




论文:https://arxiv.org/abs/1311.2524
0 摘要
RCNN在PASCAL VOC 2012检测集上mAP达到了53.3%;
两个重要的结论:
- CNN可以用来实现检测和分割任务中的目标定位;
- 训练集不足时,使用预训练模型进行微调可以获取良好的应用效果。
1 简介
目标检测任务在2010 - 2012年期间进展很少,自从2012年AlexNet在ILSVRC成功以来,大家都在讨论一个问题:CNN对ImageNet的分类结果可以在多大程度上泛化到PASCAL VOC目标检测上 ?
本文是第一篇应用CNN解决目标检测任务,并且比使用HOG特征取得了更好的效果。作者主要解决了两个问题,一是如何使用CNN定位目标,另一个是基于少量标注的检测数据如何训练一个大的模型。
作者在本文中,将检测问题当作基于区域的识别问题,取得了良好的目标检测和分割效果。其他论文尝试将目标定位问题当作回归问题处理,但是在VOC2007数据集上mAP只有30.5%,远低于本文的58.5%;作者还尝试使用基于滑动窗的检测器,但是由于作者的CNN包含五个卷积层,对输入图像而言的局部感受野为 195 ∗ 195 195*195 195∗195,stride为 32 ∗ 32 32*32 32∗32,因此无法进行目标的精确定位。作者最后使用的"基于区域的识别"做法是,对输入图像生成2000个独立的且形状任意的建议区域(region proposal),对每一个proposal使用CNN提取固定长度的特征,然后使用线性SVM对特征进行分类。因为最终的实现方案结合了region proposals和CNN,因此方法叫做R-CNN:Regions with CNN features。
R-CNN的整体处理过程为:

针对当时用于检测的数据集有限无法训练大型CNN网络的难题,作者证明了基于无监督的预训练模型进行有监督的微调的解决方案可以有效的解决数据缺乏问题。具体来说,作者是使用了在ILSVRC数据集上的预训练模型在PASCAL VOC数据集上进行微调,作者的实验表明微调将检测的mAP提升了8个百分点。
作者还提出了通过bounding box回归可以准确的实现目标定位。
2 核心思想
R-CNN包括三部分:
- 产生和类别无关的region proposal;
- 对每个区域使用CNN提取固定维度的特征;
- 使用线性SVM族进行目标分类(N个二分类的svm,判定一个图像块是否为车、是否为人…)及使用bounding box回归进行目标定位。
2.1 算法设计
Region Proposal:
Region Proposal表示图像上可能存在感兴趣目标的区域,这些区域的类别我们不关心,我们关心的只是是不是有比较特殊的目标,本文使用selective serach方法进行region proposals的生成。
Feature extraction:
对提取的proposal区域先进行16像素的扩充,然后缩放到227*227,图像归一化,使用AlexNet提取4096维特征,即下图中的方案D。作者之所以这样做是在下图所示的实验中,先对region proposal进行16像素的扩充再缩放时,mAP最高。

