




创建Tensor
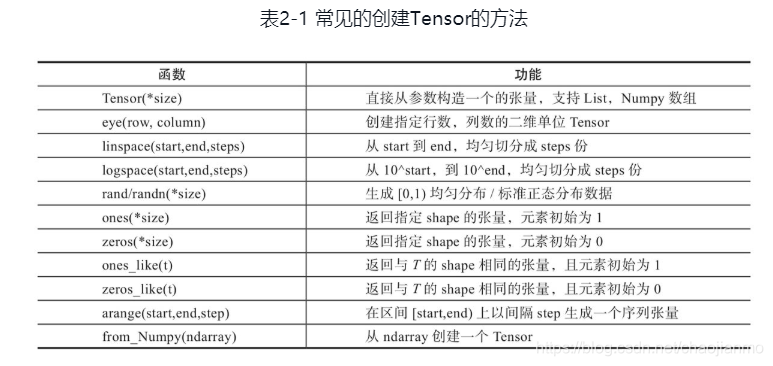
修改Tensor形状
a = torch.randn(3,4)
print(a.size()) # torch.Size([3, 4])
print(torch.numel(a)) # 12
b=a.reshape(1,12)
print(b) # tensor([[ 0.1468, 1.4984, 0.9745, 1.0549, 0.8109, 0.2764, 0.3781, 0.4406, -0.0944, -1.4848, 0.5557, 0.5034]])
c=a.view(1,12)
print(c) # tensor([[ 0.1468, 1.4984, 0.9745, 1.0549, 0.8109, 0.2764, 0.3781, 0.4406, -0.0944, -1.4848, 0.5557, 0.5034]])
索引操作

torch.masked_select()

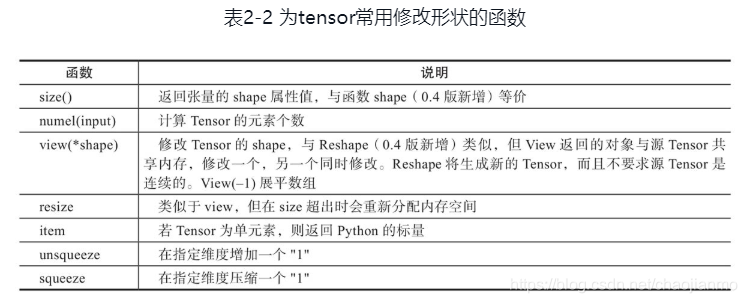
torch.nonzero()
torch.gather()
index的大小就是输出的大小,dim=1,也就是横向,那么索引就是列号;dim=0,也就是纵向,那么索引就是行号。
b = torch.Tensor([[1,2,3],[4,5,6]])
print b
index_1 = torch.LongTensor([[0,1],[2,0]])
index_2 = torch.LongTensor([[0,1,1],[0,0,0]])
print torch.gather(b, dim=1, index=index_1)
print torch.gather(b, dim=0, index=index_2)
---------------------------------------------------
1 2 3
4 5 6
[torch.FloatTensor of size 2x3]
1 2
6 4
[torch.FloatTensor of size 2x2]
1 5 6
1 2 3
[torch.FloatTensor of size 2x3]
torch.scatter_()
>>> x = torch.rand(2, 5)
>>> x
0.4319 0.6500 0.4080 0.8760 0.2355
0.2609 0.4711 0.8486 0.8573 0.1029
[torch.FloatTensor of size 2x5]
'''
LongTensor的shape刚好与x的shape对应,也就是LongTensor每个index指定x中一个数据的填充位置。
dim=0,表示按行填充,主要理解按行填充。举例LongTensor中的第0行第2列index=2,表示在第2行(从0开始)
进行填充填充,对应到zeros(3, 5)中就是位置(2,2)。所以此处要求zeros(3, 5)的列数要与x列数相同,
而LongTensor中的index最大值应与zeros(3, 5)行数相一致。
'''
>>> torch.zeros(3, 5).scatter_(0, torch.LongTensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]]), x)
0.4319 0.4711 0.8486 0.8760 0.2355
0.0000 0.6500 0.0000 0.8573 0.0000
0.2609 0.0000 0.4080 0.0000 0.1029
[torch.FloatTensor of size 3x5]
'''
同上理,可以把1.23看成[[1.23], [1.23]]。此处按列填充,LongTensor中的index=2对应zeros(2, 4)的(0,2)位置。
'''
>>> z = torch.zeros(2, 4).scatter_(1, torch.LongTensor([[2], [3]]), 1.23)
>>> z
0.0000 0.0000 1.2300 0.0000
0.0000 0.0000 0.0000 1.2300
[torch.FloatTensor of size 2x4]
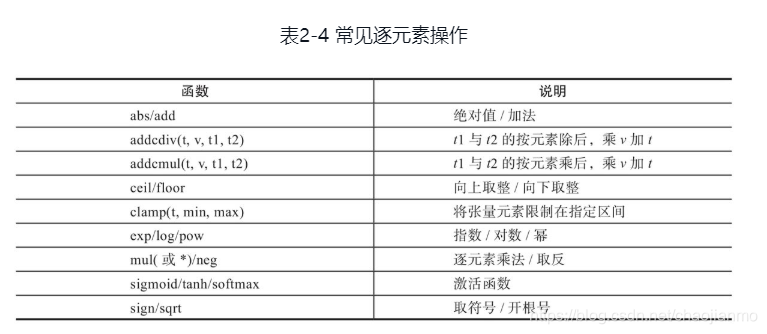
逐元素操作
- 输入与输出的形状相同
- 归并操作
对输入进行归并或合计等操作,这类操作的输入输出形状一般并不相同,而且往往是输入大于输出形状。
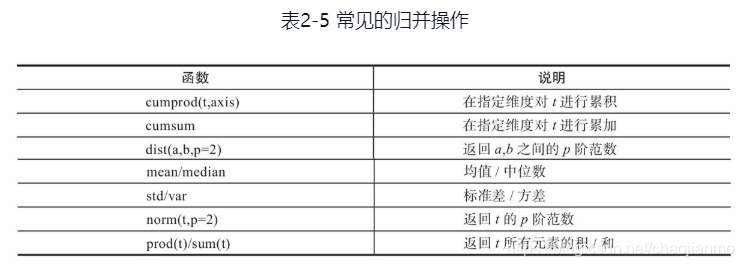
归并操作一般涉及一个dim参数,指定沿哪个维进行归并。另一个参数是keepdim,说明输出结果中是否保留维度1,缺省情况是False,即不保留。

