




 本文详细描述了在YOLOv5模型基础上,对C2模块进行深度修改的过程,包括结构调整、代码实现、配置文件修改以及解决训练时遇到的问题,最终成功训练出新的模型版本。
本文详细描述了在YOLOv5模型基础上,对C2模块进行深度修改的过程,包括结构调整、代码实现、配置文件修改以及解决训练时遇到的问题,最终成功训练出新的模型版本。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
上次已经做了一个对YOLOv5的魔改任务,这次继续魔改。使用的素材还是之前说到的C2模块,但这次会对模型进行范围更大的修改
任务
将原模型修改为新模型
原模型如图:

新模型如图:

任务拆解
首先分析两个模型之间的改动有哪些
- 第4层的C3*2修改为了C2*2
- 第6层的C3*3修改为了C3*1
- 移除了第7层的卷积
- 移除了第8层的C3*1
其中C2模块是由C3模块修改而来,在之前的博客中也提到过,这里贴下图
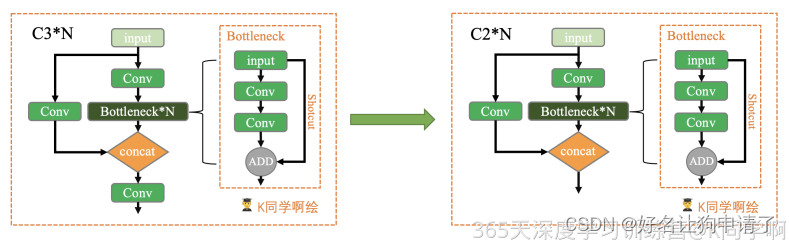
开始修改
C2模块
首先还是要先编写一个C2模块。打开models/common.py在class C3附近新建一个我们的C2模块
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C2(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_1 = c2 // 2
c_2 = c2 - c_1
self.cv1 = Conv(c1, c_2, 1, 1)
self.cv2 = Conv(c1, c_1, 1, 1)
self.m = nn.Sequential(*(Bottleneck(c_2, c_2, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1)
修改yolo.py
修改yolo.py中函数parse_model中的代码,使模型支持我们刚写的C2模块
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{
'':>3}{
'from':>18}{
'n':>3}{
'params':>10} {
'module':<40}{
'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2765
2765




 到【灌水乐园】发言
到【灌水乐园】发言







