



 本文详细介绍如何使用F12工具抓取有道翻译的POST请求,解析FormData数据,包括sign、ts、bv、salt等参数的生成原理,并用Python实现加密过程,最终通过爬虫获取翻译结果。
本文详细介绍如何使用F12工具抓取有道翻译的POST请求,解析FormData数据,包括sign、ts、bv、salt等参数的生成原理,并用Python实现加密过程,最终通过爬虫获取翻译结果。
第一步:
打开 http://youdao.fanyi.com/ 按F12工具进行抓包监察
我们需要点击Network 勾选Preserve log 高亮XHR

现在我们尝试在翻译区输入翻译内容
我们发现抓取了一条POST请求的内容

点击此项,然后点击Preview查看是不是我们需要的内容

确认无误后我们点击 Headers 查看相关内容

这是我们实际向服务器请求的网站,浏览器中显示的是经过修改的。
拉到 Headers 最下面我们得到了Form Data数据
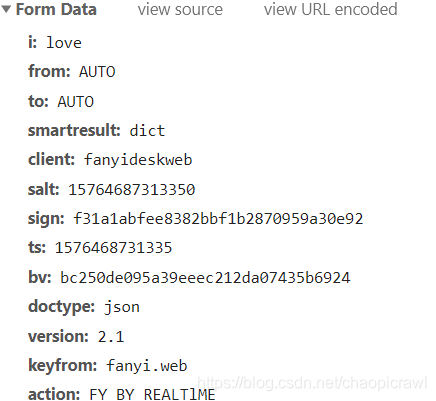
此时我们再进行一次新的翻译查看 Form Data内容
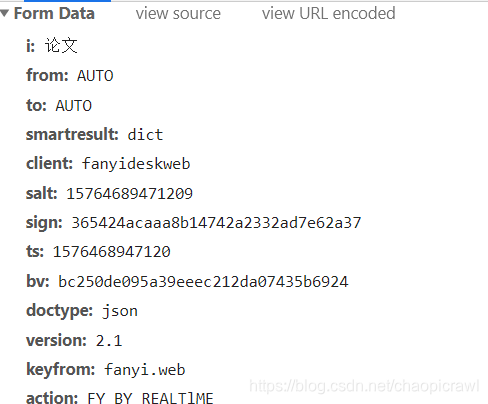
我们观察到只有 sign、 ts、 bv、 salt、 i 这5个内容是不相同的。
目前我们只知道 i 是我们要翻译的内容
第二步:
回到F12工具,点击右上方三个点的工具菜单,然后点击
search
之后我们在搜索器中搜索 sign 关键词得到一条内容,点击此内容

之后会跳转到代码的位置

此时我们将内容复制到 json网站进行格式化
http://www.bejson.com/
点击左下方深蓝色的按钮进行格式化
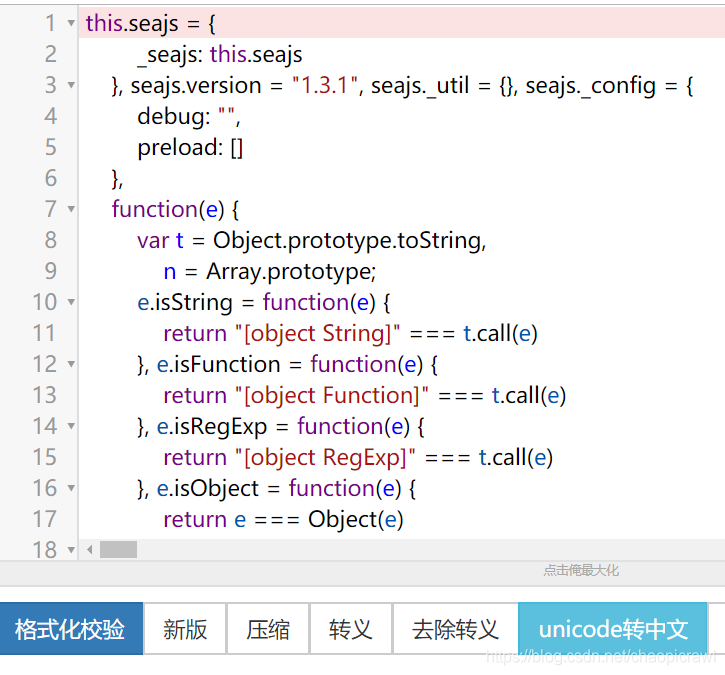
第三步:
我们将上述代码复制到python的 IDLE 文件下进行搜索
有非常多的搜索结果,我们只需要最后返回的值即可搜索内容如上图所示
从这里我们观察到
ts 对应的值是 r 而 r的值则是时间截(从1970到现在的总秒数 利用python的time()方法即可得到)