对于测试图像,使用selective search产生2000个proposal,进行变换送入CNN提取特征。对每个类,使用训练的SVM进行分类判别。获取了图像所有的区域的score之后,对每个类使用NMS删除高度重叠的检测框。
2.2 检测时间效率
算法很高效,一是因为所有类共用CNN参数;二是相比于其他算法提取的特征维度很小,只有4096维。每一类都要做的只有SVM分类,但计算过程也只有特征向量矩阵( 2000 ∗ 4096 2000*4096 2000∗4096)和SVM权重矩阵( 4096 ∗ N 4096*N 4096∗N)之间的矩阵乘积及NMS,计算量很小。
2.3 训练过程
微调过程:
使用在ILSVRC2012数据集上预训练的AlexNet网络模型;
使用检测训练集在预训练模型上进行微调,微调时:
- 修改网络的输出为N+1(1表示background;对VOC,N=20;对ILSVRC2013,N=200);
- 若某生成的region proposal和ground-truth bounding box之间的IOU大于等于0.5则认为是正样本,否则为负样本;正样本就标注其类别为对应的bounding box所包含的目标在VOC中的类别,负样本则标注类别为0,以此来微调特征提取模型;
- 使用SGD迭代,学习率为0.001(预训练模型训练时学习率的1/10),mini-batch大小为128,包含32个目标图像块和96个背景图像块,之所以使用 32 VS. 96,是因为背景图像远多于目标图像。
svm分类器训练:
训练车辆分类器时,如果一个图像块包含车辆则为正样本,如果只有背景则为负样本。比较困难的是如何处理只包含局部车辆的图像块,作者的做法是选取和正样本IOU小于0.3的局部车辆图像块为负样本。0.3这个值也是作者在一个验证集上通过交叉验证从[0,0.1,…,0.5]中选取出来的。
根据前面设置的规则筛选出的样本,每类训练一个单独的SVM。使用了难例挖掘策略。
两个讨论:
-
为什么微调和SVM训练时设置正样本的策略不同?
微调时,和ground-truth之间大于0.5的proposal region设置为对应的正样本类。训练SVMs时,只有ground-truth box是正样本,和所以ground-truth之间IOU都小于0.3的图像块及背景图像块为负样本,和ground-truth之间IOU大于0.3的包含局部目标的图像块被忽视了。
之所以微调时设置规则更加宽松是为了增加正样本的数量,因为本来样本量就不太够,这也可以防止过拟合。当然这样宽松的规则引入了很多目标局部块进行训练,训练结果也不是最优的。
-
为什么使用多个线性SVM分类器而不使用Softmax分类?
