [D loss: 0.843600] [G loss: 1.917097] [D real: 0.792145] [D fake: 0.408509]
[Epoch 8/50] [Batch 899/938] [D loss: 0.798109] [G loss: 1.314119] [D real: 0.653977] [D fake: 0.185030]
[Epoch 9/50] [Batch 299/938] [D loss: 0.947685] [G loss: 3.152684] [D real: 0.910022] [D fake: 0.502504]
[Epoch 9/50] [Batch 599/938] [D loss: 0.959668] [G loss: 0.570251] [D real: 0.570070] [D fake: 0.106891]
[Epoch 9/50] [Batch 899/938] [D loss: 0.856521] [G loss: 1.218792] [D real: 0.566056] [D fake: 0.080608]
[Epoch 10/50] [Batch 299/938] [D loss: 0.935204] [G loss: 2.985981] [D real: 0.830788] [D fake: 0.465305]
[Epoch 10/50] [Batch 599/938] [D loss: 0.692477] [G loss: 1.852279] [D real: 0.835356] [D fake: 0.337193]
[Epoch 10/50] [Batch 899/938] [D loss: 0.763710] [G loss: 1.751910] [D real: 0.770129] [D fake: 0.313941]
[Epoch 11/50] [Batch 299/938] [D loss: 0.703495] [G loss: 1.861948] [D real: 0.808757] [D fake: 0.338974]
[Epoch 11/50] [Batch 599/938] [D loss: 0.815235] [G loss: 2.208552] [D real: 0.757724] [D fake: 0.324712]
[Epoch 11/50] [Batch 899/938] [D loss: 0.997158] [G loss: 2.022480] [D real: 0.701744] [D fake: 0.380837]
[Epoch 12/50] [Batch 299/938] [D loss: 0.759668] [G loss: 1.911369] [D real: 0.777231] [D fake: 0.329774]
[Epoch 12/50] [Batch 599/938] [D loss: 0.845963] [G loss: 2.053480] [D real: 0.846165] [D fake: 0.441215]
[Epoch 12/50] [Batch 899/938] [D loss: 1.091019] [G loss: 1.313121] [D real: 0.482313] [D fake: 0.064774]
[Epoch 13/50] [Batch 299/938] [D loss: 0.860023] [G loss: 1.465194] [D real: 0.635496] [D fake: 0.124226]
[Epoch 13/50] [Batch 599/938] [D loss: 0.756671] [G loss: 1.716278] [D real: 0.674119] [D fake: 0.216907]
[Epoch 13/50] [Batch 899/938] [D loss: 0.716931] [G loss: 1.802271] [D real: 0.683680] [D fake: 0.195853]
[Epoch 14/50] [Batch 299/938] [D loss: 1.083009] [G loss: 1.358789] [D real: 0.642891] [D fake: 0.376322]
[Epoch 14/50] [Batch 599/938] [D loss: 1.075695] [G loss: 0.908844] [D real: 0.521514] [D fake: 0.123268]
[Epoch 14/50] [Batch 899/938] [D loss: 0.943146] [G loss: 1.356610] [D real: 0.595750] [D fake: 0.180492]
[Epoch 15/50] [Batch 299/938] [D loss: 0.929019] [G loss: 0.617656] [D real: 0.552842] [D fake: 0.151570]
[Epoch 15/50] [Batch 599/938] [D loss: 1.052583] [G loss: 2.127165] [D real: 0.853073] [D fake: 0.523554]
[Epoch 15/50] [Batch 899/938] [D loss: 1.021363] [G loss: 0.625215] [D real: 0.529443] [D fake: 0.186696]
[Epoch 16/50] [Batch 299/938] [D loss: 0.929158] [G loss: 2.104063] [D real: 0.770136] [D fake: 0.399831]
[Epoch 16/50] [Batch 599/938] [D loss: 0.832833] [G loss: 1.665707] [D real: 0.736168] [D fake: 0.343671]
[Epoch 16/50] [Batch 899/938] [D loss: 0.730055] [G loss: 1.724510] [D real: 0.755085] [D fake: 0.289238]
