




表
只拷贝表结构,不拷贝表数据
CREATE TABLE ruozedata_emp2 LIKE ruozedata_emp;
show create table xxx(表名);可看到表结构
拷贝表数据
Create Table As Select (CTAS)
create table ruozedata_emp3 as select empno,ename,deptno from ruozedata_emp;
可解决需求:天粒度,今天统计的是昨天的,统计结果写到一个tmp表里面
改表名,路径的名称也改了
ALTER TABLE 老表 RENAME TO 新表;
ALTER TABLE ruozedata_emp3 rename to ruozedata_emp3_bak;
Drop Table 删表跑路
DROP TABLE table_name ruozedata_emp3_bak;
Truncate Table XXX 删表的数据
trash 删除移动到此垃圾桶,需配置
内部表和外部表
metadata: TBL_TYPE
data: Table Type
MANAGED_TABLE 内部表
DROP : data + metadata X
EXTERNAL_TABLE 外部表
DROP: metadata X HDSF √
删除内部表会把数据和元数据都删除,而删除外部表只删除元数据。
从安全各方面出发,生产上使用外部表。
创建外部表
配路径
CREATE EXTERNAL TABLE emp_external(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/d7_externel/emp/' ;
Load加载数据
create table ruozedata_dept(
deptno int,
dname string,
loc string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath '/home/hadoop/data/dept.txt' into table ruozedata_dept;
load data inpath 'hdfs://hadoop000:8020/wc/dept/dept.txt' into table ruozedata_dept;
LOAD DATA [LOCAL] INPATH '' [OVERWRITE] INTO TABLE XXX;
LOCAL:从本地系统 linux服务器
不带LOCAL: 从Hadoop文件系统 HDFS
OVERWRITE 数据覆盖
不带OVERWRITE 追加
从查询结果集导入/导出数据
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]]
select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
Writing data into the filesystem from queries 导出
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/tmp/empout'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
SELECT empno,ename FROM ruozedata_emp;
聚合函数
count max min sum avg 多进一出
select max(sal),min(sal),sum(sal),avg(sal) from xxx_emp
select deptno,avg(sal) from xxx_emp group by deptno;
出现在select子句中的字段要么出现在group by中要么出现在聚合函数中
selectXXX,case开头
when中间 XXX
end结尾 from XXX_emp;
生产上案例:
select ename,sal,
case
when sal>1 and sal<=1000 then "lower"
when sal>1000 and sal<=2000 then "just so so"
when sal>2000 and sal<=4000 then "ok"
else "high"
end
from ruozedata_emp;
order by vs sort by vs distribute by vs cluster by
order by 全局排序 1reduce X不要使用,若使用用limit
sort by 局部排序 每个reduce内是有序
set hive.mapred.mode=nonstrict;非严格模式
set hive.mapred.mode=strict;严格模式
set mapred.reduce.tasks=3;
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/tmp/sortby'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
SELECT * FROM ruozedata_emp sort by empno desc;
distribute by
按照一定的规则把数据分发到某个reducer
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/tmp/distributeby'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
SELECT * FROM ruozedata_emp
distribute by length(ename)
sort by empno ;
cluster by
==> distribute by xxx sort by xxx
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/tmp/clusterby'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from ruozedata_emp cluster by ename
Hive内置函数
length(ename)Hive里面的内置函数 build-in
show functions;
desc function length;
desc function extended length;
Hive支持insert update delete,但是不用
离线计算,用load,一定不要把hive当做RDBMS来用
date function
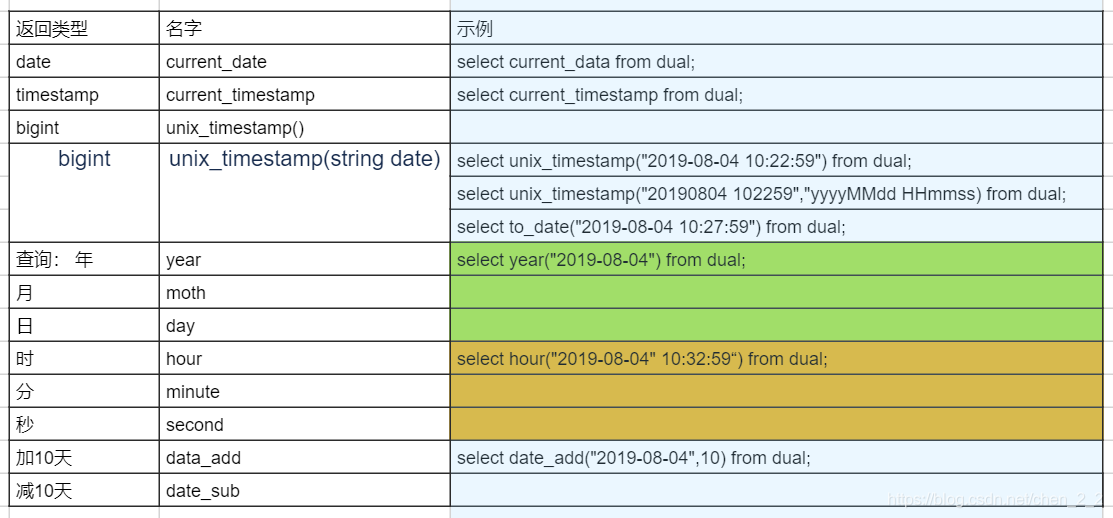
cast 转换
select cast("5" as int) from dual;
select cast("2019-08-04" as date) from dual;
select cast(current_timestamp as date) from dual;
转不成功null
数字
round(四舍五入)
select round (3.141592,4)from dual;
ceil /ceiling(往上取整)
floor(往下)
ABS(绝对值)
least(返回最小的值)
select least(3,5,6)from dual;
greatst(返回最大的值)
字符串
desc function extended substr;
select substr("abcdefg",2,3)from dual;
concat(拼起来)
concat_ws(用.点拼接起来)
案例:Hive来完成wc统计
/data/wc.data
hello hello hello
world world
welcome
hive
create table wc(sentence string);
load data local inpath ' /home/hadoop/data/wc.data' into table wc;
select * from wc;
select explode (split(sentence,'\t')))from wc;
select explode (split(sentence,'\t')))as word from wc;
hello hello hello
==> split explode 一进多出,行转列
hello
hello
hello
非严格模式下
select word,count(1) as cnt
from
(
select explode(split(sentence,'\t')) as word from wc
) t
group by word
order by cnt desc;

















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









