




 本文介绍了K-Means聚类算法,详细讲解了KMeans类的主要函数,并通过TensorFlow实现K-means对MNIST手写体数字数据集进行分类,展示了实际应用中的效果。
本文介绍了K-Means聚类算法,详细讲解了KMeans类的主要函数,并通过TensorFlow实现K-means对MNIST手写体数字数据集进行分类,展示了实际应用中的效果。
文章目录
一、K-means简介
K-Means算法是经典的无监督的聚类算法,其思想是对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
算法流程图下:
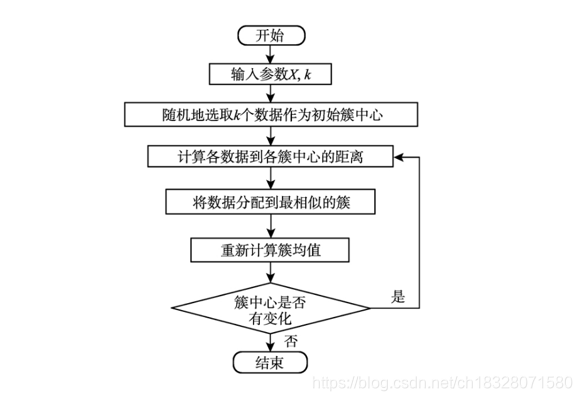
更多理论知识请参考:K均值(K-means)聚类算法。
二、主要函数
1、KMeans():
用于创建一个Kmeans算法的对象,定义如下:
from tensorflow.contrib.factorization import KMeans
KMeans(
inputs,
num_clusters,
initial_clusters=RANDOM_INIT,
distance_metric=SQUARED_EUCLIDEAN_DISTANCE,
use_mini_batch=False,
mini_batch_steps_per_iteration=1,
random_seed=0,
kmeans_plus_plus_num_retries=2,
kmc2_chain_length=200
)
参数:
- inputs:输入张量或输入张量列表。假设数据点先前已被随机置换。
- num_clusters:一个整数张量,指定簇的数量。如果initial_clusters是张量或numpy数组,则忽略此参数。
- distance_metric:用于群集的距离度量。支持的选项:“squared_euclidean”,“cosine”。
- use_mini_batch:如果为true,请使用小批量k-means算法。
- mini_batch_steps_per_iteration:更新的集群中心同步回主副本的步骤数。
2、kmeans.training_graph():
该函数用于构建图模型,定义如下:
(all_scores,cluster_idx,scores,cluster_centers_initialized,cluster_centers_vars,init_op,training_op)=kmeans.training_graph()
#注意这里的 all_scores cluster_idx scores 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