[Epoch 17/50] [Batch 299/938] [D loss: 0.677890] [G loss: 1.755648] [D real: 0.779917] [D fake: 0.276746]
[Epoch 17/50] [Batch 599/938] [D loss: 0.920615] [G loss: 1.416380] [D real: 0.681394] [D fake: 0.310024]
[Epoch 17/50] [Batch 899/938] [D loss: 0.937411] [G loss: 2.415898] [D real: 0.789968] [D fake: 0.450372]
[Epoch 18/50] [Batch 299/938] [D loss: 0.841531] [G loss: 1.211814] [D real: 0.672196] [D fake: 0.268470]
[Epoch 18/50] [Batch 599/938] [D loss: 0.806454] [G loss: 1.246511] [D real: 0.657565] [D fake: 0.237899]
[Epoch 18/50] [Batch 899/938] [D loss: 0.965483] [G loss: 1.558758] [D real: 0.590535] [D fake: 0.202962]
[Epoch 19/50] [Batch 299/938] [D loss: 0.941242] [G loss: 1.201063] [D real: 0.580414] [D fake: 0.159809]
[Epoch 19/50] [Batch 599/938] [D loss: 0.763269] [G loss: 1.117927] [D real: 0.687018] [D fake: 0.217924]
[Epoch 19/50] [Batch 899/938] [D loss: 1.208787] [G loss: 0.476900] [D real: 0.450625] [D fake: 0.153400]
[Epoch 20/50] [Batch 299/938] [D loss: 0.938517] [G loss: 1.020504] [D real: 0.583086] [D fake: 0.211353]
[Epoch 20/50] [Batch 599/938] [D loss: 0.814142] [G loss: 1.717330] [D real: 0.767125] [D fake: 0.357556]
[Epoch 20/50] [Batch 899/938] [D loss: 0.914405] [G loss: 1.084474] [D real: 0.614264] [D fake: 0.197619]
[Epoch 21/50] [Batch 299/938] [D loss: 0.911557] [G loss: 1.857509] [D real: 0.690771] [D fake: 0.324216]
[Epoch 21/50] [Batch 599/938] [D loss: 0.846429] [G loss: 1.522789] [D real: 0.756585] [D fake: 0.380105]
[Epoch 21/50] [Batch 899/938] [D loss: 0.903101] [G loss: 1.311370] [D real: 0.641948] [D fake: 0.270648]
[Epoch 22/50] [Batch 299/938] [D loss: 1.136434] [G loss: 1.967754] [D real: 0.829407] [D fake: 0.539150]
[Epoch 22/50] [Batch 599/938] [D loss: 0.761561] [G loss: 1.451730] [D real: 0.719943] [D fake: 0.253529]
[Epoch 22/50] [Batch 899/938] [D loss: 0.947273] [G loss: 1.578539] [D real: 0.757281] [D fake: 0.402005]
[Epoch 23/50] [Batch 299/938] [D loss: 0.984664] [G loss: 1.381901] [D real: 0.676672] [D fake: 0.345036]
[Epoch 23/50] [Batch 599/938] [D loss: 1.056997] [G loss: 1.273649] [D real: 0.645240] [D fake: 0.341262]
[Epoch 23/50] [Batch 899/938] [D loss: 0.846916] [G loss: 1.618449] [D real: 0.673545] [D fake: 0.255247]
[Epoch 24/50] [Batch 299/938] [D loss: 1.020407] [G loss: 2.467137] [D real: 0.789029] [D fake: 0.483512]
[Epoch 24/50] [Batch 599/938] [D loss: 1.039248] [G loss: 1.711153] [D real: 0.794231] [D fake: 0.498774]
[Epoch 24/50] [Batch 899/938] [D loss: 0.891359] [G loss: 1.549422] [D real: 0.648600] [D fake: 0.242511]
[Epoch 25/50] [Batch 299/938] [D loss: 0.828505] [G loss: 1.678849] [D real: 0.726778] [D fake: 0.317394]