fine-tuning时的输出为一个21类的softsoftmax分类器,其输出就是表示每一个proposal的类别概率值,为什么又要换成多个二分类的svm分类器进行分类呢?将最后的20个SVM分类器换成一个21输出的softmax,mAP性能有所下降。这个下降可能来自于微调过程中使用了大量只包含局部目标块的训练样本,但训练svm分类器时正例样本都是真正的正例样本,负例样本都是通过难例挖掘找的的最容易混淆的负例样本,因此训练出来的svm模型对样本类别的区分能力更强。
作者认为可以在微调过程中使用其他手段改善softmax的效果,这样就不需要再额外训练SVMs分类器,这样可以提升训练效率。
2.4 实验结果
在VOC2012训练集上微调和训练SVMs,在测试服务器上进行性能测试。
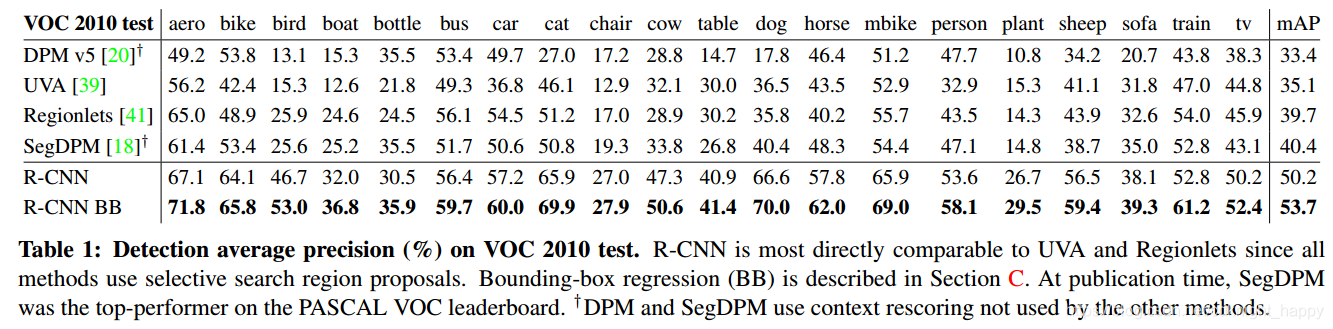 在ILSVRC2013上检测结果为:
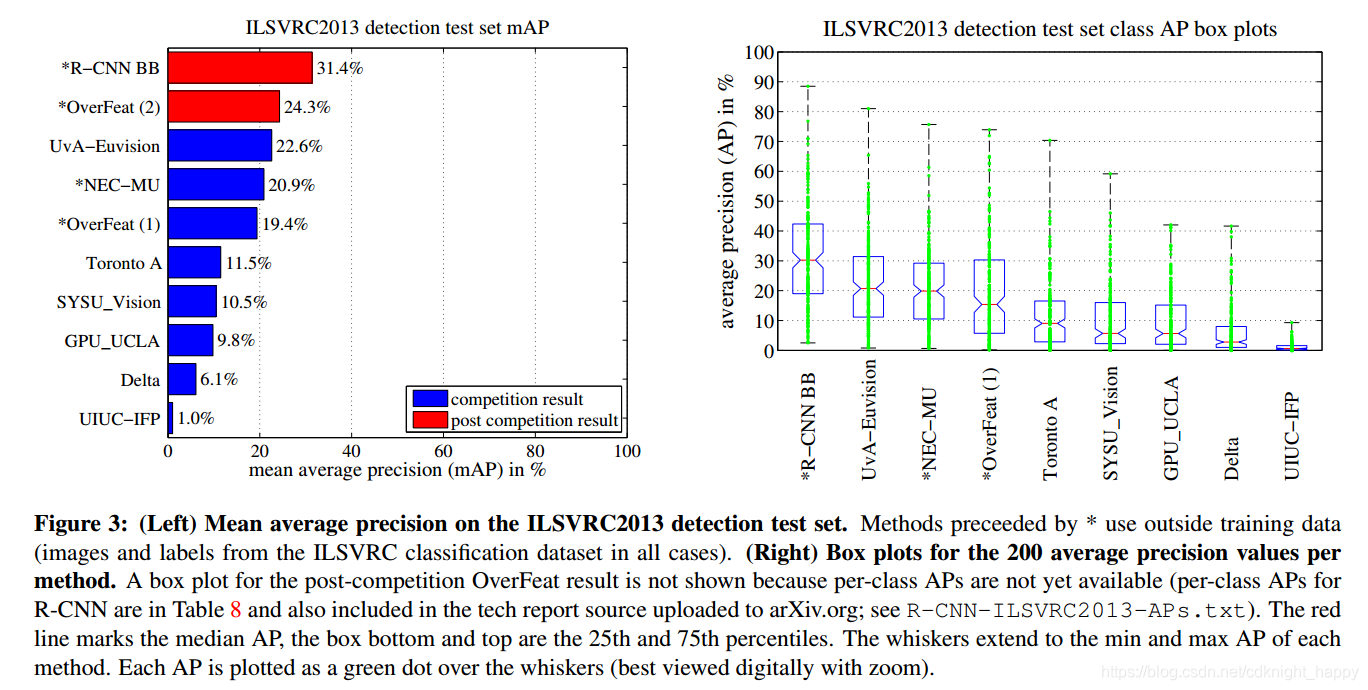
在ILSVRC2013上检测结果为:
3 可视化和误差分析
各层特征及微调影响分析:
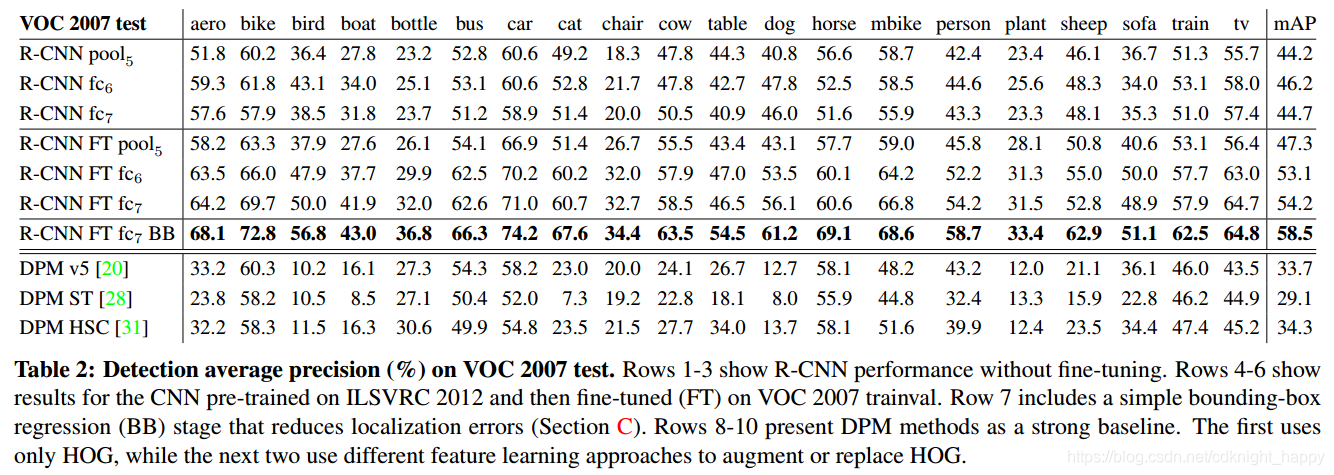 第1,2,3行表示直接用预训练模型的POOL5、FC6、FC7层的特征进行分类,可以看到FC6优于FC7,而直接使用POOL5带来的损失很小(但移除两个fc层大大减少了参数量),因此说明了CNN网络的判别能力主要来自于卷积层而不是全连接层。
第1,2,3行表示直接用预训练模型的POOL5、FC6、FC7层的特征进行分类,可以看到FC6优于FC7,而直接使用POOL5带来的损失很小(但移除两个fc层大大减少了参数量),因此说明了CNN网络的判别能力主要来自于卷积层而不是全连接层。
第4,5,6行是进行微调后的结果,和第1,2,3行对比可以发现,微调有助于性能提升;微调对FC6、FC7的提升幅度大于对POOL5的提升幅度,说明从ImageNet学习的POOL5层的特征具有通用性,微调带来的性能提升主要来自于对全连接层的针对指定任务的调整。
CNN相比于传统特征DPM,说明了CNN的有效。
网络结构的影响:
 把CNN网络从AlexNet换成VGGNet,带来了性能提升。证明了网络的重要性。
把CNN网络从AlexNet换成VGGNet,带来了性能提升。证明了网络的重要性。
4 Bounding-box regression
R-CNN的误差分析发现,其误差主要来源于定位精度不够。这是因为只是用selective search找到的proposal精度不够,因此作者在对每一个selective serach选取的proposal region应用svm分类之后,还基于CNN提取的特征对该region使用了一个新的bounding-box regressor来修正selective search提取的目标检测框。

