




 本文介绍了一种在二叉搜索树(BST)中寻找指定节点中序遍历后继节点的有效算法。通过利用BST的特性,即左子树的所有节点值小于根节点,而右子树的所有节点值大于根节点,我们可以在O(h)的时间复杂度内找到目标节点的后继节点,其中h是树的高度。算法的核心思想是在BST中进行类似于二分查找的操作,遇到比目标节点值大的节点则记录下来并转向其左子树,遇到小于等于目标节点值的节点则直接转向其右子树,直到找到最后一个比目标节点大的节点。
本文介绍了一种在二叉搜索树(BST)中寻找指定节点中序遍历后继节点的有效算法。通过利用BST的特性,即左子树的所有节点值小于根节点,而右子树的所有节点值大于根节点,我们可以在O(h)的时间复杂度内找到目标节点的后继节点,其中h是树的高度。算法的核心思想是在BST中进行类似于二分查找的操作,遇到比目标节点值大的节点则记录下来并转向其左子树,遇到小于等于目标节点值的节点则直接转向其右子树,直到找到最后一个比目标节点大的节点。
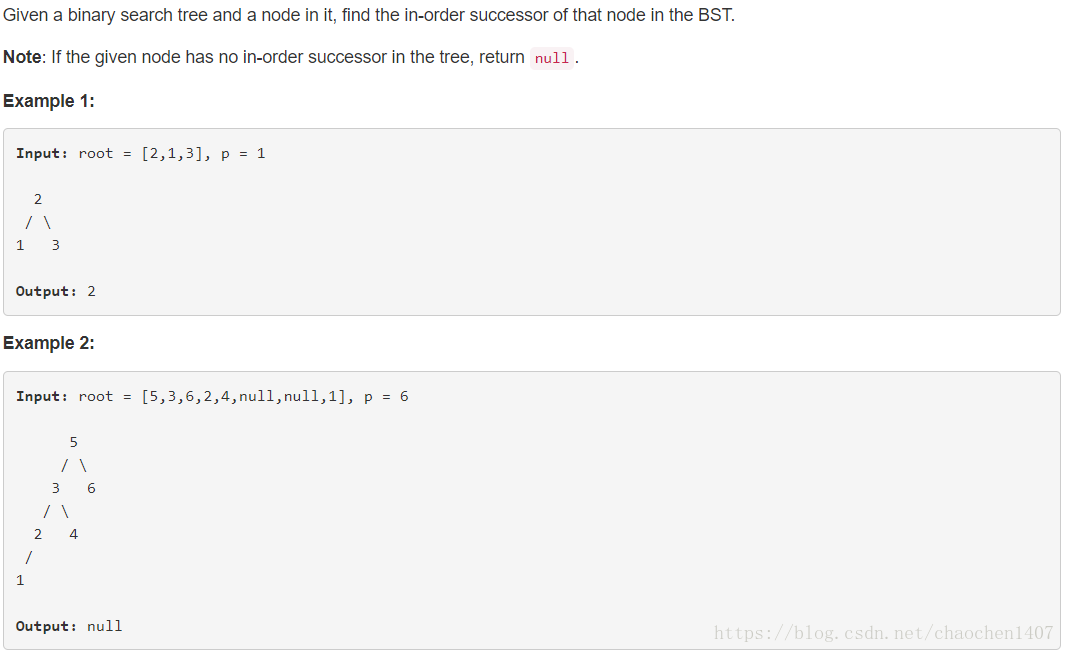
这题的第一反应其实是通过stack做dfs,然后遇到p之后的下一个就是了。可是突然想想这样做的话bst就没有意义了。所以其实可以想的更简单一点,有点像binary search。根据BST的特性,dfs inorder的下一个其实就是这颗树里面仅仅比它大的那个节点。所以其实就是遇到比P大的就记录下来然后往左走,小于等于P的就往右走但不记录,这样走到底在途中最后被记录的就是要找的那个点。根据这段算法,可以得到代码如下:
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
TreeNode result = null;
while (root != null) {
if (root.val > p.val) {
result = root;
root = root.left;
} else {
root = root.right;
}
}
return result;
}

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