[Epoch 25/50] [Batch 599/938] [D loss: 0.835318] [G loss: 1.619812] [D real: 0.776715] [D fake: 0.385841]
[Epoch 25/50] [Batch 899/938] [D loss: 0.903816] [G loss: 2.057058] [D real: 0.759536] [D fake: 0.398490]
[Epoch 26/50] [Batch 299/938] [D loss: 0.963138] [G loss: 2.443241] [D real: 0.829611] [D fake: 0.456530]
[Epoch 26/50] [Batch 599/938] [D loss: 1.219956] [G loss: 0.801282] [D real: 0.441290] [D fake: 0.112515]
[Epoch 26/50] [Batch 899/938] [D loss: 1.282843] [G loss: 0.742314] [D real: 0.440508] [D fake: 0.091521]
[Epoch 27/50] [Batch 299/938] [D loss: 1.044027] [G loss: 1.633780] [D real: 0.730091] [D fake: 0.396968]
[Epoch 27/50] [Batch 599/938] [D loss: 1.039986] [G loss: 1.568461] [D real: 0.674084] [D fake: 0.377297]
[Epoch 27/50] [Batch 899/938] [D loss: 0.949207] [G loss: 1.193219] [D real: 0.626887] [D fake: 0.216131]
[Epoch 28/50] [Batch 299/938] [D loss: 0.813487] [G loss: 1.266051] [D real: 0.645924] [D fake: 0.218628]
[Epoch 28/50] [Batch 599/938] [D loss: 0.849271] [G loss: 1.476346] [D real: 0.680232] [D fake: 0.284335]
[Epoch 28/50] [Batch 899/938] [D loss: 0.831895] [G loss: 1.817335] [D real: 0.720941] [D fake: 0.326133]
[Epoch 29/50] [Batch 299/938] [D loss: 0.772127] [G loss: 1.586798] [D real: 0.751645] [D fake: 0.311902]
[Epoch 29/50] [Batch 599/938] [D loss: 0.862494] [G loss: 1.736295] [D real: 0.752732] [D fake: 0.362572]
[Epoch 29/50] [Batch 899/938] [D loss: 0.880609] [G loss: 1.480912] [D real: 0.700861] [D fake: 0.325915]
[Epoch 30/50] [Batch 299/938] [D loss: 0.933771] [G loss: 1.715545] [D real: 0.721025] [D fake: 0.349197]
[Epoch 30/50] [Batch 599/938] [D loss: 0.795781] [G loss: 1.756403] [D real: 0.724120] [D fake: 0.293765]
[Epoch 30/50] [Batch 899/938] [D loss: 0.896606] [G loss: 1.373884] [D real: 0.632874] [D fake: 0.245156]
[Epoch 31/50] [Batch 299/938] [D loss: 0.852626] [G loss: 1.650979] [D real: 0.711945] [D fake: 0.285480]
[Epoch 31/50] [Batch 599/938] [D loss: 0.742924] [G loss: 1.555502] [D real: 0.769613] [D fake: 0.325262]
[Epoch 31/50] [Batch 899/938] [D loss: 0.762007] [G loss: 1.213594] [D real: 0.643857] [D fake: 0.145954]
[Epoch 32/50] [Batch 299/938] [D loss: 0.993882] [G loss: 1.768500] [D real: 0.755884] [D fake: 0.419389]
[Epoch 32/50] [Batch 599/938] [D loss: 0.848629] [G loss: 1.113061] [D real: 0.616361] [D fake: 0.175378]
[Epoch 32/50] [Batch 899/938] [D loss: 0.698725] [G loss: 1.573485] [D real: 0.740353] [D fake: 0.234537]
[Epoch 33/50] [Batch 299/938] [D loss: 0.755047] [G loss: 1.388250] [D real: 0.708191] [D fake: 0.241282]
[Epoch 33/50] [Batch 599/938] [D loss: 0.990773] [G loss: 2.253703] [D real: 0.805822] [D fake: 0.437487]
[Epoch 33/50] [Batch 899/938] [D loss: 0.830166] [G loss: 1.082243] [D real: 0.652710] [D fake: 0.227879]
