



spring-data-jpa事务使用注意事项
一、目的
记录使用jpa的过程中遇到的问题。
使用的组件:
spring-data-jpa
maven信息;
<!-- spring-data-jpa -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- blaze-persistence -->
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-core-api</artifactId>
<version>1.6.6</version>
</dependency>
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-core-impl</artifactId>
<version>1.6.6</version>
</dependency>
<!-- Hibernat -->
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-5.4</artifactId>
<version>1.6.6</version>
</dependency>
blaze-persistence官方文档地址:
https://persistence.blazebit.com/documentation/1.2/core/manual/en_US/index.html
我是从mybatis开始然后转到jpa,在sql的书写时,很不习惯,不太明白怎么写sql的,可以参考文章:
https://blog.youkuaiyun.com/ceshiyuan001/article/details/134548046
二、测试代码示例
maven依赖
同上,这里就不在赘述
entity
@Data
@Entity
@AllArgsConstructor
@NoArgsConstructor
@DynamicUpdate
@Table(name = "t_student",
uniqueConstraints = @UniqueConstraint(name = "uk_student_no", columnNames = "studentNo"))
public class StudentEntity extends BaseEntity {
/**
* 班级id
*/
@Column(columnDefinition = "BIGINT NOT NULL COMMENT '班级id'")
private Long classId;
@Column(columnDefinition = "VARCHAR(12) NOT NULL COMMENT '学生姓名'")
private String studentName;
private Integer testNumber;
/**
* 形象照 强烈建议存储链接类型,使用String存储,可以看后文描述
*/
private URL avatar;
}
repository
@Repository
public interface StudentRepository extends JpaRepository<StudentEntity, Long>, JpaSpecificationExecutor<StudentEntity> {
@Modifying
@Query("update StudentEntity s set s.testNumber = ?1 where s.id = ?2 and s.testNumber = ?3")
int updateTestNumberById(Integer newNumber, Long id, Integer oldNumber);
}
三、遇到的注意点(不注意就是坑)
jpa事务处理
没有save,update也能更新数据
entityManager管理数据库实体对象有4个状态:新建,托管,游离,删除。
只要是托管状态的对象,字段发生了变动,entityManager就会在事务结束时将数据的更新,更新到数据库中。@query()的写法,不会涉及到entityManager管理的实体属性变动的。
如果上面这段描述不清楚的,直接看下面的运行截图:
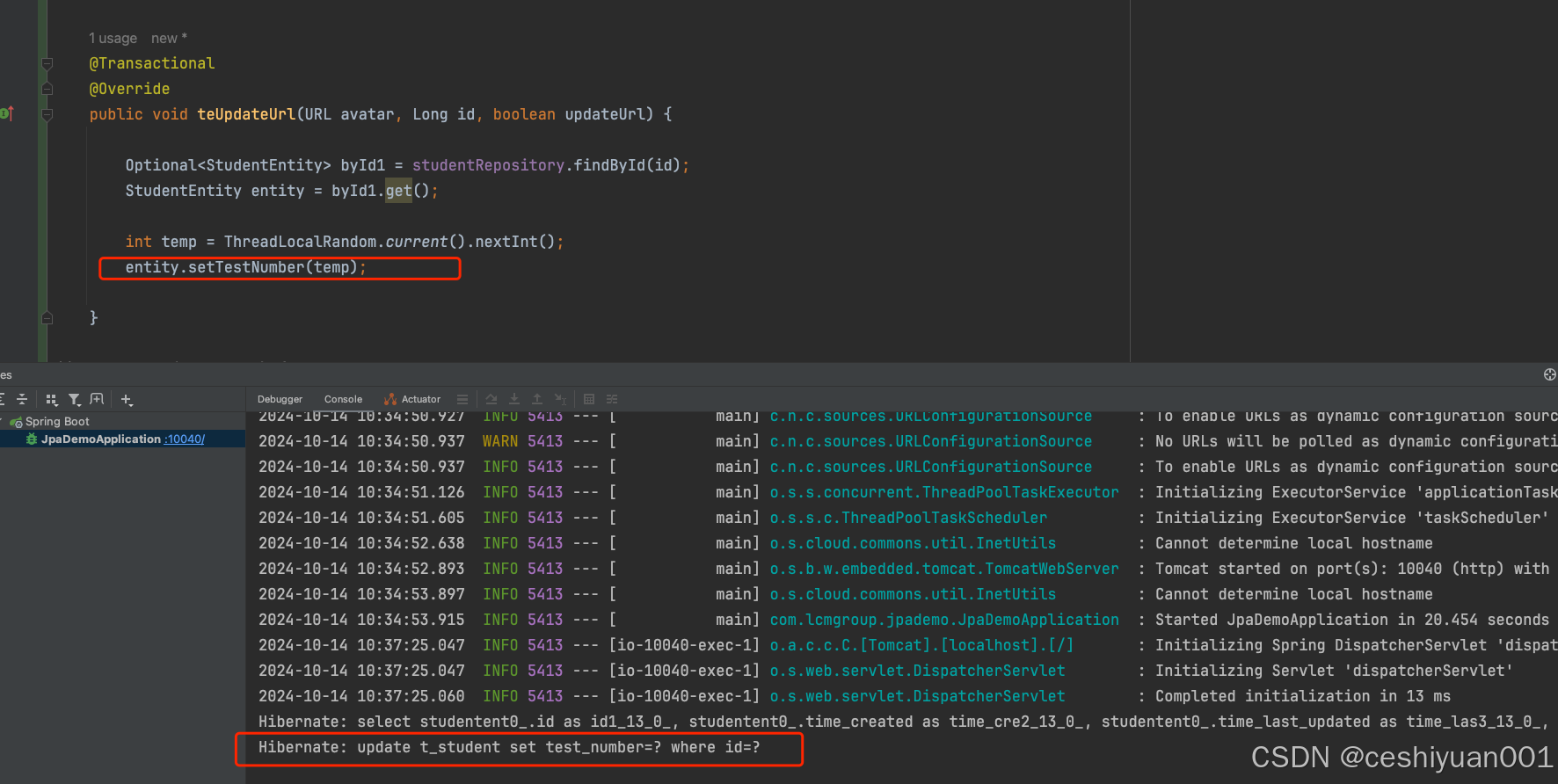
强烈建议:更新的时候用save或者其他的代码进行显示更新!!
同事物中entity对象复用并比较属性
先看代码:
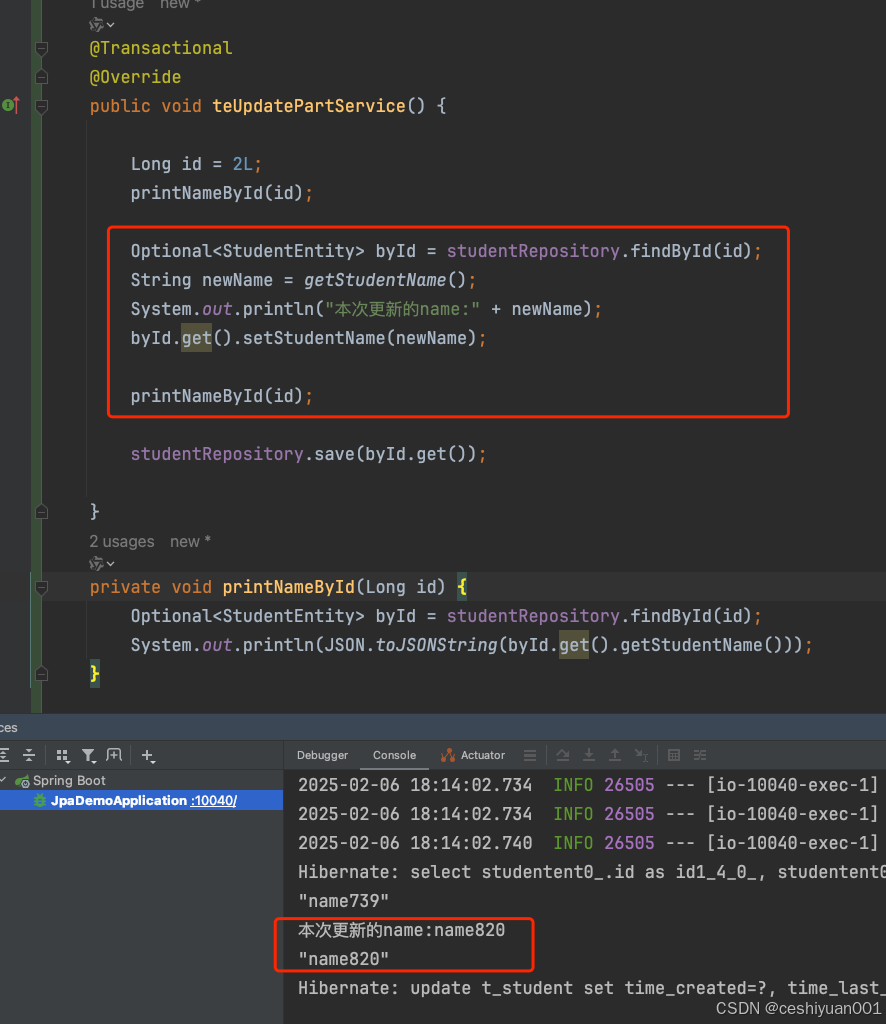
为什么第二次执行打印名称,返回的居然是更新后的数据?

