




 本文深入探讨了PHP_CodeSniffer如何进行代码静态分析,主要通过词法分析将PHP源码转化为TOKEN数组。文章介绍了PHP的运行过程,详细解析了词法分析与TOKEN的概念,展示了如何基于TOKEN定制PHP_CodeSniffer规则,以及规则实现的细节。此外,还讨论了PHP_CodeSniffer的局限性和自动修复功能。
本文深入探讨了PHP_CodeSniffer如何进行代码静态分析,主要通过词法分析将PHP源码转化为TOKEN数组。文章介绍了PHP的运行过程,详细解析了词法分析与TOKEN的概念,展示了如何基于TOKEN定制PHP_CodeSniffer规则,以及规则实现的细节。此外,还讨论了PHP_CodeSniffer的局限性和自动修复功能。
导读
PHP_CodeSniffer是一个用来检查PHP代码规范的开源项目。它主要通过词法分析的方式将PHP源码解析成TOKEN数组,然后在TOKEN中标记出不符合代码规范的代码位置。
目前编程语言可以分为两大类:
第一类是像C/C++, .NET, Java之类的编译型语言, 它们的共性是: 运行之前必须对源代码进行编译,然后运行编译后的目标文件。
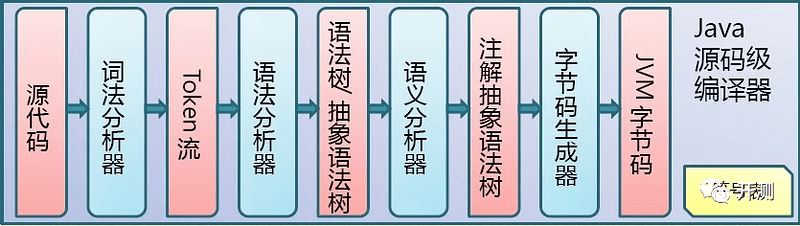
以Java举例,第一类编译的过程都是先进行词法分析、语法分析,然后才是编译。在经过语法分析之后,有一个抽象语法树(AST)的概念,算是语法分析的产出,之后的编译过程是编译器在AST基础上进行的。
第二类比如:PHP, Javascript, Ruby, Python这些解释型语言, 他们都无需经过编译即可"运行",虽然可以理解为直接运行,但它们并不是真的直接就被能被机器理解, 机器只能理解机器语言,那这些语言是怎么被执行的呢, 一般这些语言都需要一个解释器, 由解释器来执行这些源码, 实际上这些语言还是会经过编译环节, 只不过它们一般会在运行的时候实时进行编译。
以PHP举例,PHP的运行过程是怎样的呢?
1.传递给php程序需要执行的文件, php程序完成基本的准备工作后启动PHP及Zend引擎, 加载注册的扩展模块。
2.初始化完成后读取脚本文件,Zend引擎对脚本文件进行词法分析,语法分析。然后编译成opcode执行。如果安装了apc之类的opcode缓存, 编译环节可能会被跳过而直接从缓存中读取opcode执行。
TOKEN
在文章开头,我们已经知道PHP_CodeSniffer的主要原理是将PHP源码解析成TOKEN数组,同时在PHP_CodeSniffer源码中,很多操作的核心就围绕着TOKEN展开。
那么问题来了,TOKEN是什么?
PHP词法解析器在解析PHP语言的过程中,PHP 语言的不同部分在内部被表示为类似T_XXX 的类型,这个T_XXX的类型就叫TOKEN,也叫标识符。
标识符部分列表:
代号语法参考|------
PHP官网共119个标识符,查看PHP官网标识符列表
在PHP中提供了token_get_all(string $source)方法解析提供的 source 源码字符,然后使用 Zend 引擎的词法分析器获取源码中的 PHP 语言的TOKEN代号,就是上文中的T_XXX。
TOKEN代号都有对应的唯一值,比如T_ABSTRACT对应的是312,是之前定义好的。
你也可以使用PHP自带的token_name(312)方法获取TOKEN代号,示例代码如下:
<?php
// 260 is the token value for the T_EVAL token
echo token_name(260); // -> "T_EVAL"
// a token constant maps to its own name
echo token_n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}