salt 对应的值是 i 而 i 的值则是在 r
的基础上随机加一个 1,10 的随机数

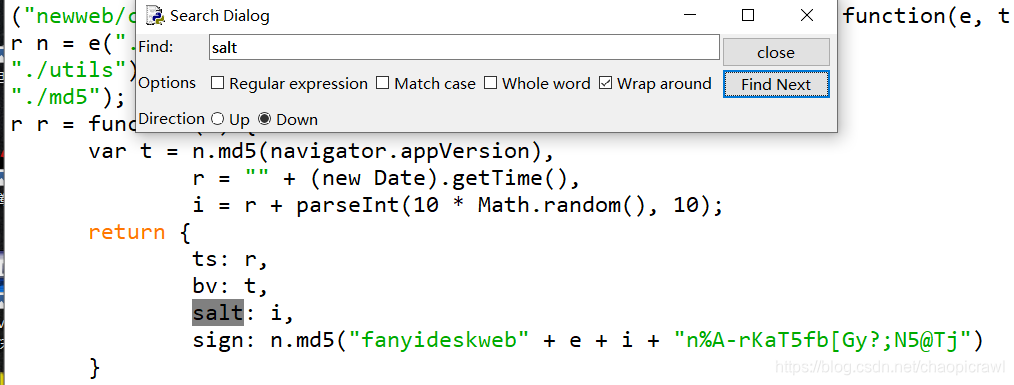
bv 对应的值则是 t 而t 的值是用户请求网站浏览器的版本号(就是请求头 User-Agent),只是将版本号进行了md5 的加密。
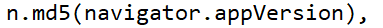
sign 的值则是将上述的内容全部加在一起然后进行md5加密
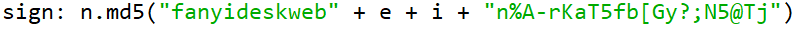
其中 e 则是我们翻译的内容
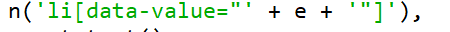 输入 e 搜索 即可得到
输入 e 搜索 即可得到
第四步:
将得到的数据进行爬虫编译
首先是设置请求头,将爬虫伪装成普通浏览器
'User-Agent':ua.random,
'Referer':'http://fanyi.youdao.com/', #维持对话 保持cookies
}
此外为了避免多次请求翻译,使得cookies多次变换,我们还需要将会话一直维持
```python
s = requests.session() #维持对话 保持cookies
将得到的加密数据变回python代码
ts = str(int(time.time()*1000))
salt = ts + str(random.randint(0,10))
bv = hashlib.md5(ua.random.encode('utf-8')).hexdigest()
sign = hashlib.md5(("fanyideskweb" + key + salt + "n%A-rKaT5fb[Gy?;N5@Tj").encode('utf-8')).hexdigest()还需要将得到的 Form Data数据输入进去
data = {}
data['i'] = key,
data['smartresult'] = 'dict',
data['doctype'] = 'json'
data['version'] = '2.1',
data['client'] = 'fanyideskweb',
data['keyfrom'] = 'fanyi.web',
data['action'] = 'FY_BY_REALTlME'
data['from'] = 'AUTO',
data['to'] = 'AUTO',
data['ts'],data['bv'],data['salt'],data['sign'] = get_jiami(key)
最后我们只需要将爬取的进行帅选即可
re = s.get("http://fanyi.youdao.com/", headers=headers) #维持对话 保持cookies
#key = input('请输入要翻译的内容:').strip()
key = v1.get()
response = s.post(url=url, data=param(), headers = headers)
#显示
msg = response.json().get('smartResult')
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









