




 本文探讨了轻量化网络的发展背景,重点介绍了深度可分离卷积在减少计算量和参数量方面的优势,以及MobileNetV1的结构和加速1x1卷积的方法。通过分析能耗和优化策略,展示了如何在边缘计算设备上部署低能耗模型。
本文探讨了轻量化网络的发展背景,重点介绍了深度可分离卷积在减少计算量和参数量方面的优势,以及MobileNetV1的结构和加速1x1卷积的方法。通过分析能耗和优化策略,展示了如何在边缘计算设备上部署低能耗模型。
注:仅供自己学习记录
轻量化网络
从2015年开始机器的图片分类准确率超过人眼,随着逐渐发展到了2017年准确率已经很厉害,所以轻量化网络开始被关注
轻量化网络是需要部署在一些硬件设备上的模型,他不仅需要考虑识别的准确率,还要考虑搭载设备的计算量和内存等,所以要尽可能的缩减网络所需要的的计算量和参数量。例如无人驾驶、机器人、安防摄像头等本地边缘实时计算
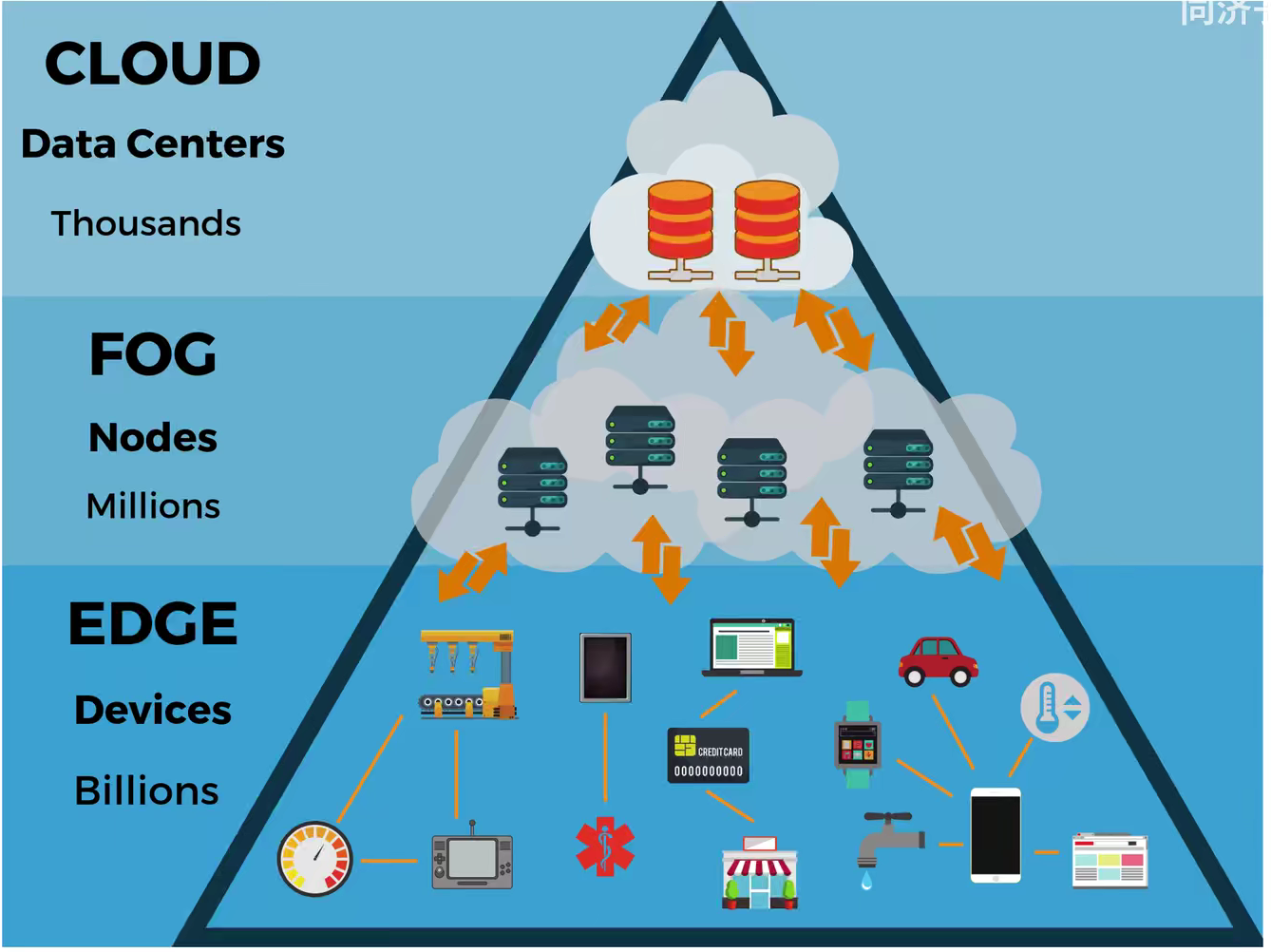
边缘计算是部署在本地,不需要实现连接云服务器的设备,设备在本地就要进行计算和得出结果,不需要网络延迟、网络传输,也可以做到保护个人隐私。同时边缘终端设备的计算力很弱,需要做到端云协同

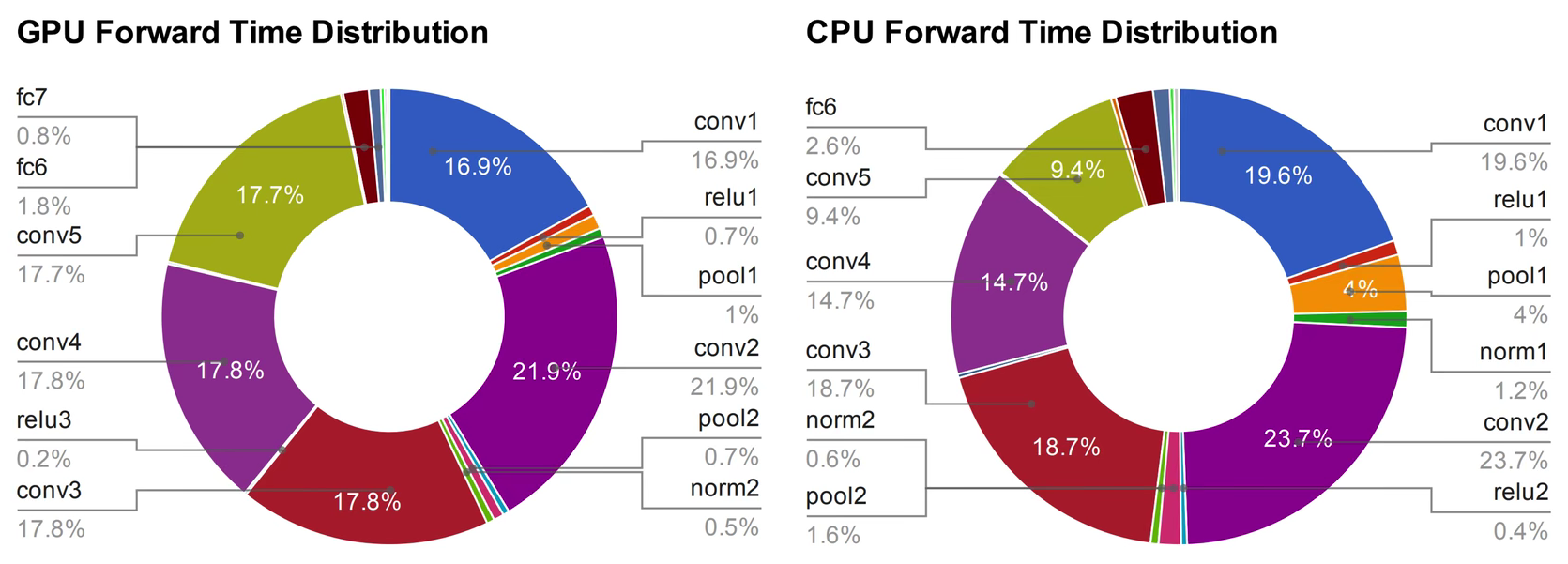
根据贾扬清的博士论文可以看到,神经网络在训练和运行时,GPU和CPU被占用最多的是卷积层的运算
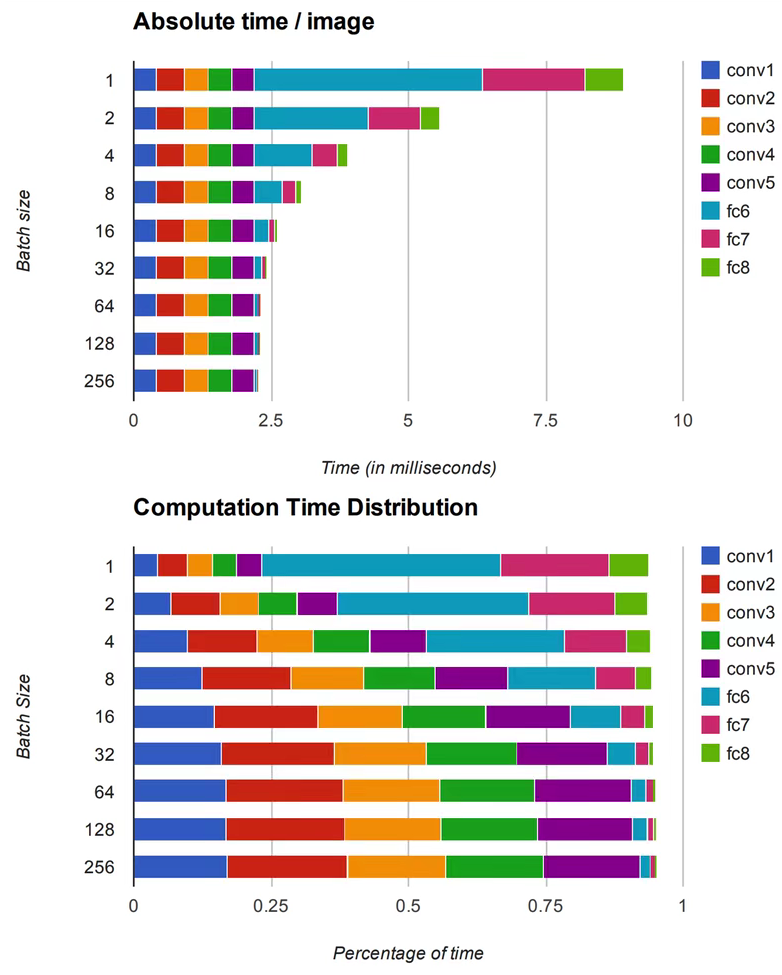
而且卷积层的运算量和时间是随着Batch Size的增大变的越来越大(全连接层的计算量后期被全局平均池化代替)
计算机的能耗去了哪里?
