



 本文介绍了如何使用Python爬虫技术抓取今日头条的数据,包括爬虫原理、步骤、注意事项以及实战案例,展示了Python在新闻信息采集中的应用。
本文介绍了如何使用Python爬虫技术抓取今日头条的数据,包括爬虫原理、步骤、注意事项以及实战案例,展示了Python在新闻信息采集中的应用。
大家好,小编来为大家解答以下问题,python抓取今日头条中的广告,爬虫能抓取今日头条数据吗,现在让我们一起来看看吧!
随着互联网的不断发展,人们越来越习惯于获取信息的方式也在不断变化,而在这个信息爆炸的时代,要想获取最新、最有价值的信息,就需要通过一些高效、智能的工具来收集和筛选。其中,Python 作为一种强大的编程语言,不仅可以用于数据分析和机器学习等领域,还可以用于网络爬虫python必背简单代码。本文将介绍如何使用 Python 爬虫技术采集今日头条上的新闻信息。
一、Python 爬虫简介
Python 爬虫是一个自动化程序,它可以模拟人类访问网站,并自动抓取所需数据。通常情况下,爬虫会根据指定的2e9b5865537db47267991419e97f0ae9访问网站,并从 HTML 中提取所需信息。Python 爬虫有以下几个优点:
1.可以快速地抓取大量数据;
2.可以提高工作效率;
3.可以减少重复性劳动。
二、Python 爬虫原理
Python 爬虫的原理是通过 HTTP 或 HTTPS 请求获取网页源代码,然后通过解析 HTML 代码提取所需信息。常见的 Python 网络请求库有 requests 和 urllib 库。
三、Python 爬虫步骤
Python 爬虫的步骤一般包括以下几个方面:
1.发送 HTTP 请求;
2.获取网页源代码;
3.解析 HTML 代码;
4.提取所需信息;
5.存储数据。
四、今日头条网站简介
今日头条是一家中国的新闻聚合类 App,由字节跳动公司研发。今日头条通过算法推荐给用户感兴趣的新闻内容,涉及时政、财经、科技、娱乐等多个领域。因此,如果想获取最新、最全面的新闻信息,可以通过爬虫技术采集今日头条上的信息。
五、Python 爬取今日头条的实现步骤
1.安装 requests 和 BeautifulSoup 库:使用 pip install requests 和 pip install beautifulsoup4 命令安装。

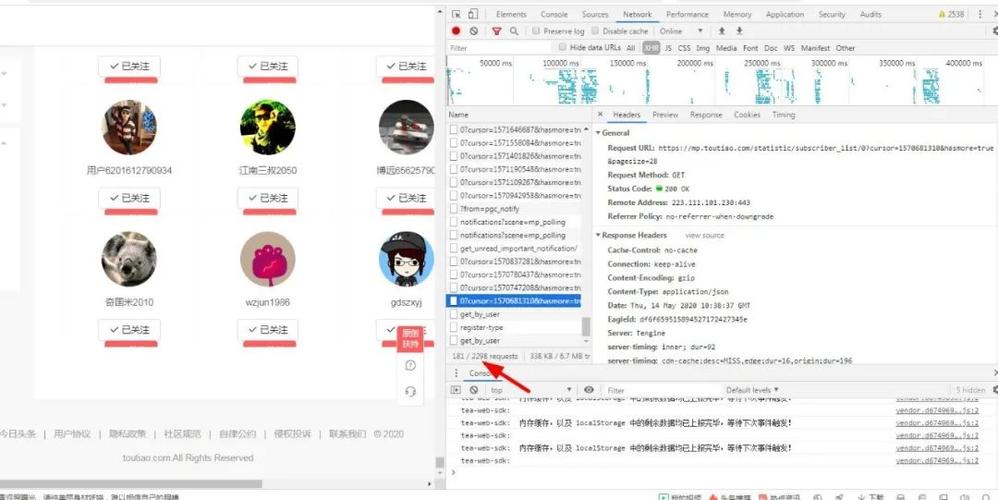
2.分析今日头条网站:打开 Chrome 浏览器,按 F12 进入开发者模式,在 Network 标签页下刷新页面,查看该网站的请求地址和响应内容。
3.编写 Python 代码:根据分析结果编写 Python 代码,实现访问 URL、获取网页源代码和解析 HTML 代码等功能。
4.运行程序:运行 Python 程序,查看是否能够正常获取所需信息。
六、Python 爬虫的注意事项
1.爬虫应该遵守网站的 robots.txt 协议,避免对网站造成不必要的影响;
2.爬虫应该设置适当的访问间隔,避免对网站造成过大的访问压力;
3.爬虫应该使用合法的手段获取信息,不得侵犯他人的合法权益。
七、Python 爬虫的优化技巧
1.设置合适的 User-Agent;
2.使用代理 IP;
3.合理选择爬取方式(如静态页面和动态页面);
4.控制数据量和速度。
八、Python 爬虫实战案例
以下是一个简单的 Python 代码示例,用于爬取今日头条上的新闻信息:
import requests
from bs4 import BeautifulSoup
url =''
headers ={
'User-Agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text,'html.parser')
news_list = soup.select('.title-box a')
for news in news_list:
print(news.text.strip())
该程序可以获取今日头条热点新闻的标题,将其打印出来。
九、总结
Python 爬虫技术可以帮助我们快速地获取互联网上的信息,今日头条作为一家新闻聚合类 App,在新闻领域具有很高的知名度。通过本文的介绍,你现在已经了解了 Python 爬虫的原理和步骤,并学会了如何使用 Python 爬虫采集今日头条上的新闻信息。在实际应用中,还需要注意遵守相关法律法规和道德规范,不得侵犯他人的合法权益。


















 2841
2841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