[Epoch 34/50] [Batch 299/938] [D loss: 1.024394] [G loss: 1.954563] [D real: 0.836840] [D fake: 0.475636]
[Epoch 34/50] [Batch 599/938] [D loss: 0.840215] [G loss: 1.340230] [D real: 0.764619] [D fake: 0.369560]
[Epoch 34/50] [Batch 899/938] [D loss: 1.438599] [G loss: 0.660933] [D real: 0.413844] [D fake: 0.109160]
[Epoch 35/50] [Batch 299/938] [D loss: 0.917200] [G loss: 0.927326] [D real: 0.610525] [D fake: 0.210112]
[Epoch 35/50] [Batch 599/938] [D loss: 0.994579] [G loss: 0.908950] [D real: 0.594053] [D fake: 0.224407]
[Epoch 35/50] [Batch 899/938] [D loss: 0.762671] [G loss: 1.456851] [D real: 0.686805] [D fake: 0.211406]
[Epoch 36/50] [Batch 299/938] [D loss: 0.956092] [G loss: 1.296812] [D real: 0.609507] [D fake: 0.261673]
[Epoch 36/50] [Batch 599/938] [D loss: 1.045313] [G loss: 0.625988] [D real: 0.543889] [D fake: 0.148871]
[Epoch 36/50] [Batch 899/938] [D loss: 0.914145] [G loss: 1.017588] [D real: 0.629813] [D fake: 0.258396]
[Epoch 37/50] [Batch 299/938] [D loss: 1.106073] [G loss: 2.715152] [D real: 0.883800] [D fake: 0.552771]
[Epoch 37/50] [Batch 599/938] [D loss: 0.908618] [G loss: 1.260299] [D real: 0.645083] [D fake: 0.216520]
[Epoch 37/50] [Batch 899/938] [D loss: 0.703876] [G loss: 1.610951] [D real: 0.671662] [D fake: 0.161172]
[Epoch 38/50] [Batch 299/938] [D loss: 0.884505] [G loss: 1.696165] [D real: 0.772144] [D fake: 0.350858]
[Epoch 38/50] [Batch 599/938] [D loss: 0.844707] [G loss: 1.694735] [D real: 0.809112] [D fake: 0.404328]
[Epoch 38/50] [Batch 899/938] [D loss: 0.796929] [G loss: 1.719817] [D real: 0.733676] [D fake: 0.300009]
[Epoch 39/50] [Batch 299/938] [D loss: 0.761804] [G loss: 2.002748] [D real: 0.821613] [D fake: 0.367843]
[Epoch 39/50] [Batch 599/938] [D loss: 1.006947] [G loss: 1.178393] [D real: 0.589913] [D fake: 0.217992]
[Epoch 39/50] [Batch 899/938] [D loss: 0.936502] [G loss: 1.313496] [D real: 0.586952] [D fake: 0.150109]
[Epoch 40/50] [Batch 299/938] [D loss: 1.180398] [G loss: 0.819056] [D real: 0.525922] [D fake: 0.152922]
[Epoch 40/50] [Batch 599/938] [D loss: 0.921446] [G loss: 2.024451] [D real: 0.776659] [D fake: 0.412260]
[Epoch 40/50] [Batch 899/938] [D loss: 0.839164] [G loss: 1.452876] [D real: 0.710732] [D fake: 0.266918]
[Epoch 41/50] [Batch 299/938] [D loss: 0.788981] [G loss: 1.553157] [D real: 0.698234] [D fake: 0.259889]
[Epoch 41/50] [Batch 599/938] [D loss: 0.906144] [G loss: 1.927676] [D real: 0.746730] [D fake: 0.321029]
[Epoch 41/50] [Batch 899/938] [D loss: 1.006926] [G loss: 1.514269] [D real: 0.658016] [D fake: 0.297868]
[Epoch 42/50] [Batch 299/938] [D loss: 0.912167] [G loss: 1.337582] [D real: 0.640350] [D fake: 0.238920]