JPA的持久化上下文:
在同一个事务中,JPA的持久化上下文会对实体进行缓存管理。如果你对某个实体进行了修改但尚未提交到数据库,在同一事务内后续对该实体的查询会返回已修改的状态而非数据库中的实际状态
如果要处理这个情况,推荐用新事物进行查询,比如:
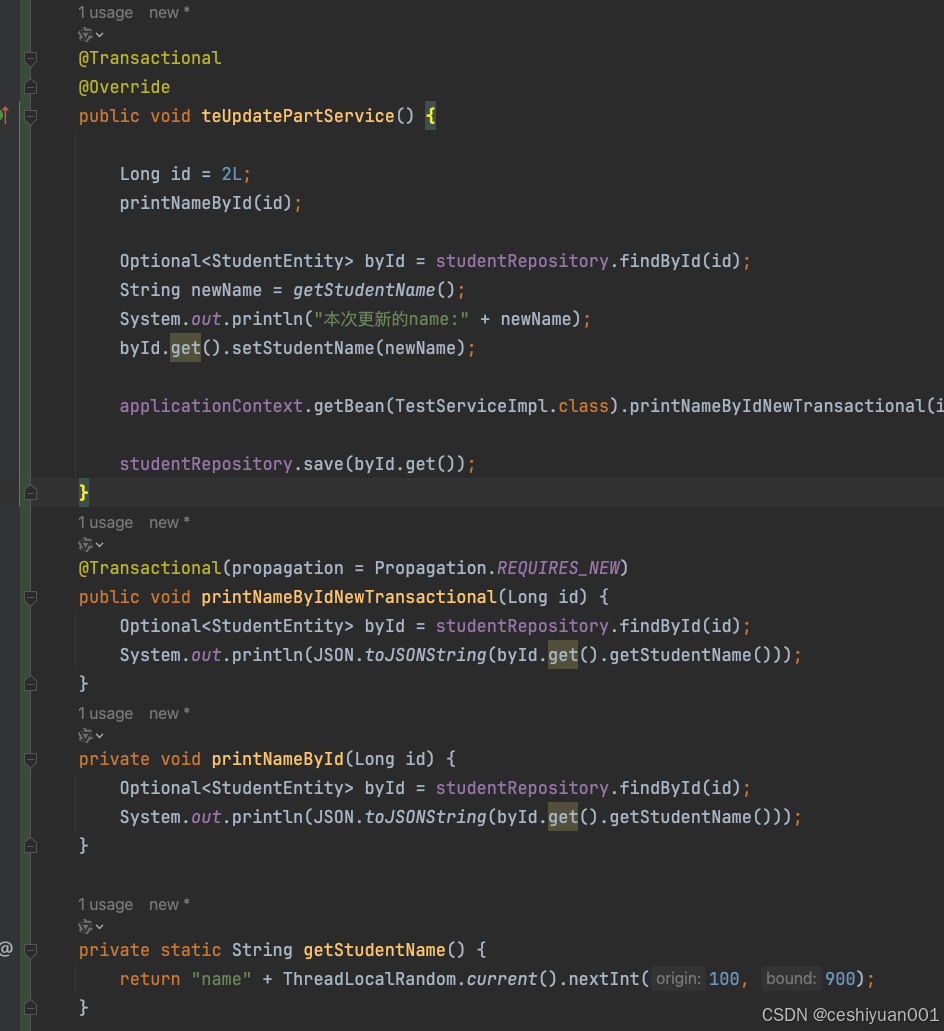
执行结果:
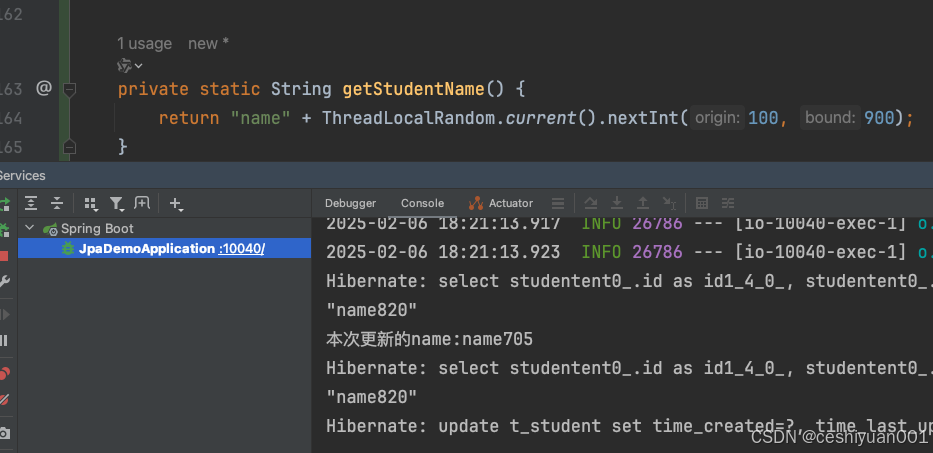
设计原因:
我指代的设计,是jpa在同一个事物中,对同一个id的entity对象任何属性修改后,然后在同一个事物中再次查询,查到的是新更新过的数据,而不是原始数据的这个设计。为什么要这么设计?