如上图所示,P表示proposal的位置,G表示ground-truth box的位置,BBR的目的就是通过P对应区域的特征去学习P和G之间的偏差函数。
训练BB回归器:
-
数据集:N个训练对, { ( P i , G i ) i = 1 , ⋯ , N } \{(P^i,G^i)_{i=1,\cdots,N}\} {(Pi,Gi)i=1,⋯,N},其中 P i = ( P x i , P y i , P w i , P h i ) P^i = (P_x^i,P_y^i,P_w^i,P_h^i) Pi=(Pxi,Pyi,Pwi,Phi)为第i个proposal region的中心点及宽高。 G i = ( G x i , G y i , G w i , G h i ) G^i = (G_x^i,G_y^i,G_w^i,G_h^i) Gi=(Gxi,Gyi,Gwi,Ghi)为 P i P^i Pi所包含的目标的真实中心点位置及宽高信息;
-
训练时输入包含两项,一是proposal P的POOL5层特征 Φ 5 ( P ) \Phi_5(P) Φ5(P);二是要学习的真值 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h) (tx,ty,tw,th),表示proposal和ground-truth box之间的中心点偏差和对数域的宽高比;

-
w ∗ w_* w∗为要学习的权重向量,有 d ∗ ( P ) = w ∗ T Φ 5 ( P ) d_{*}(P) = w^T_*\Phi _5(P) d∗(P)=w∗TΦ5(P),四个线性函数 d x ( P ) 、 d y ( P ) 、 d w ( P ) 、 d h ( P ) d_x(P)、d_y(P)、d_w(P)、d_h(P) dx(P)、dy(P)、dw(P)、dh(P),前两个表示P相对G的中心点的平移,后两个表示P相对于G在对数域的宽高比值;
-
训练过程形式化表示:

即学习的权重向量和输入数据的乘积表示的是proposal region和真值之间的相对差距。 -
训练完成后,学习了权重系数 w ∗ w_* w∗,对的proposal P进行预测时,根据P的POOL5层特征和 w ∗ w_* w∗得到 d ∗ ( P ) = w ∗ T Φ 5 ( P ) d_{*}(P) = w^T_*\Phi _5(P) d∗(P)=w∗TΦ5(P), d ∗ ( P ) 包 括 d x ( P ) 、 d y ( P ) 、 d w ( P ) 、 d h ( P ) d_{*}(P)包括d_x(P)、d_y(P)、d_w(P)、d_h(P) d∗(P)包括dx(P)、dy(P)、dw(P)、dh(P)四项,对于P,应用下面的变换过程得到预测的目标位置 G ^ \hat G G^:

作者在训练该回归器的过程中发现正则化非常重要,因此设置
λ
=
1000
\lambda = 1000
λ=1000;二是,(P,G)对必须慎重选择,如果P和G差距很大和很小,则训练意义不大,必须使用差距不太大又不太小的(P,G)对进行训练,作者的实现是若某个proposal P和某个ground-truth G之间的IOU最大且IOU值大于0.6则将这样的P、G组队进行BB的训练。
图片内容摘抄自:https://blog.youkuaiyun.com/zijin0802034/article/details/77685438