[Epoch 42/50] [Batch 599/938] [D loss: 1.029311] [G loss: 1.269561] [D real: 0.581456] [D fake: 0.176677]
[Epoch 42/50] [Batch 899/938] [D loss: 0.851943] [G loss: 2.247482] [D real: 0.792886] [D fake: 0.387960]
[Epoch 43/50] [Batch 299/938] [D loss: 0.813233] [G loss: 1.892390] [D real: 0.755459] [D fake: 0.335725]
[Epoch 43/50] [Batch 599/938] [D loss: 0.849235] [G loss: 1.451456] [D real: 0.713452] [D fake: 0.277743]
[Epoch 43/50] [Batch 899/938] [D loss: 0.796001] [G loss: 1.534391] [D real: 0.769308] [D fake: 0.326947]
[Epoch 44/50] [Batch 299/938] [D loss: 0.828683] [G loss: 2.295016] [D real: 0.865256] [D fake: 0.432770]
[Epoch 44/50] [Batch 599/938] [D loss: 0.784839] [G loss: 1.292179] [D real: 0.740413] [D fake: 0.307002]
[Epoch 44/50] [Batch 899/938] [D loss: 0.869467] [G loss: 1.554963] [D real: 0.669150] [D fake: 0.236974]
[Epoch 45/50] [Batch 299/938] [D loss: 0.955422] [G loss: 0.962375] [D real: 0.612503] [D fake: 0.210810]
[Epoch 45/50] [Batch 599/938] [D loss: 0.845292] [G loss: 2.265598] [D real: 0.802860] [D fake: 0.385311]
[Epoch 45/50] [Batch 899/938] [D loss: 0.902106] [G loss: 2.050767] [D real: 0.793865] [D fake: 0.394070]
[Epoch 46/50] [Batch 299/938] [D loss: 0.775542] [G loss: 1.365795] [D real: 0.687847] [D fake: 0.196163]
[Epoch 46/50] [Batch 599/938] [D loss: 0.697465] [G loss: 1.983589] [D real: 0.843698] [D fake: 0.332088]
[Epoch 46/50] [Batch 899/938] [D loss: 0.925736] [G loss: 1.990964] [D real: 0.757284] [D fake: 0.314272]
[Epoch 47/50] [Batch 299/938] [D loss: 0.915572] [G loss: 0.853581] [D real: 0.599163] [D fake: 0.172304]
[Epoch 47/50] [Batch 599/938] [D loss: 0.809719] [G loss: 2.042508] [D real: 0.859574] [D fake: 0.436016]
[Epoch 47/50] [Batch 899/938] [D loss: 0.823716] [G loss: 2.142160] [D real: 0.778661] [D fake: 0.324191]
[Epoch 48/50] [Batch 299/938] [D loss: 0.913445] [G loss: 1.654897] [D real: 0.653497] [D fake: 0.254123]
[Epoch 48/50] [Batch 599/938] [D loss: 0.686823] [G loss: 2.443697] [D real: 0.748190] [D fake: 0.237947]
[Epoch 48/50] [Batch 899/938] [D loss: 0.918376] [G loss: 1.329718] [D real: 0.659142] [D fake: 0.210957]
[Epoch 49/50] [Batch 299/938] [D loss: 1.088778] [G loss: 1.547866] [D real: 0.574101] [D fake: 0.215879]
[Epoch 49/50] [Batch 599/938] [D loss: 0.858425] [G loss: 1.300929] [D real: 0.698450] [D fake: 0.276681]
[Epoch 49/50] [Batch 899/938] [D loss: 1.208253] [G loss: 2.096180] [D real: 0.777272] [D fake: 0.505027]
模型效果展示
刚开始训练时输出的图像

50个迭代后输出的图像

总结与心得体会
GAN是一个非常有趣的网络,它使用了一个非常简直的二分类器来做判别器,然后使用一个输入与输出相同的模型来做生成器。生成器会学习到给定的数据中的分布情况,从而模拟出与给定数据同样的分布,作为生成器的输出。
经过50个轮次的运行,图像竟然真的可以开始输出一些和原始图像非常相似的结果,让我感觉非常的不可思议。从计算机其它领域获得一些概念,然后融入到人工智能中,有时候会有非常不错的结果。

















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