JPA 在同一个事务中对同一个 ID 的实体对象进行任何属性修改后,再次查询时会得到更新后的数据而非原始数据,这种设计主要是基于以下几个核心原则和机制:
- 持久化上下文(Persistence Context)的作用
JPA 使用持久化上下文来管理实体的状态。一旦一个实体被加载到持久化上下文中,对该实体的任何修改都会在持久化上下文中反映出来,并且这些更改在事务提交之前不会直接同步到数据库。
这种设计确保了在一个事务内,所有操作看到的都是最新的、一致的状态。它减少了由于并发访问导致的数据不一致问题。
2. 第一级缓存(First Level Cache)
持久化上下文实际上也是一个缓存层,称为第一级缓存。在这个缓存中的实体实例是共享的,即在同一个事务内的多次查询如果涉及到相同的实体实例,则返回的是同一份内存中的对象引用。
这提高了性能,因为它避免了不必要的数据库查询。此外,这也简化了应用逻辑的设计,因为开发者可以依赖于获取的对象总是最新的状态。
3. 事务的一致性视角
从数据库事务的角度来看,事务被视为一个原子操作单元,其中所有的读写操作都应该是隔离的。这意味着,在一个未提交的事务中,所有操作都应该基于该事务开始以来的一致视图。
因此,在同一个事务中对实体的修改立即可见,有助于维护这种一致性视图,确保事务内部的操作基于最新的数据状态执行。
4. 简化开发复杂度
如果每次查询都需要重新从数据库加载数据,而忽略已经在内存中的最新状态,那么这将大大增加系统的复杂性和开销。
通过使用持久化上下文和第一级缓存,JPA 提供了一种有效的方式来管理和优化数据访问模式,使得开发者能够专注于业务逻辑而不是底层的数据访问细节。
综上所述,JPA 设计为在同一个事务中对同一个 ID 的实体对象进行任何属性修改后再次查询时获得更新后的数据,主要是为了保证事务内数据的一致性视图,提高性能以及简化应用程序的开发复杂度。虽然这可能在某些场景下需要额外的处理来获取原始数据(如通过刷新或分离实体),但总体来说,这种设计符合大多数应用的需求,并提供了强大的功能支持。
