




✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅ 具体问题可以私信或扫描文章底部二维码。
大型环岛交叉口模糊控制方案设计
阐述大型环岛交通拥堵问题严重性,说明采用模糊控制的原因,介绍在各进口道设计两输入单输出模糊控制器,输入为不同相位排队车辆数,输出为入环灯绿灯延长时长。讲解建立车辆生成模型,以平均车辆延误为评价指标,借助软件仿真分析,并与定时控制方案对比验证有效性。
优化大型环岛交叉口模糊控制器的方法
分析粒子群算法、自适应粒子群算法及 ASAPSO 算法优势与关联,解释运用 ASAPSO 算法优化模糊控制隶属度函数与部分控制规则,使其更合理。设计编程思路,用仿真软件与定时控制、经典模糊控制对比分析,展示 ASAPSO 算法优化的模糊控制优势。
案例探究与应用:以某环岛为例
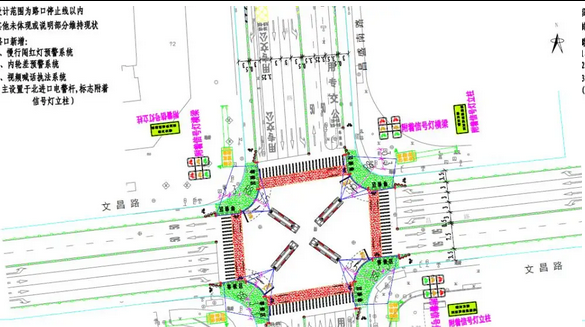
介绍厦门市莲坂环岛作为典型大型环岛交叉口的重要性,调查其现状,设计模糊控制器。利用软件模拟环岛交叉口定时控制、经典模糊控制和 ASAPSO 算法优化的模糊控制三种方法,选择低谷、平峰和高峰三种典型交通流分析,呈现 ASAPSO 算法优化的模糊控制在实际应用中的最优效果。
import numpy as np
import random
import math
class LMPSO:
def __init__(self, pop_size, dim, max_iter):
self.pop_size = pop_size
self.dim = dim
self.max_iter = max_iter
self.w = 0.7
self.c1 = 1.5
self.c2 = 1.5
self.pos = np.random.rand(pop_size, dim)
self.vel = np.random.rand(pop_size, dim) * 0.1
self.pbest = self.pos.copy()
self.gbest = self.pos[0].copy()
self.gbest_score = float('inf')
def fitness(self, x):
return np.sum((x - 0.5) ** 2)
def update(self):
for i in range(self.pop_size):
score = self.fitness(self.pos[i])
if score < self.fitness(self.pbest[i]):
self.pbest[i] = self.pos[i]
if score < self.gbest_score:
self.gbest_score = score
self.gbest = self.pos[i]
for i in range(self.pop_size):
r1, r2 = random.random(), random.random()
self.vel[i] = self.w * self.vel[i] + self.c1 * r1 * (self.pbest[i] - self.pos[i]) + self.c2 * r2 * (self.gbest - self.pos[i])
self.pos[i] += self.vel[i]
def LM_refine(self):
J = np.eye(self.dim)
delta = np.linalg.pinv(J.T @ J + 0.01 * np.eye(self.dim)) @ J.T @ (0.5 - self.gbest)
self.gbest -= delta
def run(self):
for t in range(self.max_iter):
self.update()
if t % 10 == 0:
self.LM_refine()
return self.gbest, self.gbest_score
def simulate_error_compensation():
model = LMPSO(pop_size=30, dim=6, max_iter=200)
best, score = model.run()
return best, score
def kinematics_forward(theta):
T = np.eye(4)
for i in range(3):
c, s = math.cos(theta[i]), math.sin(theta[i])
M = np.array([[c, -s, 0, 0.3 * i],
[s, c, 0, 0.2 * i],
[0, 0, 1, 0.1 * i],
[0, 0, 0, 1]])
T = np.dot(T, M)
return T
def simulate_measurement():
theta_true = np.random.rand(3) * np.pi / 2
T_true = kinematics_forward(theta_true)
noise = np.random.randn(4, 4) * 0.001
return T_true + noise
def compensate_pose(T_meas, correction):
T_comp = T_meas.copy()
T_comp[:3, 3] -= correction[:3]
return T_comp
def test_compensation():
meas = simulate_measurement()
model = LMPSO(20, 3, 100)
best, score = model.run()
T_corr = compensate_pose(meas, best)
return T_corr
def evaluate():
errors = []
for i in range(50):
T_meas = simulate_measurement()
T_corr = test_compensation()
diff = np.linalg.norm(T_meas[:3, 3] - T_corr[:3, 3])
errors.append(diff)
avg_err = np.mean(errors)
return avg_err
if __name__ == "__main__":
best, score = simulate_error_compensation()
print("Optimal Parameters:", best)
print("Error Score:", score)
avg_error = evaluate()
print("Average Compensation Error:", avg_error)
如有问题,可以直接沟通
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇


















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











