



 本文详细介绍了如何使用Python通过requests库抓取网页数据,结合BeautifulSoup解析HTML,然后将数据写入Excel文件的过程。作者分享了一个抓取基金股票涨幅数据的简单示例。
本文详细介绍了如何使用Python通过requests库抓取网页数据,结合BeautifulSoup解析HTML,然后将数据写入Excel文件的过程。作者分享了一个抓取基金股票涨幅数据的简单示例。
大家好,小编为大家解答python 爬虫抓取网页数据导出excel的问题。很多人还不知道python抓取网页数据并写入txt,现在让我们一起来看看吧!
Source code download: 本文相关源码
三年多没写博客了,原因是因为我转行了,经历了很长的低谷,那段时间从不看博客,今天打开来看,回复了一些评论,很抱歉,有些网友的评论没有及时回复。最近开始想写代码了~
最近看基金股票,想抓取一些行业当天的涨幅数据,尝试能不能在行业的波动下发现一些什么,所以想实现一个功能,就是抓取数据,然后将当天涨幅居前的行业提取出来,至于如何挖掘,这里不展开讨论一个简单又好玩的python代码。
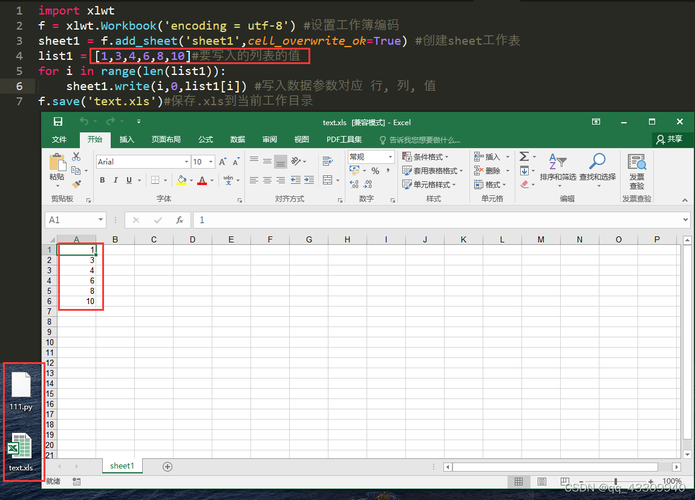
程序很简单:
第一步:
抓取网页数据
import requests
#加入headers不会出现报错
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Accept': 'text/html, application/xhtml+xml, application/xml;q = 0.9, image/webp, image/apng, */*; q = 0.8, application/signed-exchange;v = b3;q = 0.9',
'Accept-Encoding': 'gzip, deflate, br'
}
strHtml = requests.get(url, headers=headers)
html=strHtml.text第二步:抓到的是Html的数据,数据如下,我这里使用BeautifulSoup进行解析,首先需要查找Table标签,然后再遍历th表头标签,再遍历td表格内容标签
 解析Html数据,代码如下:
解析Html数据,代码如下:
for table in bf.findAll('table'): #查找所有表格
for row in table.findAll('tr'):
for th in row.findAll('th'): #查找表头table head
columnCount+=1 #计算表格总有多少列
for tr in row.findAll('td'): #查找表格肉容
curentRow=tdNumber//columnCount+1
curentColum=tdNumber%columnCount
print("第",curentRow,"行,第",curentColum,"列",tr.text)
tdNumber+=1
break第三步:解析完毕,写入Excel。
import xlsxwriter
workbook=xlsxwriter.Workbook("行数涨幅前50.xlsx")
worksheet=workbook.add_worksheet()
for table in bf.findAll('table'): #查找所有表格
for row in table.findAll('tr'):
for th in row.findAll('th'): #查找表头table head
worksheet.write(curentRow, columnCount, th.text)
columnCount+=1 #计算表格总有多少列
for tr in row.findAll('td'): #查找表格肉容
curentRow=tdNumber//columnCount+1
curentColum=tdNumber%columnCount
print("第",curentRow,"行,第",curentColum,"列",tr.text)
worksheet.write(curentRow,curentColum,tr.text)
tdNumber+=1
break
workbook.close()程序完毕,运行:

希望对你有用,共勉~

















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