从下图表中我们可以看到,加法的能耗最少,乘法的能耗是加法的4-5倍,读取内存的能耗最高,是前面两种操作的几百倍
图中也有读取内存的步骤,过度读取会导致能量消耗,浪费电能是一方面,另一方面会导致芯片的散热,所以要减少能耗
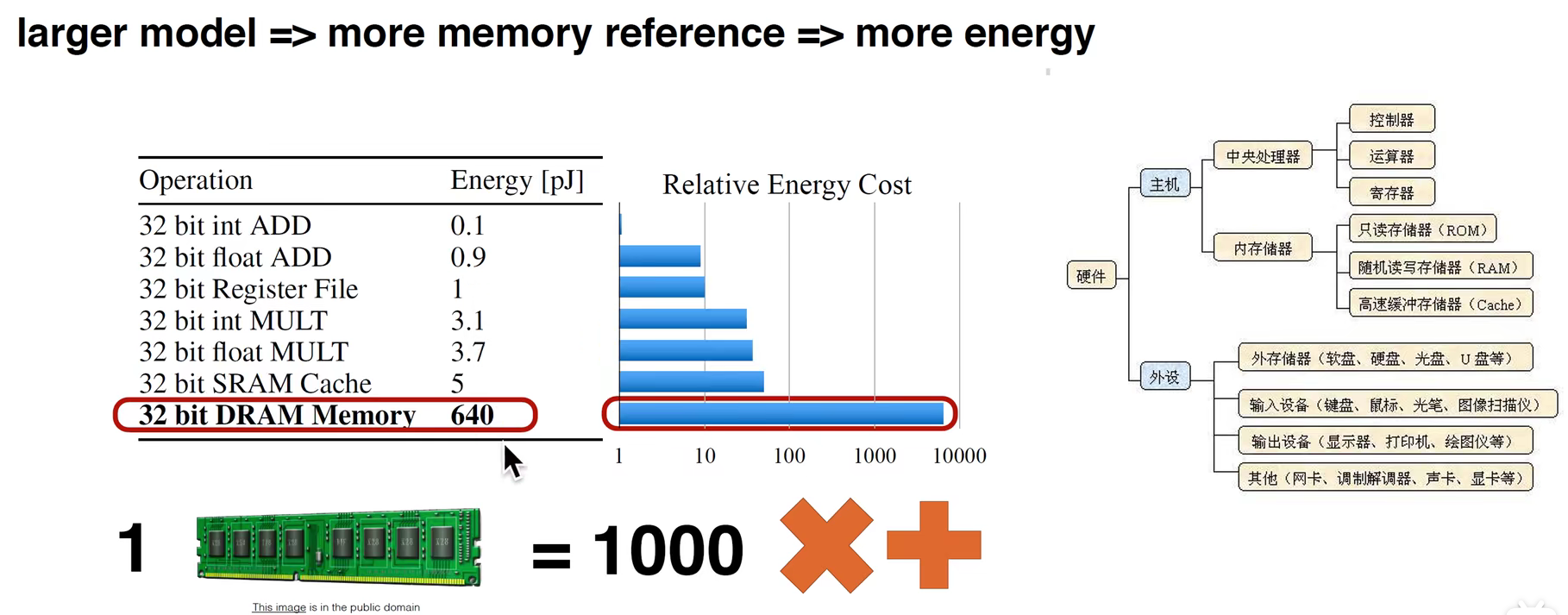
节省能耗可以通过减少参数量、调整结构(让结构更规则)等方式来实现
轻量化网络可以分为四个方面进行学习
从参数量、计算量、内存访问量、耗时、能耗、碳排放、CUDA加速、对抗学习角度分析
1)压缩已训练好的模型:知识蒸馏、权值量化、剪枝(权重剪枝和通道剪枝)、注意力迁移
2)直接训练轻量化网络:SqueezeNet、MobileNetV1、V2、V3、ShuffleNet、Xception、EfficientNet、NasNet、DARTS
3)加速卷积运算:im2col+GEMM、Winograd、低秩分解
4)硬件部署:TensorRT、Jetson、Tensorflow-slim、Tensorflow-lite、Openvino
轻量化网络在任何一个研究领域都可以发挥自己相应的左右,例如NLP、计算机视觉、对抗学习等
现有模型的精度、计算量和参数量展示
图中可以看到不同模型结构的不同指标,图像中左上角的模型相对精度和参数量更小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1518
1518




 到【灌水乐园】发言
到【灌水乐园】发言