作者是针对每个类别训练了一个BB回归器。
Bounding-box 回归有助于减小检测框定位误差,将mAP提升了3到4个点。
下面内容摘抄自:https://blog.youkuaiyun.com/zijin0802034/article/details/77685438
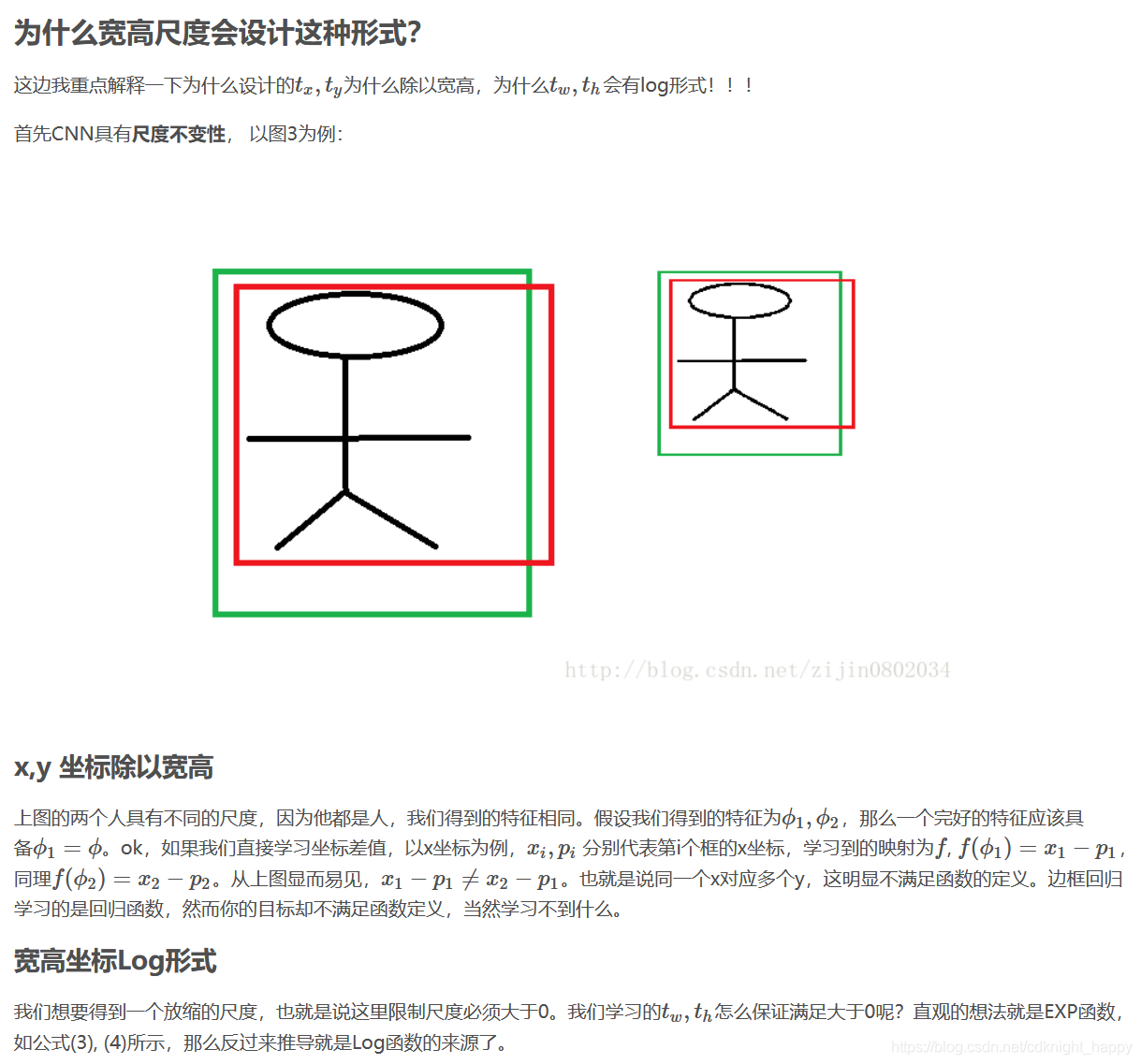
标注数据时,为什么中心点的差值除以了宽高,宽高信息又取了对数?
5 总结
selective search提取proposal + CNN提取特征 + SVMs分类 + Bounding box回归,取得了当时非常好的检测和分割效果;
说明了充分数据上的预训练和特定领域少量数据微调可以在该特定领域取得良好的效果;
深度学习必将在计算机视觉领域取得良好的发展。
虽然现在目标检测的性能在本文的基础上提升很大,但本文第一次使用CNN来解决检测问题,虽过程略繁琐,时间效率不高,但对使用CNN解决目标检测问题起到了奠基作用。另外作者的很多实验思路值得学习。
才疏学浅,若有错误,欢迎批评指正!

















 8891
8891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