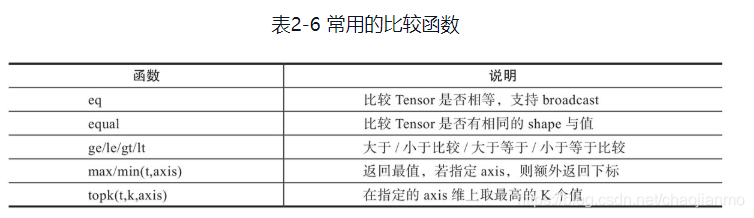
- 比较操作
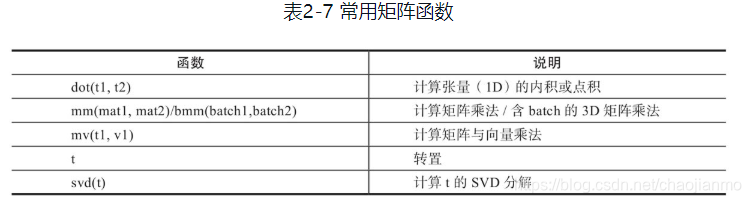
- 矩阵操作
【说明】
1)Torch的dot与Numpy的dot有点不同,Torch中的dot是对两个为1D张量进行点积运算,Numpy中的dot无此限制。
2)mm是对2D的矩阵进行点积,bmm对含batch的3D进行点积运算。
3)转置运算会导致存储空间不连续,需要调用contiguous方法转为连续。
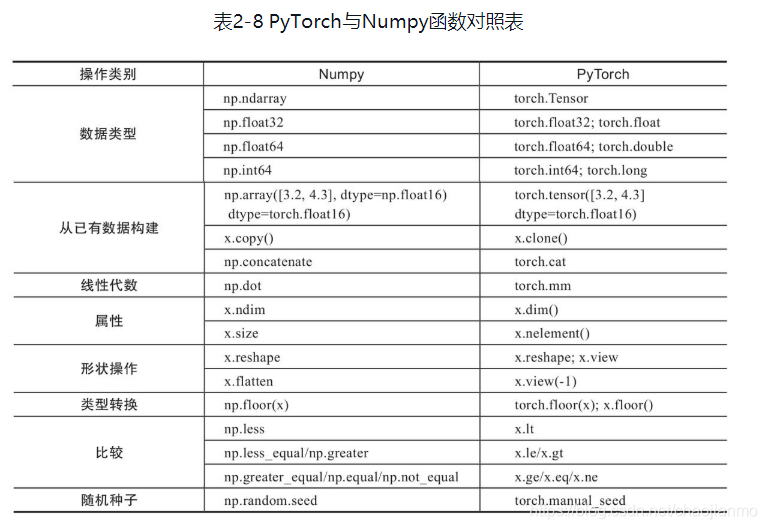
PyTorch与Numpy比较


















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