通义千问回复
单条记录并发更新数据
场景,并发对t_student表中,test_number字段进行更新,要求在原来数据的基础上进行累加。
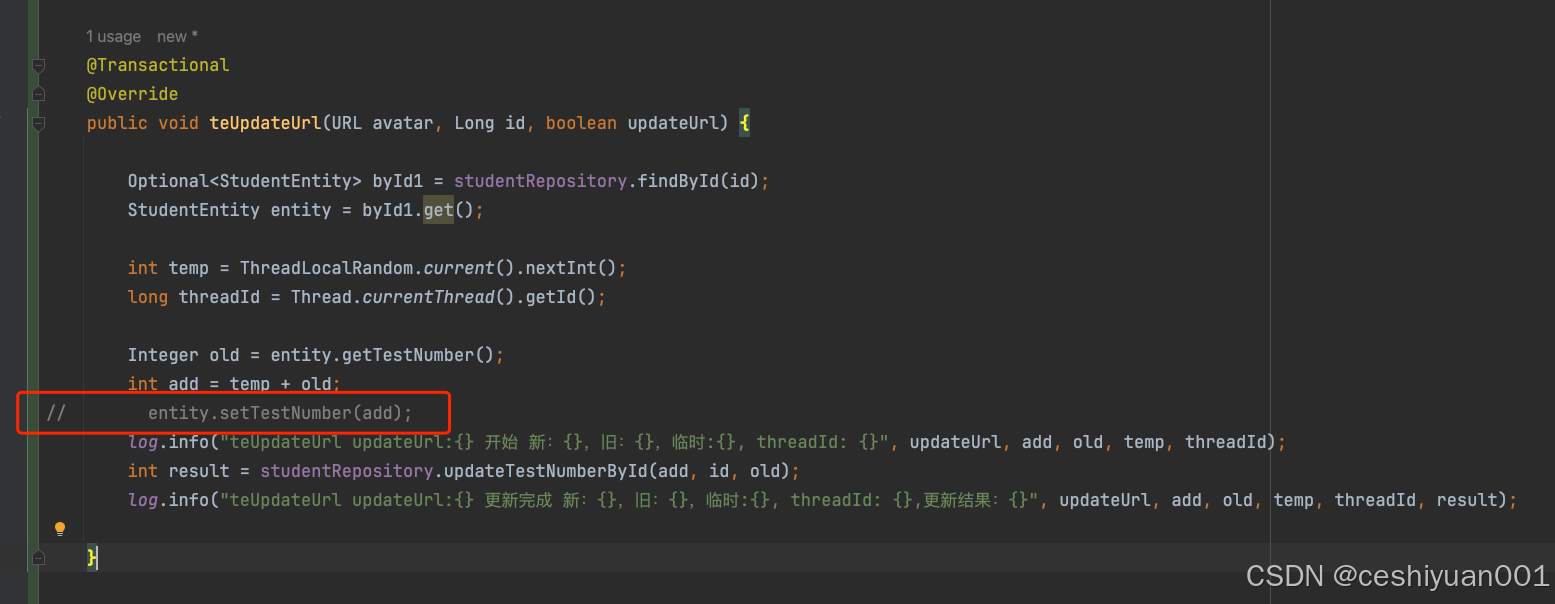
红色部分代码开启,则不管怎么执行,返回的result都是0 即没有更新到数据,但是查看数据库,数据库中的记录更新了,且会被最后一个提交事务的请求更新。原因就在上面说的entityManager的实体管理
实体对象属性有URL类型时,save不稳定
当实体对象属性有URL时,简单的save都会出现不稳定的情况。目前我还没找到问题原因,要是有大佬知道原因,可以指导一下。非常感谢!!
背景:
项目老代码中员工数据库对象,头像字段为URL类型。更新用户信息方法也是很简单,查询出来然后更新。但是在某一个环境出现了慢的情况,其余环境均没有客户反馈说慢。在本地模拟场景,也复现了这个情况。但是现象不一样。
复现信息如下:
数据库为mysql,大版本5.7,java jpa maven 依赖同上。
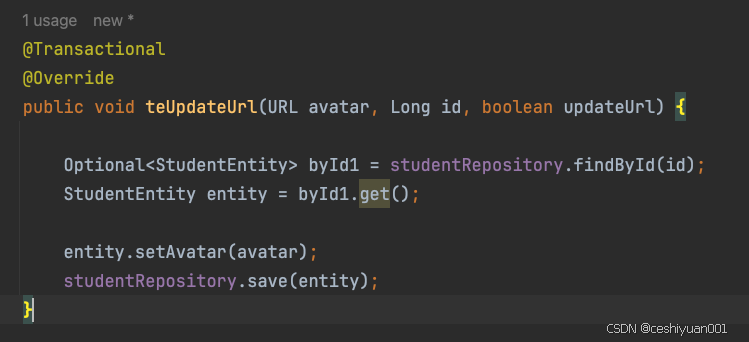
头像变化:
一直为null时,更新非常快。
从null变 a,更新慢
从a 不变,更新慢
从a变b,更新慢
从b变null,更新快
更新慢是按秒级计算的,本地慢的时候,30s都有,线上环境16s左右。
问题原因:
不详
解决方案:
因为老代码,不能直接更新URL类型为String。所以考虑的是,在更新的时候,不变化entityManager的URL类型字段。
具体解决方案,待本周四上线更新后在更新文档
没有解决,哎

















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









