




这两个月来,国产 AI 的发展势头可以用四个字概括:势如破竹。
上个月,智谱发布的 GLM-4.1V-Thinking 一举冲上了 HuggingFace Trending 榜首,总下载量已突破13万次。
上周,又推出了旗舰多模态模型 GLM-4.5 和轻量版 GLM-4.5-Air,技术圈瞬间沸腾。
这周,智谱再次扔下“核弹”——基于 GLM-4.5-Air 架构,训练出更强大的视觉推理模型 GLM-4.5V,并且毫不犹豫地 全量开源。
更夸张的是,在 42 个权威多模态榜单 中,GLM-4.5V 拿下了 41 项 SOTA(全球最佳)。 一句话:在开源视觉推理领域,它几乎是无敌的存在。
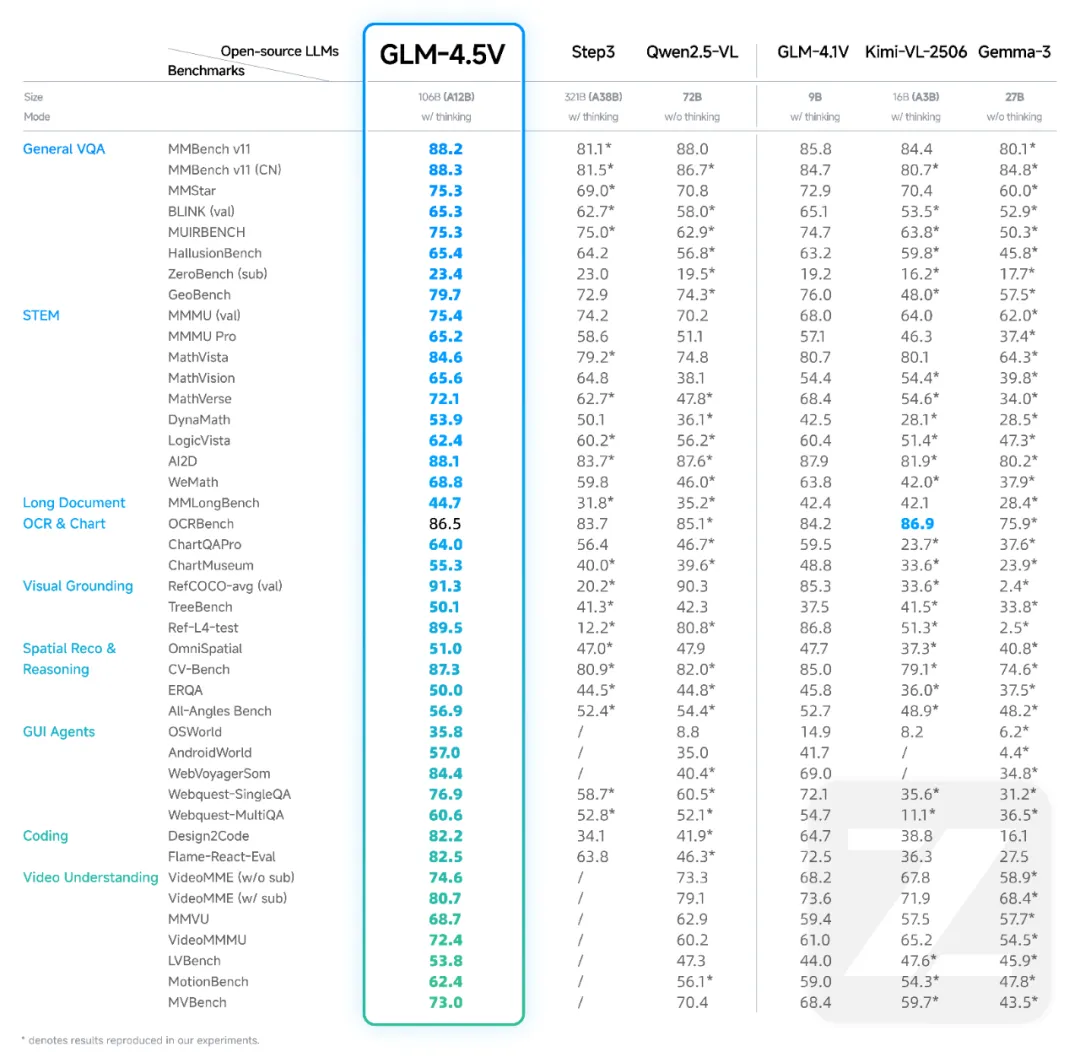
01 GLM-4.5V 究竟强在哪?
如果说普通的视觉模型只是“看得清”,那 GLM-4.5V 则是“看得懂、想得通、还会自己动手”。
它的三个核心能力,让它不只是个识图工具,而更像一个拥有视觉和常识的大脑:
① 多模态融合推理
能同时理解图像、文字、视频等多种信息,并在一个上下文中推理,这意味着它不仅能识别图片,还能结合文字背景得出更准确的结论。
类比一下,这就像一个工程师看图纸时,不仅看到了线条,还理解了设计目的,并能立即判断可行性。
② 长上下文记忆
可以连续处理数十张图片、几分钟视频或长文档,并保持逻辑一致,不会出现“前一句和后一句不沾边”的问题。 这对长流程的任务(比如视频内容分析、长文档解析)非常关键。
③ Grounding 精准定位
不只是说“这是一个猫”,而是能告诉你它在画面中的精确坐标,甚至能直接生成可用的标注文件,让 AI 从“感知”走向“可操作”。
02 模型规格:真正的 100B 级视觉推理猛兽
-
总参数:106B
-
激活参数:12B
-
输入类型:图像 / 文本 / 视频
📂 GitHub:https://github.com/zai-org/GLM-V📂 Hugging Face:https://huggingface.co/zai-org/GLM-4.5V
03 能力覆盖面有多广?
-
图像推理:场景理解、多图分析、位置识别
-
视频理解:长视频分镜、事件识别
-
GUI 任务:前端页面复刻、桌面操作辅助
-
图表与文档解析:结构化提取、自动标注
-
Grounding 定位:精准框选视觉元素
简单来说,它既能帮你看懂一份复杂的财报图表,也能复刻一个网页 UI,甚至能像人类助手一样操作电脑界面。
04 桌面助手:多模态能力落地的“利器”
为了让开发者更快上手,智谱还同步开源了 GLM-4.5V 桌面助手,支持:
-
实时截屏并分析
-
获取屏幕信息
-
基于视觉推理执行自动化任务
写在最后
从 GLM-4.1V-Thinking 到 GLM-4.5V,智谱用一波接一波的开源操作证明: 国产大模型,不只是能打,还能 打到世界第一。
未来的多模态 AI 或将超越单纯的“工具”角色,成为能够理解、推理与协作的数字伙伴。 它们正在用另一种方式,重塑我们的工作和生活。
推荐阅读:
2025年大语言模型横向评测:合规、成本和开源,企业首选是谁?从零开始打造AI测试平台:文档解析与知识库构建详解
MCP、LLM与Agent:企业AI实施的新基建设计方案
精选文章:
国产模型Qwen3-32B本地化实战:LangChain + vLLM 构建企业智能引擎
深入解析Agent实现“听懂→规划→执行”全流程的奥秘
2025大模型平台选择指南:从个人助手到企业智能体,解读五大场景
企业AI转型之战:Coze、Dify与FastGPT的巅峰对决-优快云博客
2025大语言模型部署实战指南:从个人开发到企业落地全栈解决方案-优快云博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









